Шардирование vs репликация: масштабируем БД
Представим себе БД услуг барбершопа в Южном Бутово. Данные лежат в одной табличке в PostgreSQL и используются внутренней системой для составления расписания мастеров, расчета премий и т. д.
Таблица clients
Бородачей в Бутово оказалось сильно больше, чем предполагалось в изначальном бизнес-плане.
Владельцам барбершопа пришлось выкупить соседний спортзал и нанять еще 100 барберов.
Бизнес процветает. Роскошные бороды заполонили Бутово. Однако, БД начала подводить:• из-за выхода из строя сервера БД 400 людей остались не побритыми• в самое загруженное время, чтобы узнать расписание мастера,администратор вынужден ждать до 60 секунд ответа БД
Такие потери недопустимы для бизнеса. Что ж, давай разбираться. Технически есть 2 проблемы:• нет отказоустойчивости• слишком много чтения из БД
Для решения этих проблем можно использовать репликацию.
Репликация
Репликация — полное копирование БД на такой же сервер.
Основной сервер назовем «Мастер», а дополнительные — «Реплика». Любой из этих серверов будем называть «Нода» (node).
Писать мы сможем только в мастер. А реплики будут вытягивать из мастера все изменения (синхронизироваться).
Шардирование
Добавьте ссылки на источники, в противном случае она может быть выставлена на удаление.
Дополнительные сведения могут быть на странице обсуждения.
Архитектура базы данных
Горизонтальное партиционирование — это принцип проектирования базы данных, при котором логически независимые строки таблицы базы данных хранятся раздельно, заранее сгруппированные в секции, которые, в свою очередь, размещаются на разных, физически и логически независимых серверах базы данных, при этом один физический узел кластера может содержать несколько серверов баз данных. Наиболее типовым методом горизонтального партицирования является применение хеш функции от идентификационных данных клиента, которая позволяет однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных («шарду»), тем самым обеспечив практически неограниченную от количества клиентов горизонтальную масштабируемость.
Этот подход принципиально отличается от вертикального масштабирования, которое при росте нагрузки и объёма данных предусматривает наращивание вычислительных возможностей и объёма носителей информации одного сервера баз данных, имеющее объективные физические пределы — максимальное количество поддерживаемых CPU на один сервер, максимальный поддерживаемый объем памяти, пропускная способность шины и т. д.
Шардирование обеспечивает несколько преимуществ, главное из которых — снижение издержек на обеспечение согласованного чтения (которое для ряда низкоуровневых операций требует монополизации ресурсов сервера баз данных, внося ограничения на количество одновременно обрабатываемых пользовательских запросов, вне зависимости от вычислительной мощности используемого оборудования). В случае шардинга логически независимые серверы баз данных не требуют взаимной монопольной блокировки для обеспечения согласованного чтения, тем самым снимая ограничения на количество одновременно обрабатываемых пользовательских запросов в кластере в целом.
Серверы баз данных, поддерживающие шардирование
MongoDB поддерживает шардирование с версии 1.6.
Plugin for Grails
Grails поддерживает шардирование путем Grails Sharding Plugin.
Redis база данных с поддержкой шардирования на стороне клиента.
Microsoft поддерживает шардирование в SQL Azure через «федерации».
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга [1] , Facebook [2] и Twitter [3] применяют шардирование поверх MySQL и т. д.
Примечания
- ↑Scalability Best Practices: Lessons from eBay
- ↑Facebook shares some secrets on making MySQL scale — Cloud Computing News
- ↑Twitter Engineering: Introducing Gizzard, a framework for creating distributed datastores
- Базы данных
- Теоретические основы баз данных
Wikimedia Foundation . 2010 .
Шардинг и репликация

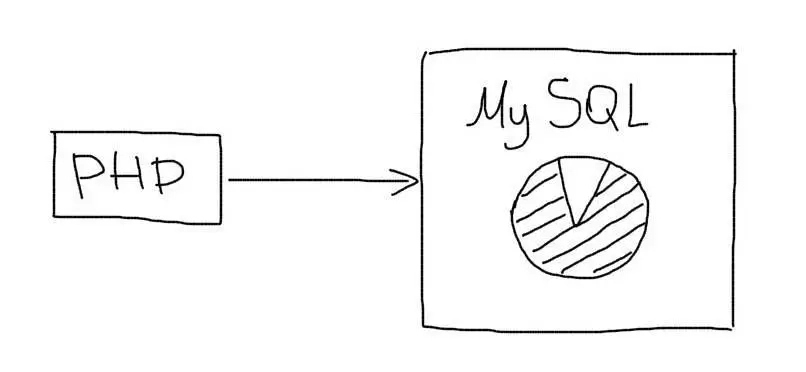
Масштабирование баз данных — самая сложная задача во время роста проекта. 90% всех усилий обычно приходится как раз на работу, связанную с ростом объема данных и операций с ними. Классическая схема работы приложения с базой данных выглядит так:
Один сервер базы данных в какой-то момент перестает справляться с нагрузкой. В этот момент и следует применять описанные тут техники масштабирования.
Курс Project Manager.
Впроваджуйте покроковий алгоритм управління проєктами вже зараз. У цьому вам допоможе Павло Харіков — Head of IoT у Veon Group (Kyivstar).
Перед тем, как приступать к масштабированию, необходимо провести анализ медленных запросов и убедиться, что сервер MySQL настроен оптимально.
Стратегии
В основе масштабирования данных лежит тот же принцип, что и в основе масштабирования Web приложений. Это разделение данных на группы и выделение их на отдельные сервера. Существует две основные стратегии — репликация и шардинг.
Курсы от наших партнёров помогут вам повысить свой уровень знаний при работе с базами данных. IAMPM и Hillel ждут учеников чтобы передать им свой опыт.
Репликация
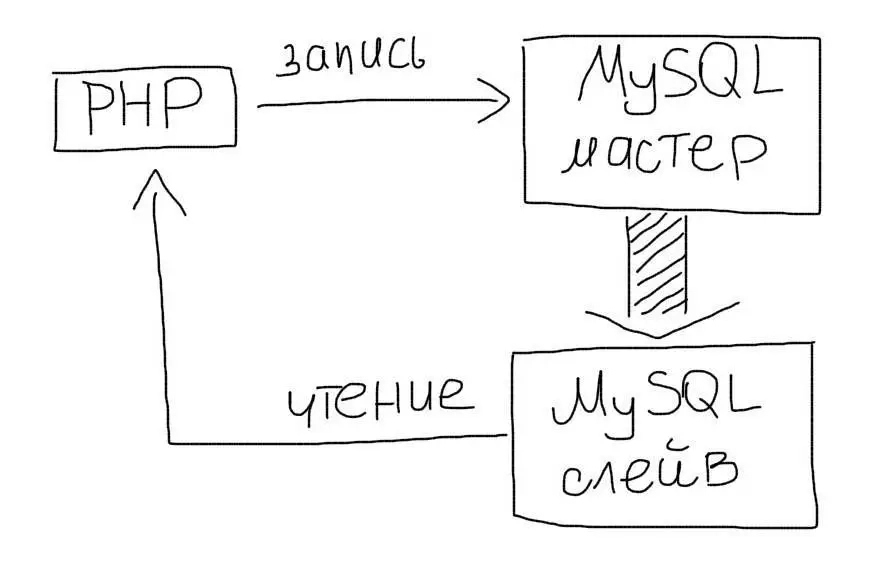
Репликация позволяет создать полный дубликат базы данных. Так, вместо одного сервера у Вас их будет несколько:
Master-slave
Чаще всего используют схему master-slave:
Курс Аналітик даних.
Протягом 4 місяців ви вивчите повний набір інструментів для аналізу даних та отримаєте можливість працевлаштування в Laba Group.
- Master — это основной сервер БД, куда поступают все данные. Все изменения в данных (добавление, обновление, удаление) должны происходить на этом сервере.
- Slave — это вспомогательный сервер БД, который копирует все данные с мастера. С этого сервера следует читать данные. Таких серверов может быть несколько.
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Работа из приложения
В приложении у Вас будет два соединения с базой данных. Одно — для мастера и одно для слейва:
$master = mysql_connect('10.10.0.1', 'root', 'pwd'); $slave = mysql_connect('10.10.0.2', 'root', 'pwd'); # какой-то код и все такое. $q = mysql_query('INSERT INTO users . ', $master); # еще какой-то код. $q = mysql_query('SELECT * FROM users WHERE. ', $slave);
При выполнении запросов необходимо использовать соответствующее соединение
Репликация обычно поддерживается самой СУБД (например, MySQL) и настраивается независимо от приложения.
Читайте детальнее про настройку, использование и типы репликации данных на примере MySQL.
Следует отметить, что репликация сама по себе не очень удобный механизм масштабирования. Причиной тому — рассинхронизация данных и задержки в копировании с мастера на слейв. Зато это отличное средство для обеспечения отказоустойчивости. Вы всегда можете переключиться на слейв, если мастер ломается и наоборот. Чаще всего репликация используется совместно с шардингом именно из соображений надежности.
Шардинг (sharding)
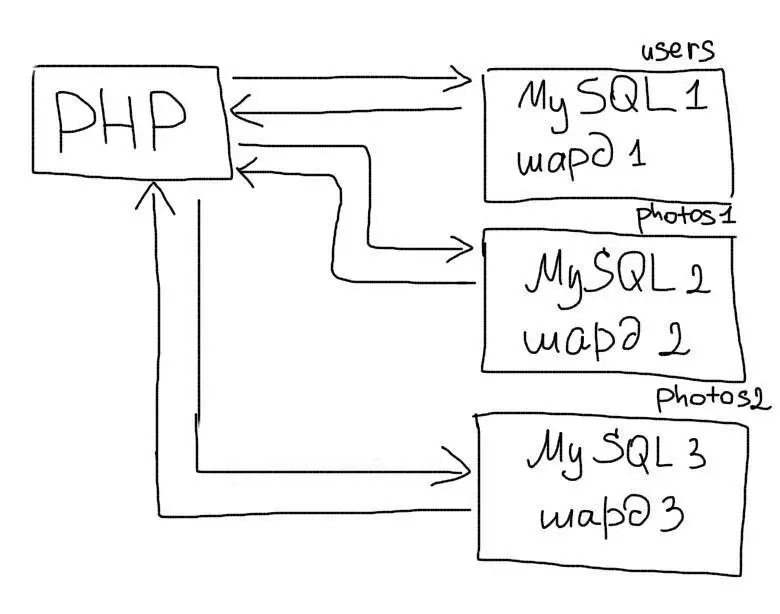
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации:
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
Курс Комерційний директор.
Зосередження на практичних завданнях та послідовному аналізі проектів замість великої теорії. Реалізуй свої мрії про керівну посаду після завершення курсу.
- users — данные пользователей
- photos — фотографии пользователей
- albums — альбомы пользователей
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей:
$users_connection = mysql_connect('10.10.0.1', 'root', 'pwd'); $photos_connection = mysql_connect('10.10.0.2', 'root', 'pwd'; # какой-то код и все такое. $q = mysql_query('SELECT * FROM users WHERE . ', $users_connection); # еще какой-то код. $q = mysql_query('SELECT * FROM photos WHERE. ', $photos_connection); # еще какой-то код. $q = mysql_query('SELECT * FROM albums WHERE. ', $photos_connection);
Для каждой таблицы или группы таблиц будет отдельное соединение
В отличие от репликации, мы используем разные соединения для любых операций, но с определенными таблицами. Читайте подробнее об использовании вертикального шардинга на практике.
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
- На нескольких серверах создается одна и та же таблица (только структура, без данных).
- В приложении выбирается условие, по которому будет определяться нужное соединение (например, четные на один сервер, а нечетные — на другой).
- Перед каждым обращением к таблице происходит выбор нужного соединения.
Курс Англійської.
Навчання для різних цілей та рівнів: робоча англійська, початковий рівень, курси для дітей та підлітків.
Допустим, наше приложение работает с огромной таблицей, которая хранит фотографии пользователей. Мы подготовили два сервера (обычно они называются шардами) для этой таблицы. Для нечетных пользователей мы будем работать с первыми сервером, а для четных — со вторым. Таким образом, на каждом из серверов будет только часть всех данных о фотках пользователей. Это будет выглядеть так:
'2' => '10.10.0.2', ]; $user_id = $_SESSION['user_id']; # получение фотографий для пользователя $user_id $connection_num = $user_id % 2 == 0 ? 1 : 2; $connection = mysql_connect($photo_connections[$connection_num], 'root', 'pwd'); $q = mysql_query('SELECT * FROM photos WHREE user_id = ' . intval($user_id), $connection);
Перед обращением к таблице, мы выбираем нужное нам соединение
Результат вот этой операции $user_id % 2 будет остатком от деления на 2. Т.е. для четных чисел — 0, а для нечетных — 1.
Любая работа с таблицей photos теперь будет происходить только после получения нужного соединения на основе $user_id .
Горизонтальный шардинг — это очень мощный инструмент масштабирования данных. Но в то же время и очень нетривиальный. Читайте детально об использовании горизонтального шардинга на практике.
Не следует применять технику шардинга ко всем таблицам. Правильный подход — это поэтапный процесс разделения растущих таблиц. Следует задумываться о горизонтальном шардинге, когда количество записей в одной таблице переходит за пределы от нескольких десятков миллионов до сотен миллионов.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
- photos_master_1 — мастер первой половины таблицы.
- photos_slave_1 — слейв первой половины таблицы.
- photos_master_2 — мастер второй половины таблицы.
- photos_slave_2 — слейв второй половины таблицы.
Тогда в приложении работа с этой табличкой может выглядеть так:
'master' => '10.10.0.10', 'slave' => '10.10.0.11', ], '2' => [ 'master' => '10.10.0.20', 'slave' => '10.10.0.21', ], ]; $user_id = $_SESSION['user_id']; # Читаем данные со слейвов $connection_num = $user_id % 2 == 0 ? 1 : 2; $connection = mysql_connect($photo_connections[$connection_num]['slave'], 'root', 'pwd'); $q = mysql_query('SELECT * FROM photos WHREE user_id = ' . intval($user_id), $connection); # какой-то код. # Изменение данных происходит на мастерах $photo_id = 7; $connection_num = $user_id % 2 == 0 ? 1 : 2; $connection = mysql_connect($photo_connections[$connection_num]['master'], 'root', 'pwd'); $q = mysql_query('UPDATE photos SET views = views + 1 WHREE photo_id = ' . intval($photo_id), $connection);
Читаем данные со слейвов, а записываем на мастер-сервера
Такая схема часто используется не для масштабирования, а для обеспечения отказоустойчивости. Так, при выходе из строя одного из серверов шарда, всегда будет запасной.
Key-value базы данных
Следует отметить, что большинство [p165 Key-value баз данных] поддерживает шардинг на уровне платформы. Например, Memcache. В таком случае, Вы просто указываете набор серверов для соединения, а платформа сделает все остальное:
$m->addServer('10.5.0.2'); $m->addServer('10.5.0.3'); . $m->get('user1')
Мемкеш сам умеет определять нужный сервер для каждого ключа
Самое важное
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии. Получить навыки для работы с базами данных на можно на курсах наших партнеров Hillel и IAMPM.
Помните, процесс масштабирования данных — это архитектурное решение, оно не связано с конкретной технологией. Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Курс Англійської.
Навчання для різних цілей та рівнів: робоча англійська, початковий рівень, курси для дітей та підлітків.
Масштабирование баз данных — партиционирование, репликация и шардинг
СУБД очень часто становится «узким местом» в производительности веб‑приложений, влияющим на общее быстродействие и устойчивость к высоким нагрузкам.
Масштабирование «железа» и адекватная настройка
Первое, что стоит сделать, если скорость работы базы данных не удовлетворяет требованиям, это проверить адекватность настройки СУБД относительно имеющихся ресурсов, а также убедиться, что при проектировании БД были учтены используемые запросы. Если, например, для СУБД работает с настройками «из коробки», а при обработке запросов не используются индексы, то надо не масштабировать СУБД, достаточно просто откорректировать конфигурацию работы сервера баз данных и обновить схему используемой базы данных под профиль нагрузки. Иногда также проще увеличить выделение ресурсов под сервер баз данных — количество оперативной памяти и скорость работы дисковой подсистемы оказывают существенное воздействие на скорость работы СУБД. Нередко даже небольшое увеличение RAM и переход на SSD увеличивает производительность в разы.
Масштабирование через партиционирование, репликацию и шардинг
В момент, когда даже корректно настроенный сервер баз данных на достаточно мощном железе уже недостаточно хорошо справляется с нагрузками, производится масштабирование при помощи партиционирования, репликации и шардинга. Далее рассмотрим эти способы увеличения производительности СУБД.
Масштабирование SQL и NoSQL
Описанные ниже схемы масштабирования применимы как для реляционных баз данных, тах и для NoSQL‑хранилищ. Разумеется, что у всех баз данных и хранилищ есть своя специфика, поэтому мы рассмотрим только основные направления, а в детали реализации вдаваться не будем.
Партиционирование (partitioning)
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД. Для правильного конфигурирования параметров партиционирования необходимо, чтобы в каждом потоке было примерно одинаковое количество записей.
Например, на новостных сайтах имеет смысл партиционировать записи по дате публикации, так как свежие новости на несколько порядков более востребованы и чаще требуется работа именно с ними, а не со всех архивом за годы существования новостного ресурса.
Репликация (replication)
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие серверы часто называют мастерами (master), а ведомые серверы — слэйвами (slave). Более политкорректные современные названия — Лидер и Фолловер (leader & follower).
Ведущие сервера используются для чтения и изменения данных, а ведомые — только для чтения. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб‑проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Например, создание нескольких дополнительных slave‑серверов позволяет снять с основного сервера нагрузку и повысить общую производительность системы, а также можно организовать слэйвы под конкретные ресурсоёмкие задачи и таким образом, например, упростить составление серьёзных аналитических отчётов — используемый для этих целей slave может быть нагружен на 100%, но на работу других пользователей приложения это не повлияет.
Шардинг (sharding)
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Например, в системах типа социальных сетей ключом для шардинга может быть ID пользователя, таким образом все данные пользователя будут храниться и обрабатываться на одном сервере, а не собираться по частям с нескольких.
Статья опубликована в 2014 и была обновлена в 2020 году
Тематические статьи
Реляционные базы данных и NoSQL‑хранилища
Базы данных служат для хранения и обработки данных. Бывают реляционные (SQL) и нереляционные (NoSQL) системы управления базами данных.
Реляционные системы управления базами данных (SQL) хранят данные в табличных структурах и чаще всего используются в качестве основного хранилища для веб‑приложений. Они очень стабильны и их надёжность проверена временем. Нереляционные СУБД (NoSQL) заметно моложе реляционных баз данных, а также заметно от них отличаются по структуре хранения данных и работе с ними. Большинство нереляционных хранилищ превосходят классические SQL СУБД по скорости доступа или при работе со специфическими типами данных, но обычно эта скорость достигается за счёт снижения надёжности хранения. На практике NoSQL‑решения обычно применяются не для хранения всех данных приложения, а для решения специфических задач — для кэширования, хранения логов, управления очередями, для распределённого хранения данных, ускорения поиска и фильтрации.
хранение данных
серверное ПО
Статья опубликована в 2019 году
Быстрый поиск на сайте, используя ElasticSearch или Sphinx
Sphinx и ElasticSearch — это поисковые «движки», которые обеспечивают более быстрый поиск и фильтрацию по сравнению с реляционными базами данных, а также обеспечивают возможность использования многих полезных функций поиска, например, учитывают морфологию языка, осуществляют фасеточный поиск, работают со стоп‑словами, обеспечивают выборочную индексацию и позволяют производить настройку формулы определения релевантности документов.