Вы отправили слишком много запросов, поэтому ваш компьютер был заблокирован.
Для того, чтобы предотвратить автоматическое считывание информации с нашего сервиса, на Linguee допустимо лишь ограниченное количество запросов на каждого пользователя.
Пользователям, браузер которых поддерживает Javascript, доступно большее количество запросов, в отличие от пользователей, чей браузер не поддерживает Javascript. Попробуйте активировать Javascript в настройках вашего браузера, подождать несколько часов и снова воспользоваться нашим сервером.
Если же ваш компьютер является частью сети компьютеров, в которой большое количество пользователей одновременно пользуется Linguee,сообщитеоб этом нам.
Перевод «uplift» на русский
Wind pressures are also responsible for uplift on roofing assemblies and wind driven rain that can penetrate unprotected areas.
Давление ветра также несет ответственность за подъем на кровельных сборках и ветровых дождях, которые могут проникать в незащищенные районы.
It’s a wonderful course if you want to experience camaraderie, history, and emotional uplift.
Это прекрасный курс, если вы хотите испытать дух товарищества, историю и эмоциональный подъем.
Large craters have a large central uplift.
Крупные кратеры имеют большое центральное поднятие.
In any case, this uplift allowed the formation of a vast flat zone several thousand meters high.
Как бы там ни было, это поднятие позволило сформировать достаточно ровный участок поверхности, высотой в несколько тысяч метров.
In his early life, education and personal uplift had ended in disillusionment; now Ambedkar saw the limits of political change.
Ранее в его жизни образование и личное возвышение закончились разочарованием, теперь Амбедкар увидел ограничения политических изменений.
Many believe that good weather accompanies a spiritual uplift, and the rain plunges us into depression.
Многие верят, что хорошая погода сопутствует душевному подъему, а дождь погружает нас в депрессию.
To raise standards of living of marginalized rural communities by providing them with opportunities for social and economic uplift.
Повысить уровень жизни находящихся в неблагоприятном положении сельских общин путем создания возможностей для их социального и экономического подъема.
Mountains are topographic features caused by erosion after vertical uplift or ‘mountain building.
Горы — это рельеф, созданный эрозией после вертикального поднятия или «горообразования».
Jamaica was formed by uplift associated with a restraining bend along this strike-slip structure.
Ямайка была образована поднятием, связанным со сдерживающим изгибом вдоль данной структуры.
The history is dominated by east-west compression of predominantly oceanic sedimentary and igneous rocks and their resultant folding, faulting and uplift.
В истории преобладает сжатие с востока на запад преимущественно океанических осадочных и магматических пород и их результирующие складки, разломы и поднятия.
The uplift increased the steepness of stream and river beds, resulting in the formation of deep, narrow canyons.
Подъём увеличил крутизну водных потоков и русла рек, в результате образовав глубокие и узкие каньоны.
Therefore, storm surges will become higher in the future, even if the land uplift rate remains stable.
Таким образом, штормовые волны в будущем станут выше, даже если поднятие уровня суши останется стабильным.
The coastline of Kent is continuously changing, due to tectonic uplift and coastal erosion.
Береговая линия подвержена со временем сильным изменениям из-за тектонических поднятий и береговой эрозии.
We applaud King for using her platform to uplift her community and promote honesty.
Мы приветствуем короля за использование ее платформы для поднятия своей общины и поощрять честность.
For all the time of the Soviet era, there has never been such a youthful uplift and inspiration.
За все время советской эпохи ни разу больше не было такого молодежного подъема и вдохновения.
The inner island called René-Levasseur Island, is actually the central peak of the crater, formed by post-impact uplift.
Внутренний остров, называемый островом Рене-Левассер, на самом деле является центральной вершиной кратера, образованной в результате постударного поднятия.
The Carnegie Ridge is sliding under Ecuadorian land, causing coastal uplift and volcanism.
Хребет Карнеги Ридж движется под территорией Эквадора, вызывая поднятие прибрежных районов.
The unpaved state road MT-306, between Ponte Branca and Araguainha, cuts across the central uplift.
Грунтовая дорога MT-306 между населёнными пунктами Понти-Бранка и Арагуаинья пересекает центральное поднятие.
One important factor affecting storm surges is post-glacial land uplift. Until now, the land uplift rate has been higher than sea level rise, increasing the land surface in coastal areas.
Одним из важных факторов, оказывающих влияние на образование штормовых волн, является послеледниковое поднятие суши. До сих пор уровень поднятия суши был выше подъема уровня моря, что привело к увеличению площади земной поверхности, не покрытой водой, в прибрежных зонах.
Туториал по uplift моделированию: метрики. Часть 3

В предыдущих туториалах (часть 1, часть 2) мы изучали методы, моделирующие uplift. Это величина, которая оценивает размер влияния на клиента, если мы взаимодействуем с ним. Например, отправляем смс или пуш уведомление. Давайте обсудим: как измерять качество uplift моделей?
- часть 1: математический смысл, сбор обучающей выборки, uplift модели
- часть 2: uplift модели (продолжение)
- часть 3: uplift метрики
Использовать классические метрики качества для оценки обученной модели не получится, так как нет ground truth по каждому объекту выборки или реальных, настоящих значений uplift. Это значит, что если мы предскажем значение, сравнить его будет не с чем. В этом заключается особенность uplift моделирования: нельзя одновременно прокоммуницировать и не прокоммуницировать с клиентом и посмотреть разницу в его реакции. Поэтому все метрики мы будем рассчитывать, так или иначе группируя объекты выборки. Например, рассматривая 10% выборки, 20% и так далее.
Давайте на реальном датасете обучим простую модель, предскажем uplift и посмотрим, какие есть метрики и как они себя ведут. Все примеры кода из статьи есть в ноутбуке. В нем используется питоновская библиотека для uplift моделирования sklift, созданная авторами статьи.
Для примера возьмем датасет от Ленты. Датасет был представлен на хакатоне BigTarget от Ленты и Microsoft летом 2020 года и теперь доступен для скачивания. В нем собраны обезличенные и аггрегированные данные о поведении клиентов супермаркетов до проведения акции на определенную группу товаров. Есть данные о факте взаимодействия с клиентом и факты совершения целевого действия после коммуникации.
Более детально на данные можно посмотреть в документации и ноутбуке.
Метрики
uplift@k
Самая простая и понятная метрика — размер uplift на топ k процентах выборки.
Например, с помощью обученной uplift модели мы хотим отобрать какое-то количество клиентов, с которыми будем коммуницировать. Пусть бюджет рассчитан на k% клиентов. Тогда нам интересно оценить качество прогноза не на всей тестовой выборке, а только на объектах с наибольшими предсказаниями при отсечении по порогу в k процентов.
Для расчета uplift@k нужно отсортировать выборку по величине предсказанного uplift и посмотреть разницу средних значений таргета Y (в англоязычных статьях использую термин response rate, мы его тоже будем использовать в дальнейшем) в целевой и контрольной группах. Целевая группа — группа, которая получила коммуникацию. Контрольная группа — которая не получила.
Теоретический uplift@k принимает значения от -1 (когда в целевой группе нет реакций Y=1 , а в контрольной группе все клиенты имеют реакцию Y=1 ) и может достигать величины 1 (противоположная ситуация: в целевой группе все клиенты откликнулись: Y=1 , в то время как в контрольной — ни одного случая с Y=1 ).
На практике uplift@k принимает значения от 0 до 1, в зависимости от выбранного значения k, особенностей датасета и качества модели.
Рассчитывать эту метрику можно двумя различными способами: сначала сортировать по предсказанному uplift и далее считать разницу response rate двух групп. Или наоборот, изначально сортировать объекты из контрольной и целевой групп по отдельности.
Обучим простую uplift модель и предскажем величину uplift на валидации
Подробности в этом ноутбуке
# y_val - столбец таргета на валидации # trmnt_val - столбец флага коммуникации на валидации # uplift_ct - предсказанный uplift методом ClassTransformation на валидацииТогда метрику uplift@k можно импортировать и посчитать таким образом:
from sklift.metrics import uplift_at_k # k = 10% k = 0.1 # strategy='overall' sort by uplift treatment and control together uplift_overall = uplift_at_k(y_val, uplift_ct, trmnt_val, strategy='overall', k=k) # strategy='by_group' sort by uplift treatment and control separately uplift_bygroup = uplift_at_k(y_val, uplift_ct, trmnt_val, strategy='by_group', k=k) print(f"uplift@%: " f"(sort groups by uplift together)") print(f"uplift@%: " f"(sort groups by uplift separately)")uplift@10%: 0.1484 (sort groups by uplift together) uplift@10%: 0.1521 (sort groups by uplift separately)Uplift by percentile
Бывает так, что со стороны бизнеса не известно значение порога k и хочется посмотреть, как будет вести себя метрика при разных значениях порога k. Такая метрика в литературе [1] упоминается как uplift by decile. Также ее называют uplift by percentile или uplift by bin.
При построении действуем по аналогии с uplift@k:
- Сортируем по предсказанному значению uplift
- Делим отсортированные данные на перцентили / децили / бины .
- В каждом перцентиле отдельно оцениваем uplift как разность между средними значениями целевой переменной в тестовой и контрольной группах.
Стоит отметить, что в большинстве источников [1] [2] аплифт по перцентилям оценивается независимо в каждом перцентиле, но ничего не мешает вам оценить его кумулятивно.
Результатом этой метрики, как правило, является таблица [3] или ее визуальное представление в виде графика. Давайте также для каждого перцентиля рассчитаем следующие показатели:
- n_treatment — размер целевой (или treatment) группы
- n_control — размер контрольной (control) группы
- response_rate_treatment — среднее значение таргета целевой группы
- response_rate_control — среднее значение таргета контрольной группы
- uplift = response_rate_treatment — response_rate_control
Дополнительно добавим расчет среднеквадратичного отклонения для каждой метрики ( std_treatment , std_control , std_uplift ) для того, чтобы оценивать разброс метрики в каждом перцентиле (формулы вы найдете ниже).
С помощью кода ниже можно рассчитать таблицу uplift by percentile. Кроме метрик по каждому перцентилю в последней строке total расположены итоговые метрики для всей выборки.
from sklift.metrics import uplift_by_percentile uplift_by_percentile(y_val, uplift_ct, trmnt_val, strategy='overall', total=True, std=True, bins=10)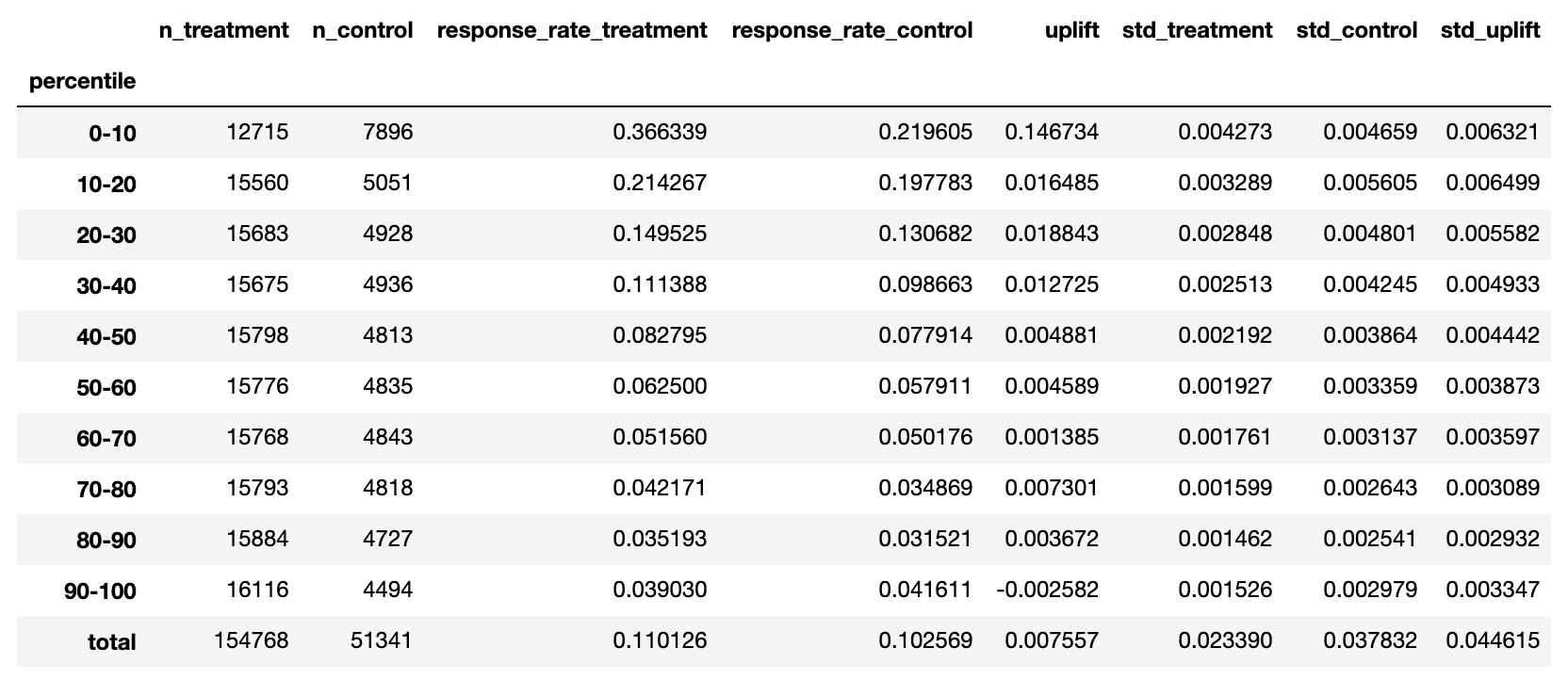
График uplift by percentile
Если визуализировать таблицу, то получится график uplift by percentile. По нему удобно оценивать эффективность модели. Как его можно интерпретировать? Так как коммуникация будет проводиться с клиентами, получившими наибольшую оценку uplift, то слева на графике должны быть максимальные по модулю положительные значения uplift и в следующих перцентилях значения уменьшаются.
Для отрисовки можно использовать bar plot. Для удобства отобразим две графика. На верхнем нарисуем uplift , а на нижнем — соответствующий response rate в тестовой и контрольной группах, разница которых и является оценкой uplift .
Код построения plot_uplift_by_percentile
from sklift.viz import plot_uplift_by_percentile plot_uplift_by_percentile(y_val, uplift_ct, trmnt_val, strategy='overall', kind='bar');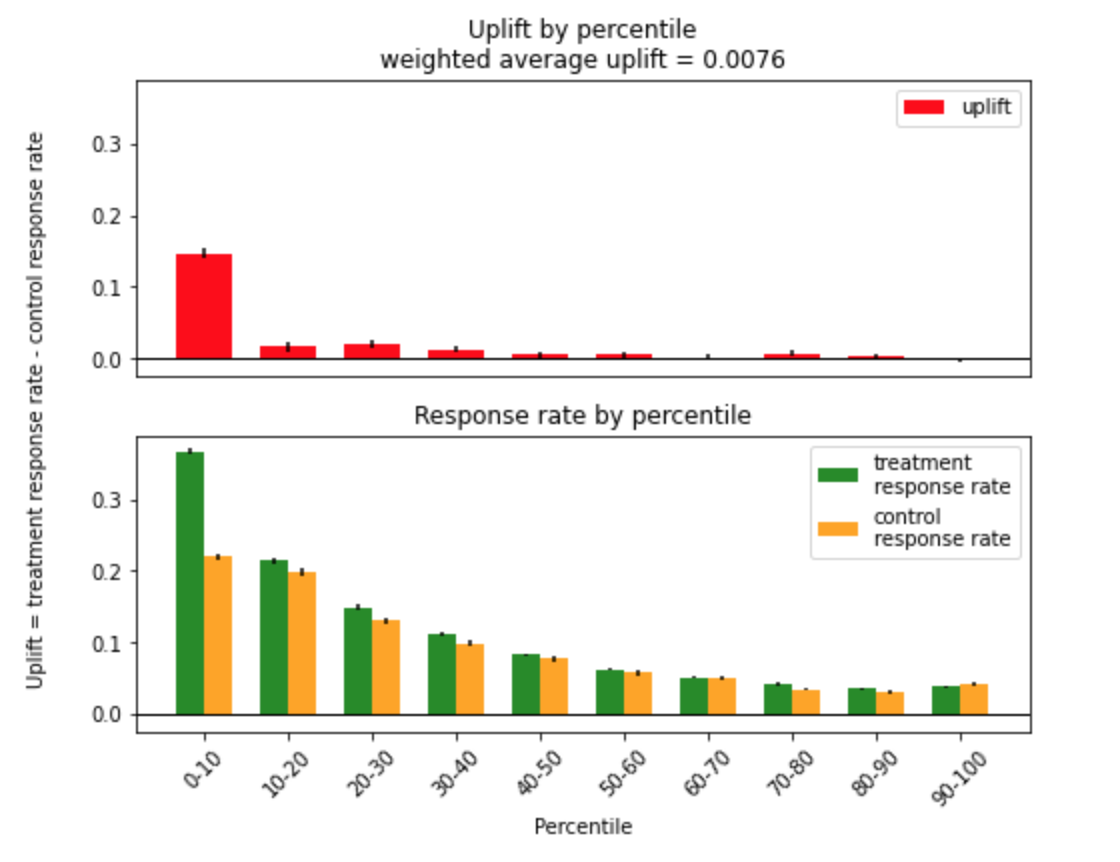
Тогда на графике response rate для целевой и контрольной группы (нижний bar plot) доля реакций клиентов Y = 1 из целевой группы (зеленый цвет) должна быть максимально большой в первых перцентилях и потом убывать. А доля Y = 1 контрольной группы (желтый цвет) — минимальной в первых перцентилях и затем, в идеале, возрастать. Чем больше в первых перцентилях разница двух response rate, тем больше uplift (красный цвет), а значит, тем лучше модель находит клиентов, которые положительно откликаются на коммуникацию.
Если вспомнить разделение по типам клиентов из первого туториала, то в левой части графика как раз находятся убеждаемые — тот тип, которых мы хотим найти. В терминах целевого действия и коммуникации это Y=1 при W=1 или Y=0 при W=0.
На графике могут быть и отрицательные значения uplift. Нетрудно понять, что это случится в том перцентиле, в котором response rate в контрольной группе больше, чем в целевой. Это значит, что коммуникация с этой группой имела негативный эффект и модель нашла тип клиентов, которые негативно реагируют на коммуникацию — тип не беспокоить, Y=0 при W=1, Y=1 при W=0.
Для случайной аплифт модели график uplift by percentile будет выглядеть как линия, параллельная оси Х.

На графике между типом убеждаемые в левой части и типом не-беспокоить в правой части лежат два оставшихся типа, которые модель не различает между собой: лояльные и потерянные. Если в выборке их количество будет одинаково, то uplift, равный нулю, должен быть посередине, так как их response rate уравновесит друг друга. Это произойдет потому, что лояльные всегда реагируют и выполняют целевое действие Y=1 , а потерянные — наоборот, никогда этого не сделают Y=0 .
Uplift по перцентилям можно визуализировать не только как bar plot, но и как line plot:
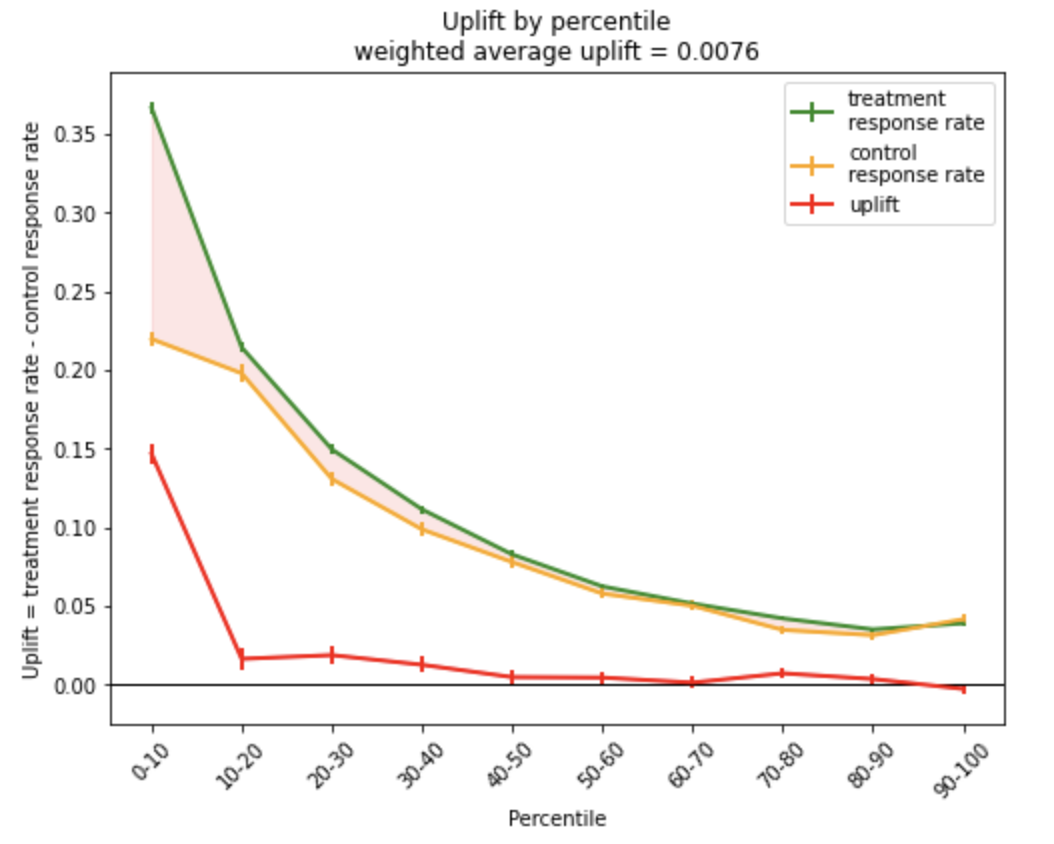
На обоих типах графиков показаны не только значение uplift в каждой точке, но стандартные отклонения. Это сделано для того, чтобы корректно сравнивать метрики от перцентиля к перцентилю с учетом их разброса.
Выведем формулу стандартного отклонения
Чтобы найти стандартное отклонение, вычислим дисперсию и потом возьмем из нее корень:
и бинарный таргет распределен по закону Бернулли, получаем
Weighted average uplift
Часто хочется иметь метрику, посчитанную в виде единого значения на всей тестовой выборке. Для этого опять пригодится таблица uplift by percentile. Давайте с помощью значений в столбцах uplift и n_treatment рассчитаем усредненный uplift на всей выборке, взвешенный на размер целевой группы — weighted average uplift [3].
Формула weighted average uplift
from sklift.metrics import weighted_average_uplift uplift_full_data = weighted_average_uplift(y_val, uplift_ct, trmnt_val, bins=10) print(f"weighted average uplift on full data: ")weighted average uplift on full data: 0.0189Weighted average uplift лежит в пределах от [-1, 1] и отображается на графике uplift by percentile в названии. Если метрика принимает значение 1, это значит, что реакций Y=1 в контрольной группе нет ни в одном перцентиле: пользователи никогда не выполняют целевое действие самостоятельно, а только при коммуникации. При таком значении метрики нет смысла решать задачу с помощью uplift моделирования, лучше свести постановку задачи к обучению response или look-alike модели.
Значение метрики может доходить до граничного значения -1. Это будет означать, что во всех перцентилях uplft был равен -1. Такое происходит, когда в целевой группе нет реакций Y=1 , а в контрольной группе все клиенты имеют реакцию Y=1 . Получается, что значения метрики, которые нас устраивают в рамках решения uplift задачи, лежат в пределах [0, 1) .
Uplift curve
Uplift кривая строится как функция от количества объектов, нарастающим итогом. В каждой точке кривой можно увидеть накопленный к этому моменту uplift
Формула uplift curve
На картинке ниже расположен типичный график идеальной (красным), модельной, или реальной (синим) и случайной (черным) кривых. Каждая точка на такой кривой соответствует значению кумулятивного uplift. Чем больше это значение, тем лучше. Монотонно возрастающая случайная кривая показывает, что воздействие всей выборки имеет общий положительный эффект.
Код отрисовки uplift curve
from sklift.viz import plot_uplift_curve # with ideal curve # perfect=True plot_uplift_curve(y_val, uplift_ct, trmnt_val, perfect=True);
Колоколообразная форма кривых показывает сильные положительные и отрицательные эффекты, присутствующие в наборе данных. Если бы эти эффекты отсутствовали, кривые были бы ближе к случайной линии.
Как выглядит кривая uplift без отрисовки идеальной кривой
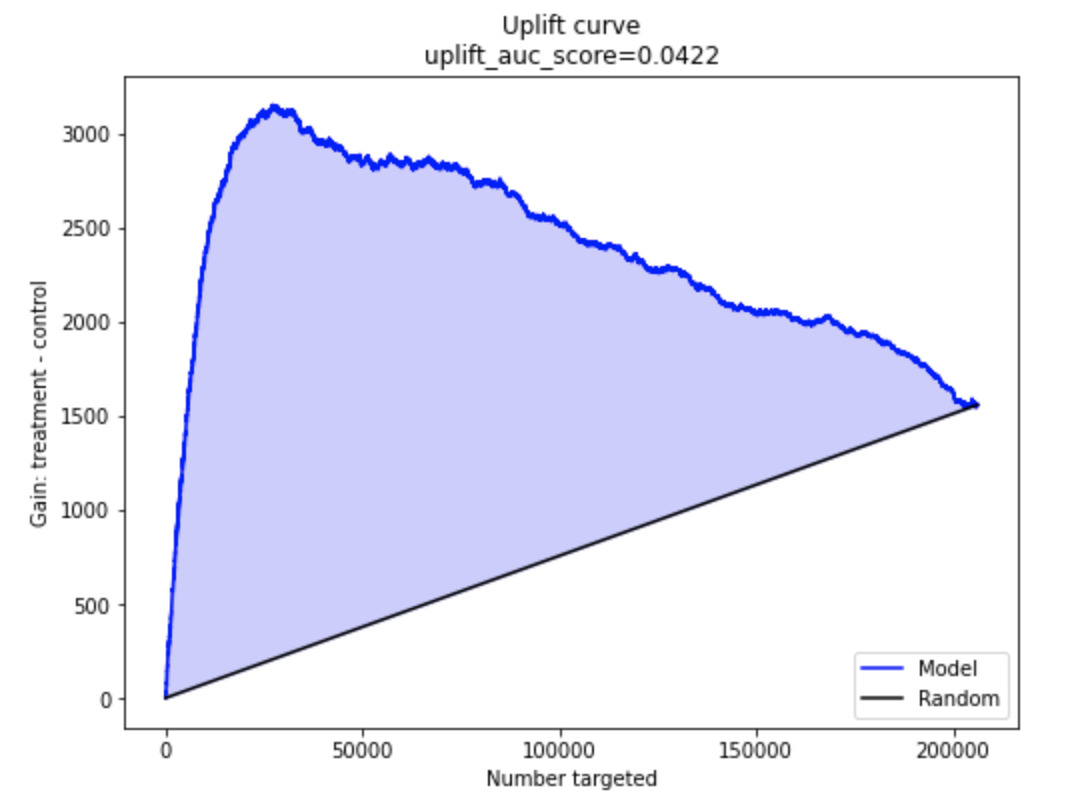
Qini curve
Еще одной довольно распространенной кривой при оценке uplift моделей является Qini кривая, впервые введенная в статье [4] и определяющаяся следующим образом:
Формула qini curve
Qini curve, как и другие аплифт метрики, рассчитывается кумулятивно сразу для набора объектов. Кривую Qini для модели тоже сравнивают со случайной кривой (на графике черной линией) и с идеальным случаем (на графике красной линией). Аналогично с uplift кривой, чем выше кривая над случайной кривой, тем лучше.
Код отрисовки qini curve
from sklift.viz import plot_qini_curve # with ideal Qini curve (red line) # perfect=True plot_qini_curve(y_val, uplift_ct, trmnt_val, perfect=True);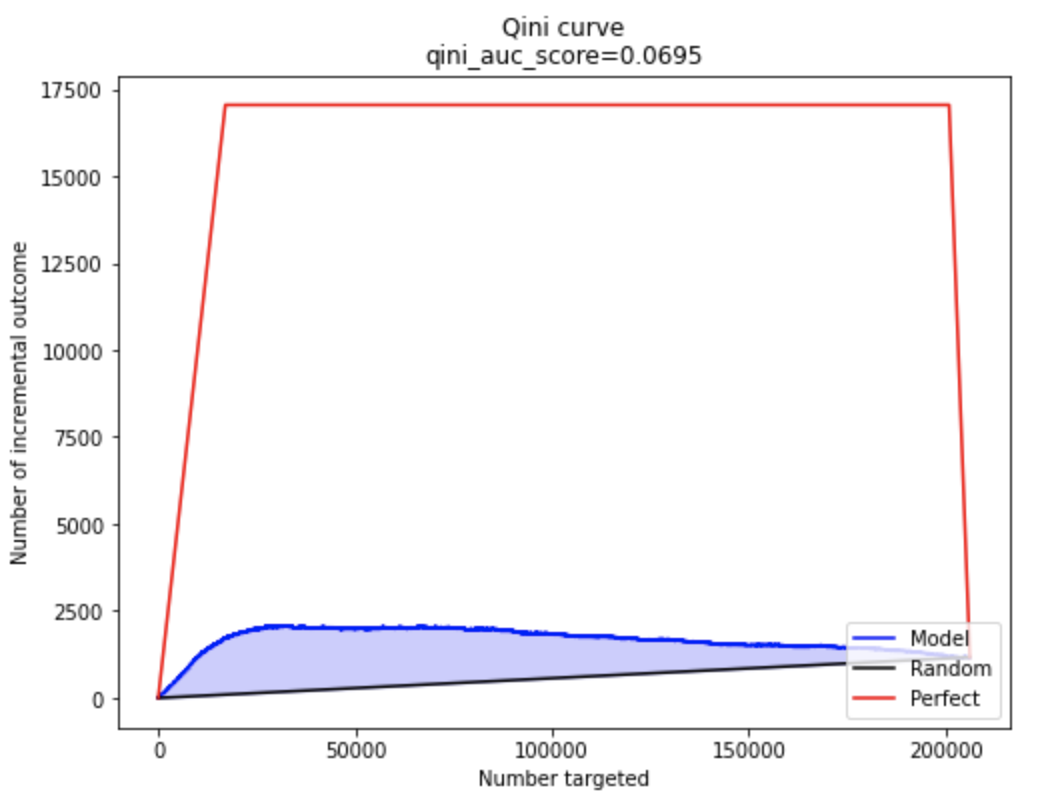
Физический смысл qini кривой в том, чтобы не давать модели поднимать наверх в ранжировании только целевую (treatment) группу, штрафуя ее за это множителем Nt/Nc, который уменьшает итоговое значение, если Nt сильно больше, чем Nc.
Можно провести очевидную параллель между uplift и qini кривыми:
Например, когда контрольная и целевая группы сбалансированы, то qini кривая будет в два раза ниже, чем uplift.
Qini curve без идеальной кривой

От кривых к числам
Итак, теперь мы знаем, как строить qini и uplift кривые, с помощью которых можно оценить качество модели. При этом сравнивать модели хочется не «на глаз», а с помощью чисел. Как и во многих других метриках машинного обучения, основанных на кривых, предлагается рассчитывать площадь под модельными кривыми и нормировать ее на площадь под идеальной кривой [5]. При этом обычно из площадей под модельной и идеальной кривыми вычитают площадь под случайной кривой, которую называют baseline.
Qini coefficient или AUQC
В случае площади под qini кривой можно посчитать коэффициент qini, или area under qini curve (AUQC). Схематично его расчет можно нарисовать так:

Код qini_auc_score
from sklift.metrics import qini_auc_score # AUQC = area under Qini curve = Qini coefficient auqc = qini_auc_score(y_val, uplift_ct, trmnt_val) print(f"Qini coefficient on full data: ")Qini coefficient on full data: 0.0695Area under uplift curve, AUUQ
Для uplift кривой коэффициент называется AUUQ — area under uplift curve и считается аналогичным образом.
from sklift.metrics import uplift_auc_score # AUUQ = area under uplift curve auuc = uplift_auc_score(y_val, uplift_ct, trmnt_val) print(f"Uplift auc score on full data: ")Uplift auc score on full data: 0.0422Как вы могли заметить, коэффициенты AUQC и AUUC также отображаются на графиках кривых в названии графиков.
Заключение
Целью наших статей (часть 1, часть 2, часть 3) был рассказ об основах uplift моделирования и кейсах его применения. Мы подробно разобрали не только основные методы и метрики, но и дизайн эксперимента для сбора обучающей выборки. Первые части были без кода, поэтому рекомендуем посмотреть практические туториалы здесь.
Мы надеемся, что они дадут базовые знания и возможность самостоятельно углубиться дальше в исследования. Например, на практике вы можете столкнуться с несколькими вариантами коммуникаций или предсказанием непрерывной целевой переменной. В этом вам помогут ссылки на источники.
Статья написана в соавторстве с Максимом Шевченко @maks-sh
Источники
[1] Pierre Gutierrez, Jean-Yves Gérardy. Causal Inference and Uplift Modeling A review of the literature. JMLR: Workshop and Conference Proceedings 67:1–13, 2016
[2] Verbeke, Wouter & Baesens, Bart & Bravo, Cristián. Profit Driven Business Analytics: A Practitioner’s Guide to Transforming Big Data into Added Value, 2018.
[3] René Michel, Igor Schnakenburg, Tobias von Martens. Targeting Uplift. An Introduction to Net Scores. Springer, 2019.
[4] Nicholas J. Radcliffe. Using control groups to target on predicted lift: Building and assessing uplift model. Direct Market J Direct Market Assoc Anal Council, 1:14–21, 2007.
[5] Floris Devriendt, Tias Guns, Wouter Verbeke. Learning to rank for uplift modeling. IEEE Transactions on Knowledge and Data Engineering, 2020
- Блог компании МТС
- Data Mining
- Математика
- Машинное обучение
- Искусственный интеллект
Туториал по uplift моделированию. Часть 1

Команда Big Data МТС активно извлекает знания из имеющихся данных и решает большое количество задач для бизнеса. Один из типов задач машинного обучения, с которыми мы сталкиваемся – это задачи моделирования uplift. С помощью этого подхода оценивается эффект от коммуникации с клиентами и выбирается группа, которая наиболее подвержена влиянию.
Такой класс задач прост в реализации, но не получил большого распространения в литературе про машинное обучение. Небольшой цикл статей, подготовленный Ириной Елисовой (iraelisova) и Максимом Шевченко (maks-sh), можно рассматривать как руководство к решению таких задач. В рамках него мы познакомимся с uplift моделями, рассмотрим, чем они отличаются от других подходов, и разберем их реализации.
Все туториалы серии
Содержание статьи
Введение
Обычно продвижение продуктов происходит за счет коммуникации с клиентом через различные каналы: смс, push, сообщения чат-бота в социальных сетях и многие другие. Формирование сегментов для продвижения сейчас решается с помощью машинного обучения несколькими способами:

- Look-alike модель оценивает вероятность того, что клиент выполнит целевое действие. В качестве обучающей выборки используются известные позитивные объекты (например, пользователи, установившие приложение) и случайные негативные объекты (сэмплирование небольшой подвыборки из всех остальных клиентов, у кого это приложение не было установлено). Модель будет пытаться искать клиентов, похожих на тех, кто совершил целевое действие.
- Response модель оценивает вероятность того, что клиент выполнит целевое действие при условии коммуникации. В этом случае обучающей выборкой являются данные, собранные после некоторого взаимодействия с клиентами. В отличии от первого подхода в нашем распоряжении имеются реальные позитивные и негативные наблюдения (например, клиент оформил кредитную карту или отказался).
- Uplift модель оценивает чистый эффект от коммуникации, пытаясь выбрать только тех клиентов, которые совершат целевое действие только при нашем взаимодействии. Модель оценивает разницу в поведении клиента при наличии воздействия и при его отсутствии.
Нельзя просто взять и обучить модель
Для оптимизации эффекта от воздействия хочется посчитать разницу реакций человека при наличии коммуникации и при ее отсутствии. Проблема в том, что мы не можем одновременно совершить коммуникацию (например, послать смс) и не совершить коммуникацию (не послать смс). Обозначим дельту потенциальных реакций -ого человека как . Эта величина называется causal effect:
где – потенциальная реакция человека, если с ним была коммуникация,
– потенциальная реакция человека, если коммуникации не было.

Зная признаковое описание -го объекта , можно ввести условный усредненный эффект от воздействия CATE (Conditional Average Treatment Effect):
Ни causal effect , ни для -го объекта мы наблюдать, и, соответственно, оптимизировать не можем. Поэтому перейдем к оценке или формуле uplift конкретного объекта:
Где — наблюдаемая реакция клиента в результате маркетинговой кампании, которая определяется следующим образом:
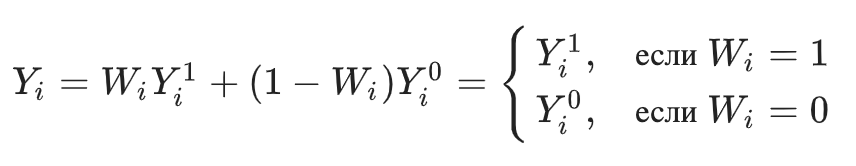
Где – флаг того, что объект попал в целевую (treatment) группу, где была коммуникация, – флаг того, что объект попал в контрольную (control) группу, где коммуникации не было.
Стоит отметить, что формула для uplift применима только при следующем предположении об условной независимости (Conditional Independence Assumption — CIA): разделение на целевую и контрольную группу происходит случайно, а не в зависимости от значения какого-то признака. Потенциальная реакция объекта — это только следствие характеристик этого объекта (например, установка приложения по аренде квартир зависит от возраста и города проживания), которое проявляется до того, как он попадет в какую-либо группу (целевую или контрольную). Кратко это можно записать как:
При этом наблюдаемая реакция объекта уже зависит от разделения на целевую и контрольную группу, как следует из определения.
Дизайн эксперимента
Итак, нам нужно оценить разницу между двумя событиями, которые являются взаимоисключающими для конкретного клиента (либо мы коммуницируем с человеком, либо нет; нельзя одновременно совершить два этих действия). Именно поэтому для построения моделей uplift предъявляются дополнительные требования к исходным данным.
Для получения обучающей выборки для моделирования uplift необходимо провести эксперимент:
- Случайным образом разбить репрезентативную часть клиентской базы на целевую и контрольную группы;
- Запустить пилот маркетинговой кампании на целевую группу.
Собранные данные об откликах на маркетинговое предложение, полученные в рамках такого эксперимента, позволят нам в дальнейшем построить модель прогнозирования uplift.
Перед проведением основной кампании рекомендуется аналогично эксперименту случайным образом выбрать небольшую часть клиентской базы и разбить ее на контрольную и целевую группы. С помощью этих данных можно будет не только адекватно оценить эффективность кампании, но и собрать дополнительные данные для дальнейшего переобучения модели.
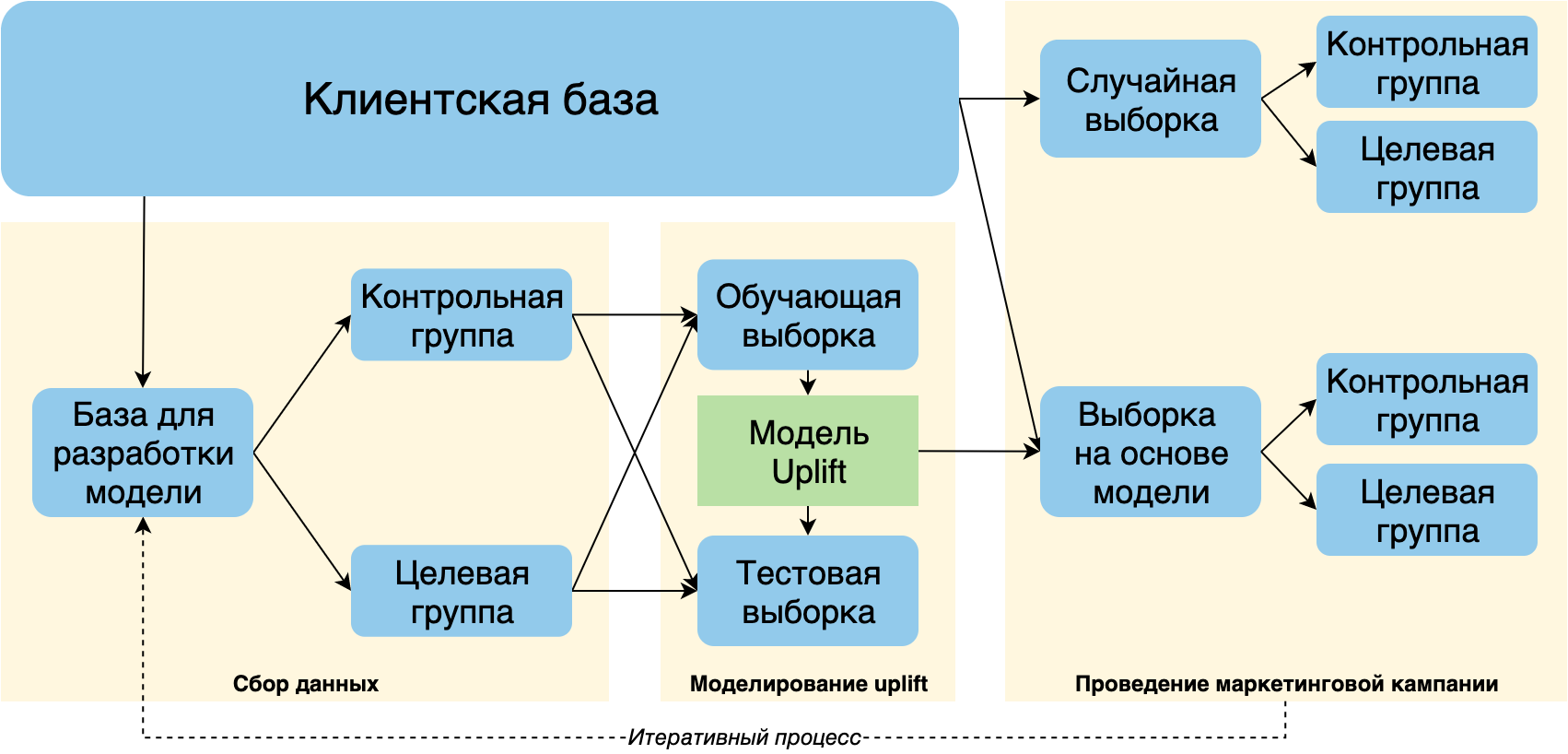
Схема взята и адаптирована из [1]
Кроме того, рекомендуется настраивать разработку uplift модели и запуск кампании как итеративный процесс: на каждой итерации будут собираться новые обучающие данные об откликах, которые состоят из комбинирования случайной подвыборки клиентов и клиентов, выбранных моделью.
Результаты воздействия на клиентов, выбранных моделью, не хотелось бы использовать в качестве обучающей выборки, так как клиенты были взяты не случайным образом. Однако эти данные представляют большую ценность, поэтому их следует изучить и использовать для дальнейшего совершенствования модели и увеличения отклика от будущих кампаний.
Типы клиентов
Принято выделять 4 типа клиентов по реакции на коммуникацию:

- Не беспокоить (Do-Not-Disturbs) — человек, который будет реагировать негативно, если с ним прокоммуницировать.
- Потерянный (Lost Causes) — человек, который никогда не совершит целевое действие, вне зависимости от коммуникаций. Взаимодействие с такими клиентами не приносит дополнительного дохода, но создает дополнительные затраты.
- Лояльный (Sure Things) — человек, который будет реагировать положительно, несмотря ни на что. Это самый лояльный вид клиентов. По аналогии с предыдущим пунктом, такие клиенты также расходуют бюджет.
- Убеждаемый (Persuadables) — это человек, который положительно реагирует на предложение, но при его отсутствии не выполнил бы целевого действия. Это те люди, которых мы хотели бы определить нашей моделью, чтобы с ними прокоммуницировать.
Таким образом, предсказывая uplift и выбирая топ предсказаний, мы хотим найти только один из четырех типов — убеждаемый. Есть несколько способов это сделать.
Одна модель с признаком коммуникации
Treatment Dummy approach, Solo model approach, Single model approach, S-Learner
Самое простое и интуитивное решение: модель обучается одновременно на двух группах, при этом бинарный флаг коммуникации выступает в качестве дополнительного признака. Каждый объект из тестовой выборки скорим дважды: с флагом коммуникации равным 1 и равным 0. Вычитая вероятности по каждому наблюдению, получим искомый uplift.

В некоторых статьях, например [2], предлагается увеличить количество признаков вдвое, добавив произведение каждого признака на флаг взаимодействия: :

Две независимые модели
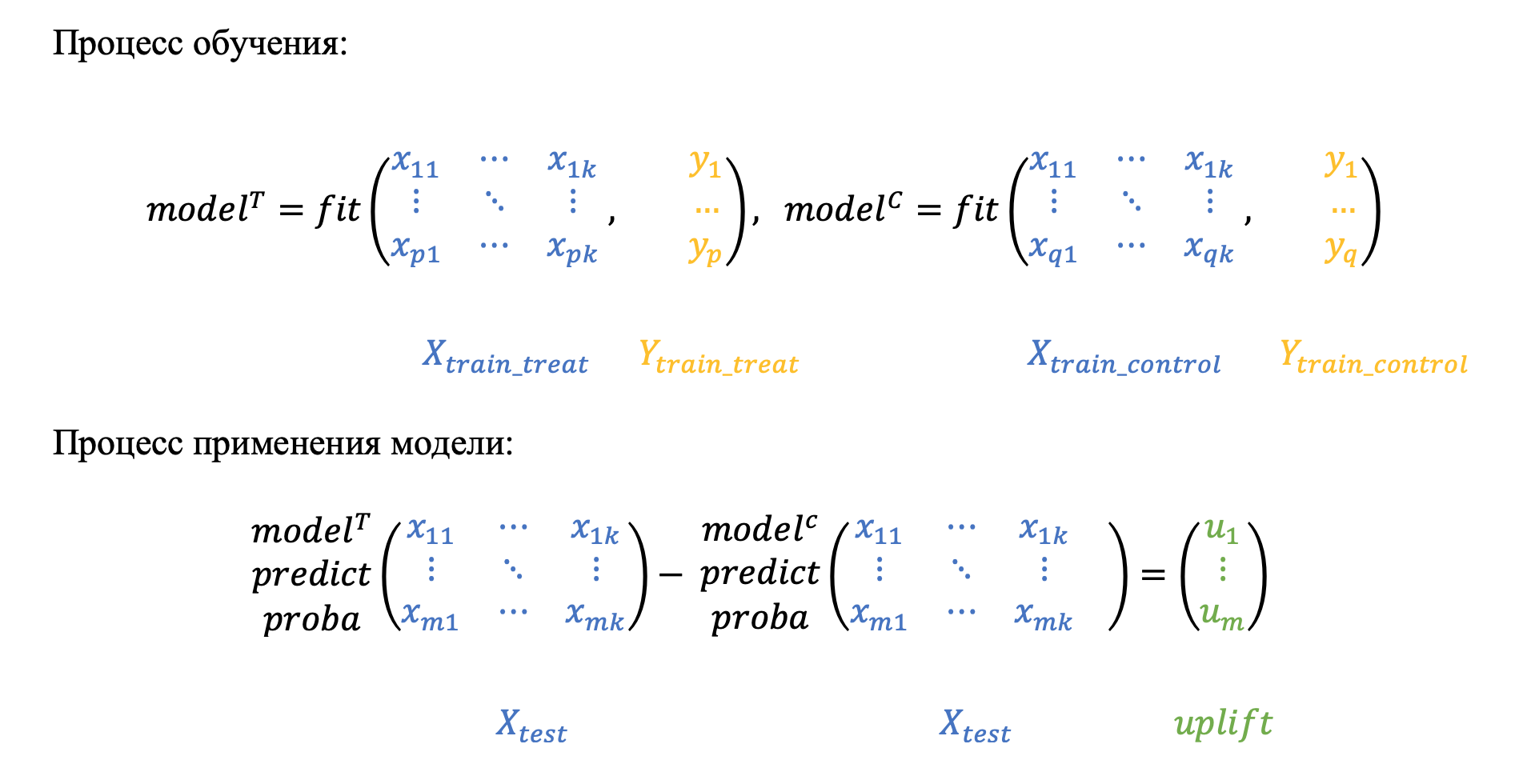
Two models approach, T-learner, difference two models
Подход с двумя моделями один из самых популярных и достаточно часто встречается в статьях, например [3] и [4]. Метод заключается в отдельном моделировании двух условных вероятностей на целевой и контрольной группах, а именно:
- Строится первая модель, оценивающая вероятность выполнения целевого действия среди клиентов, с которыми мы взаимодействовали.
- Строится вторая модель, оценивающая ту же вероятность, но среди клиентов, с которыми мы не производили коммуникацию.
- Затем для каждого клиента рассчитывается разность оценок вероятностей двух моделей.
Две зависимые модели (зависимое представление данных)
Dependent Data Representation, Dependent Feature Representation
Подход зависимого представления данных, представленный в [5], основан на методе цепочек классификаторов, первоначально разработанном для задач многоклассовой классификации. Идея состоит в том, что при наличии различных меток можно построить различных классификаторов, каждый из которых решает задачу бинарной классификации. В процессе обучения каждый следующий классификатор использует предсказания предыдущих в качестве дополнительных признаков. Авторы данного метода предложили использовать ту же идею для решения проблемы uplift моделирования в два этапа. Вначале мы обучаем классификатор по контрольным данным:
затем выполним предсказания в качестве нового признака для обучения второго классификатора на тестовых данных, тем самым вводя зависимость между двумя наборами данных:
Чтобы получить uplift для каждого наблюдения, вычислим разницу:
Так второй классификатор изучает разницу между ожидаемым результатом в тесте и контроле, т.е. сам uplift.

Аналогичным образом можно сначала обучить классификатор , а затем использовать его предсказания в качестве признака для классификатора .
Две зависимые модели (перекрестная зависимость)
Метод основывается на построении двух моделей, так же, как и в двух предыдущих подходах. Авторы статьи [6] рекомендуют применять его тогда, когда целевая группа достаточно маленькая. В этом случае есть риск, что модель, построенная на целевой группе, будет обладать недостаточной обобщающей способностью. Поэтому создается перекрестная зависимость двух моделей, чтобы усилить одну модель данными другой.
1. Сначала обучаем параллельно две модели: одну на контрольной группе, другую — на целевой (как в методе с двумя независимыми моделями):

2. Затем преобразуем обе целевые переменные, используя предсказания контрольной модели на данных целевой группы и предсказания целевой модели на данных контрольной группы. Полученные величины обозначаются как и и называются вменяемым эффектом от воздействия.

Если оценки и были бы не предсказаниями, а реальными величинами (которые мы на самом деле не можем пронаблюдать), то и были бы равны uplift, то есть
3. Обучим две новые модели на преобразованных таргетах и :
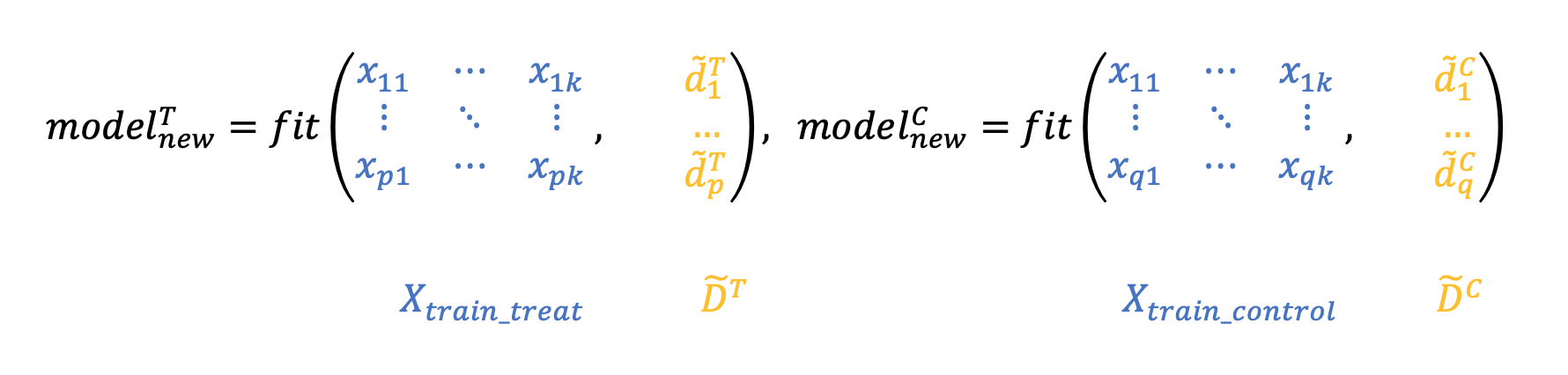
4. Взвешенная с некоторым коэффициентом сумма предсказаний этих моделей и будет uplift. Поэтому процесс применения модели будет выглядеть следующим образом:

Рекомендуется выбирать , если размер целевой группы большой по сравнению с размером контрольной группы, и , если наоборот. Кроме того, можно рассматривать не только как константу, а как некоторую функцию от объекта — .
Заключение
В этой статье были рассмотрены особенности uplift моделей, процесс сбора данных и проведения маркетинговых кампаний, а также базовые методы моделирования uplift. В следующей части мы продолжим говорить о более интересных подходах.
Статья написана в соавторстве с Ириной Елисовой (iraelisova)
Полезные ссылки
- Jupyter notebook с примером использования питоновской библиотеки scikit-uplift от Максима Шевченко (maks-sh)
- Доклад про uplift моделирование от Ирины Елисовой (iraelisova) на Data Fest 6
- Доклад про аплифт моделирование от Валерия Бабушкина (venheads)
- Доклад про рассылку персональных сообщений физ лицам клиентам банка от Александра Фонарева на Data Fest 5
- Profit Driven Business Analytics by Verbeke, Wouter & Baesens, Bart & Bravo, Cristián – отличная книга, глава в которой посвящена uplift моделированию
Источники
- [1] Verbeke, Wouter & Baesens, Bart & Bravo, Cristián. (2018). Profit Driven Business Analytics: A Practitioner’s Guide to Transforming Big Data into Added Value.
- [2] Lo, Victor. (2002). The True Lift Model — A Novel Data Mining Approach to Response Modeling in Database Marketing… SIGKDD Explorations. 4. 78-86.
- [3] Radcliffe, N.J. (2007). Using control groups to target on predicted lift: Building and assessing uplift model. Direct Market J Direct Market Assoc Anal Council, 1:14–21, 2007.
- [4] Nassif, Houssam & Kuusisto, F. & Burnside, Elizabeth & Shavlik, J… (2014). Uplift modeling with ROC: An SRL case study. CEUR Workshop Proceedings. 1187. 40-45.
- [5] Betlei, Artem & Diemert, Eustache & Amini, Massih-Reza. (2018). Uplift Prediction with Dependent Feature Representation in Imbalanced Treatment and Control Conditions: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13–16, 2018, Proceedings, Part V. 10.1007/978-3-030-04221-9_5.
- [6] Zhao, Yan & Fang, Xiao & Simchi-Levi, David. (2017). Uplift Modeling with Multiple Treatments and General Response Types. 10.1137/1.9781611974973.66.
- [7] Gutierrez, P., & Gérardy, J. Y. (2017). Causal Inference and Uplift Modelling: A Review of the Literature. In International Conference on Predictive Applications and APIs (pp. 1-13).
- Блог компании МТС
- Data Mining
- Машинное обучение
- Интернет-маркетинг
- Повышение конверсии