MetaMask Legacy Web3 от danfinlay, rekmarks
![]()
The MetaMask extension provides an API to websites you visit so they can interact with the blockchain. In the past, we used to provide a complementary API known as window.web3. As of December 2020, we stopped injecting window.web3, which improves security and performance, but can break older and unmaintained websites. Using this extension in combination with the MetaMask wallet enables you to use those older sites as before.
Комментарии разработчика
Оцените работу расширения
Сообщить о нарушении правил этим дополнением
Сообщить о нарушении правил этим дополнением
Если вы считаете, что это дополнение нарушает политики Mozilla в отношении дополнений, или имеет проблемы с безопасностью или приватностью, сообщите об этих проблемах в Mozilla, используя эту форму.
Не используйте эту форму, чтобы сообщать об ошибках или запрашивать новые функции в дополнении; это сообщение будет отправлено в Mozilla, а не разработчику дополнения.
РазрешенияПодробнее
Этому дополнению нужно:
- Получать доступ к вашим данных на всех сайтах
Больше сведений
- Страница поддержки
- Эл. почта поддержки
- Веб-разработка
- Другое
- Просмотреть все версии
Что такое Web3?
Web3 – это общий термин для таких технологий, как блокчейн, которые децентрализуют владение и управление данными в Интернете. Большинство интернет-приложений находятся под управлением централизованных организаций, которые определяют, как они сохраняют и используют данные конечных пользователей. В отличие от централизованных структур управления, технологии Web3 (Web 3.0, децентрализованная или семантическая сеть) позволяют реализовывать проекты, управляемые сообществом. В этих проектах конечные пользователи контролируют данные, определяют цены, вносят непосредственный вклад в техническое развитие и играют более важную роль в определении направления проекта. Технологии обладают механизмами для автоматического регулирования взаимодействия пользователей, благодаря чему централизованным объектам не нужно управлять этими взаимодействиями.
В чем заключаются основные идеи Web 3.0?
У Web 3.0 есть четыре основные особенности.
Децентрализация
Децентрализованные веб-приложения – ключевая особенность Web 3.0. Цель – распространение и хранение данных в децентрализованных сетях. В этих сетях различные организации владеют базовой инфраструктурой, а пользователь платит непосредственно поставщику услуг хранения за доступ к таким ресурсам.
Децентрализованные приложения также хранят реплики информации в нескольких местоположениях и гарантируют согласованность данных. Каждый пользователь может самостоятельно контролировать, где находятся его данные, а не передавать их в централизованную инфраструктуру. В условиях децентрализованного Интернета пользователи могут продавать свои данные, если захотят.
Принцип недоверия
В централизованных веб-приложениях и сервисах пользователям часто приходится обращаться к центральному органу для управления данными, выполнения транзакций и взаимодействия. Такие центральные органы контролируют данные пользователей и могут манипулировать правилами системы. При этом данные могут подвергаться риску нарушения безопасности или неправильного распоряжения, что потенциально может стать причиной потери или неправомерного использования информации пользователя.
Web3, напротив, вводит принцип недоверия, поэтому пользователи могут участвовать в транзакциях и взаимодействиях, не доверяя какой-либо конкретной стороне.
Семантическая сеть
С помощью семантической сети приложения могут выполнять сложные задачи, ориентируясь на содержимое и контекст веб-данных. Она использует метаданные и искусственный интеллект для придания смысла (семантики) данным, предоставляемым пользователями.
Web 3.0 стремится к полному переходу на семантические веб-технологии, которые в настоящее время присутствуют в некоторых аспектах существующих веб-технологий. Например, поисковая система предоставляет более точные и контекстуально уместные результаты поиска, а интеллектуальные агенты помогают пользователям более эффективно выполнять задачи.
Обеспечение совместимости
Web 3.0 предполагает создавать более тесные взаимосвязи между различными технологиями, чтобы данные перемещались между различными платформами без посредников. Благодаря совместимости данные можно перемещать, чтобы пользователи могли легко переключаться между сервисами, сохраняя при этом свои предпочтения, профили и настройки.
В то же время протоколы, объединяющие широкий спектр устройств Интернета вещей (IoT), расширяют сферу действия сети за пределы традиционных границ. Например, криптовалютные технологии, которые поддерживают транзакции без границ, дают возможность обмениваться ценностями, преодолевая географические и политические границы.
Почему сеть Web 3.0 важна?
Когда Интернет только возник, распространенным явлением были веб-сервисы, работающие только на чтение. Конечные пользователи могли читать только тот контент, который публиковали компании, приобретавшие и обслуживавшие инфраструктуру, где размещались статические веб-страницы.
С появлением технологий Web 2.0, таких как блоги и платформы социальных сетей, приложения стали более интерактивными. Вы можете создавать и публиковать контент или обмениваться сервисами с другими пользователями. Однако все взаимодействия регулируют центральные сторонние органы, которые получают коммерческую выгоду от обмена сервисами. Они также могут владеть цифровыми ресурсами, создаваемыми конечными пользователями, и контролировать их.
Например, на централизованных платформах фрилансеров связывают с заказчиками, а на платформах аренды помещений – владельцев недвижимости с арендаторами. Как поставщики сервисов, так и их пользователи предоставляют такие данные, как профили и описания сервисов, профили пользователей, блоги, видео и комментарии. Платформы централизованно управляют всеми этими данными.
Проблемы, связанные с Web 2.0
В то время как центральные платформы облегчают и регулируют взаимодействие между двумя сторонами, механизмы Web 2.0 создают ряд проблем:
- Поставщики сервисов могут лишиться возможности переносить свои данные на другие платформы без потери деловой репутации и клиентской базы.
- Пользователи сервиса не могут контролировать то, как используют их данные и как ими управляют.
- Централизованная платформа вправе принимать определенные решения, которые могут существенно повлиять на конечных пользователей. Например, они могут фильтровать определенный пользовательский контент или ограничивать доступ конечных пользователей к некоторым функциям сайта.
Преимущества Web 3.0
Web 3.0 предполагает переход к парадигме чтение/запись/владение, когда создатели данных владеют своими данными, контролируют их и обладают большим влиянием на то, как данные используются и как ими распоряжаются. Технологии Web 3.0 предоставляют несколько механизмов, благодаря которым конечные пользователи становятся акционерами и участниками, а не просто клиентами. Далее описаны еще несколько преимуществ.
Повышение вовлеченности
Пользователи взаимодействуют друг с другом и с поставщиком решений более осмысленно. Вместо запросов на обмен данными они получают стимулы для активного участия в онлайн-сообществах.
Улучшение конфиденциальности
Каждый пользователь сам определяет, кто имеет доступ к его данным. Владельцу инфраструктуры, в которой хранятся данные, они недоступны. Ваши действия в Интернете могут быть общедоступными, но ваша личность остается конфиденциальной.
Демократизация процесса общения
Web 3.0 стремится устранить географические, политические и корпоративные барьеры в общении. Система ограничивает цензуру со стороны крупных технологических компаний и обеспечивает баланс между требованиями безопасности и повышением прозрачности.
Какие основные технологии используются в Web 3.0?
В основе многих приложений Web 3.0 лежит технология блокчейн, обеспечивающая прозрачность, неизменность и принцип недоверия. Блокчейн – это децентрализованные и распределенные реестры, хранящие записи о транзакциях или данных в сети узлов.
В базе данных блокчейна данные хранятся в хронологически последовательных блоках, удалить или изменить которые можно только на основе консенсуса в одноранговой сети. Система имеет встроенные механизмы, которые предотвращают несанкционированный ввод транзакций и создают согласованность в общем представлении этих транзакций. Поэтому с ее помощью можно создать неизменяемый или бессрочный реестр для отслеживания всех типов транзакций.
Другие ключевые технологии, лежащие в основе разработки Web 3.0, представлены далее.
Токенизация
Вы можете расширить применение технологии блокчейн за счет токенизации. Токенизация – это процесс представления реальных или цифровых ресурсов в виде цифровых токенов в блокчейне.
Такие токены – это криптографические представления прав собственности, прав доступа или других форм стоимости. Например, вы можете представлять физические и цифровые ресурсы: недвижимость, акции, товары, произведения искусства, музыку и даже игровые предметы.
Каждый токен может обозначать определенную долю или целую единицу базового ресурса, что позволяет разделить его на части и легко использовать для торгов. В виртуальном мире существуют различные типы токенов, в частности токены ценных бумаг, на которые распространяются правила обращения с ценными бумагами, или невзаимозаменяемые токены (NFT), представляющие собой уникальные, неделимые активы, которые не предусматривают возможность фрактального владения.
WebAssembly
WebAssembly (Wasm) – это формат двоичных инструкций для виртуальной машины, основанной на стеке. Он работает в изолированной среде браузера, то есть не имеет доступа к локальной файловой системе пользователя.
Сервис позволяет выполнять высокопроизводительный код в веб-браузерах, что создает основу для эффективной работы децентрализованных приложений на различных платформах. Разработчики могут запускать код на скорости, близкой к естественной, получая значительный прирост производительности по сравнению с традиционными веб-технологиями, такими как JavaScript.
Технологии семантической сети
Технологии семантической сети дают возможность приложениям лучше воспринимать и интерпретировать данные о клиентах. Они используют принципы связанных данных для объединения нескольких наборов данных или публикации структурированных данных в Интернете. Далее представлены несколько примеров.
Resource Description Framework
С помощью технологии Resource Description Framework (RDF) вы можете выражать утверждения в виде троек в форме «субъект-предикат-объект». Эти тройки создают графовую структуру данных, представляющую отношения между различными сущностями. SPARQL – это язык запросов для запроса данных RDF.
Web Ontology Language
Web Ontology Language (OWL) – это язык для определения онтологий или формальных представлений знаний и отношений между понятиями. С его помощью можно определять классы, свойства и инстансы, а также упрощать аргументацию и выводы.
Какие существуют примеры приложений Web 3.0?
В настоящее время создают различные приложения для технологии блокчейн, представленные в виде API и сервисов. На их основе создают другие приложения Web3 для различных случаев использования. Далее представлены несколько примеров.
Смарт-контракты
Смарт-контракты – это самореализующиеся контракты с заранее определенными правилами, записанными в коде. Они автоматически приводят в исполнение условия контракта при выполнении определенных требований. Например, если в контракте указано, что право собственности на предмет переходит к тому, кто за него платит, вы просто отправляете запрашиваемую цену в этот контракт. Затем реестр автоматически обновляется с помощью транзакции в следующем блоке, чтобы отобразить вас как нового владельца.
Децентрализованная автономная организация (DAO) – это согласованный смарт-контракт, который автоматизирует децентрализованное принятие решений в отношении пула ресурсов (токенов). Пользователи с токенами голосуют за то, как расходуются ресурсы, и код автоматически определяет результаты голосования.
С помощью смарт-контракта можно запрограммировать условия для таких финансовых инструментов, как ипотека, облигации и ценные бумаги (их еще называют децентрализованными финансами). Кроме того, можно упростить отслеживание и оплату товаров по цепочке поставок. Смарт-контракты позволяют устранить необходимость в посредниках, что повышает эффективность и безопасность транзакций.
Децентрализованная идентификация
Децентрализованная идентификация – это технология, целью которой заключается в предоставление людям возможности контролировать свою цифровую идентификацию и обладать правом собственности на нее. В традиционных онлайн-системах пользователи часто полагаются на централизованных поставщиков идентификационных данных (например, платформы социальных сетей или почтовые сервисы) в вопросах управления своими идентификационными данными и доступа к различным онлайн-сервисам.
Децентрализованная идентификация передает контроль над идентификационной информацией индивидуальному пользователю. В этом случае используются глобально уникальные идентификаторы (GUID), связанные с документом децентрализованного идентификатора (DID). Этот документ содержит открытые ключи, криптографические материалы и адреса сервисов, связанные с идентификацией. В этой технологии используется выборочное разглашение, позволяющее сообщать конкретные идентификационные атрибуты и минимизировать воздействие на информацию, позволяющую установить личность (PII), в процессе проверки личности.
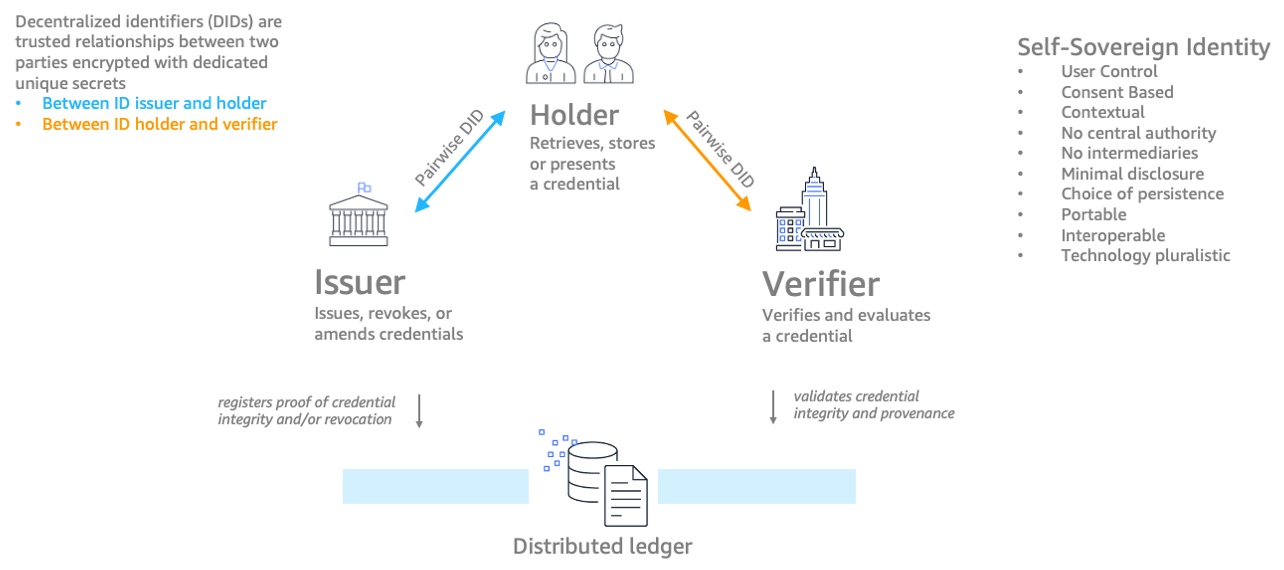
InterPlanetary File System (IPFS)
IPFS – это децентрализованная и распределенная система хранения файлов, которая обеспечивает более эффективный и надежный способ хранения контента в Web 3.0 и доступа к нему. При этом каждому файлу присваивается уникальный криптографический хэш (адрес на основе контента). В системе используется одноранговая сеть, где каждый узел IPFS выступает в роли клиента и сервера. Узлы совместно хранят, извлекают и распространяют контент по сети, что устраняет необходимость в централизованных серверах.
Например, когда пользователь запрашивает контент в IPFS, система использует уникальный хэш контента для определения местоположения узлов, на которых он хранится. Затем происходит параллельное извлечение контента с нескольких узлов, что позволяет обеспечить избыточность и отказоустойчивость.
Какие проблемы возникают при внедрении Web 3.0?
Как и в случае с любой новой технологией, при внедрении Web3 возникает ряд проблем, которые необходимо решить для обеспечения широкого и успешного распространения. Далее приводятся некоторые основные проблемы.
Технические проблемы
Масштабируемость по-прежнему остается одной из главных проблем, поскольку при увеличении объема данных сети блокчейн могут оказаться очень дорогими и требовать значительных объемов вычислений. На постоянной основе ведутся работы по созданию устойчивых и экологически безопасных технологий.
Еще одна проблема – совместимость между различными блокчейн-сетями и протоколами.
Взаимодействие с пользователем и внедрение
Из-за сложности интерфейсов и необходимости длительного обучения не удается массово распространить систему. Необходимо улучшать качество обслуживания пользователей, разрабатывая интуитивно понятные интерфейсы, которые устраняют все сложности технологии блокчейн.
Кроме того, возникает проблема соответствия нормативным требованиям, поскольку приложения Web3 должны соблюдать существующие требования по защите данных и финансовой безопасности.
Управление
Управление в децентрализованных системах может быть сопряжено с определенными трудностями. Для этого необходимы эффективные структуры, предполагающие участие сообщества и не допускающие централизации власти.
Разработка эффективной токеномики и стандартов токенов, соответствующих целям приложения, требует тщательной проработки. Чтобы преодолеть эти препятствия, нужно сотрудничать, внедрять инновации и постоянно совершенствоваться в пределах сообщества Web3.
Как AWS может удовлетворить ваши требования к Web 3.0?
Управляемый блокчейн Amazon – это полностью управляемый сервис, призванный помочь вам создавать отказоустойчивые приложения Web3 как в публичных, так и в частных блокчейнах. С этой технологией вам не нужно беспокоиться о развертывании специализированной блокчейн-инфраструктуры и поддержании подключения приложений Web3 к блокчейн-сети.
Все функции Управляемого блокчейна Amazon безопасно масштабируются для создания приложений институционального уровня и основных потребительских приложений. Ниже перечислены другие преимущества работы с этим сервисом.
- AMB Access можно использовать для мгновенного бессерверного доступа к нескольким блокчейнам.
- С помощью AMB Query можно использовать удобные для разработчиков API для доступа к историческим данным из нескольких блокчейнов в режиме реального времени.
- Стандартизированные данные блокчейна можно интегрировать с сервисами AWS без необходимости в специализированной блокчейн-инфраструктуре или инструментах извлечения, преобразования и загрузки (ETL).
Начните работу с приложениями Web 3.0 на AWS, создав аккаунт уже сегодня.
Как запускать расширения Хрома не из магазина WebStore
Начиная с версии 35 (35.0.1916.114 m), как известно (англ.), браузер Google Chrome для ОС Windows перестал поддерживать установку новых и работу прежде установленных расширений, размещённых не в магазине Chrome WebStore. Это же касается и всех юзерскриптов, не размещённых в этом магазине. Группа Windows-пользователей — обширна, поэтому требуются новые инструкции о том, как с этим бороться. Линуксоидам и маководам это, к счастью, пока не грозит.
История
- Первое закручивание гаек в сентябре 2012 г.: версия манифеста 2.0;
- Полный запрет работы не из магазина в мае 2014 г.;
- Это планировалось ещё в ноябре 2013-го: Chrome users on Windows will soon have to get extensions through Google’s store.
Что может быть в установке расширений плохого? В первую очередь, если скрипт (расширение или юзерскрипт) начинает работать на домене, который содержит пользовательские данные, его конфиденциальную информацию, его пароли, логин — всё это становится доступным скрипту, и далее только моральные вопросы к разработчику скрипта определяют не «сольёт» ли он куда-либо эти данные. Несмотря на некоторое различие между Global Scope расширения и остальной части страницы, нет никакой проблемы внедрить скрипт в основную страницу (даже путём подгрузки внешнего изменяемого скрипта) и после этого уже ничем не отличаться от скриптов страницы. Всё, за что отвечает владелец сайта (домена) в отношении пользовательских данных, получает потенциально и автор расширения или юзерскрипта. Об этом постоянно ранее предупреждал Google Chrome при попытке установить скрипт или расширение. Это будет и сейчас, но с разницей в том, что браузер по умолчанию будет устанавливать расширения только из магазина Google WebStore.
Теперь для установки расширений нужно использовать более сложную технику, чтобы обойти новые препятствия. Варианты есть. Для корпоративных пользователей специальных расширений есть даже возможность в различных ОС «подписать» браузер на разрешение скачивания с определённого производственного сайта и даже возможность автоматической загрузки или обновления всех необходимых предприятию расширений — при первой установке браузера или при очередном запуске.
Дальнейший текст предназначен для людей, понимающих, какие могут быть последствия установки непроверенных расширений Хрома не из магазина компании Google.
Варианты обхода ограничений
Есть разные способы: простые и сложные, ручные и автоматические. Не выбирайте сразу первый — возможно, вас устроит следующий простой, или способ со сменой браузера (из семейства Webkit). Насколько удобен тот или иной способ, зависит от целей пользователя и от фактической надёжности разных трюков, которая будет проверена только со временем.
Есть официальные советы от Гугла для таких случаев, но там не на одной странице и неполно.
Способ 1, «не пакуй, да не упакован будешь». Самый честный, но официально не рекомендуемый. Распаковать и установить каждое расширение распакованным. Как минус, при каждом новом запуске браузера придётся подтверждать, что расширения установлены сознательно и отключать их не надо (скриншот leonid239 ).
Процесс установки распакованного расширения в Chrome
Этим способом возможно решить различные случаи запуска расширений и юзерскриптов в браузере — как новых, так и переставших внезапно работать после неуправляемого обновления браузера.
1.1. Установка скачанного откуда-либо расширения в виде файла *.crx
1.1.1. Вначале открыть страницу chrome://extensions/ и установить галочку «Режим разработчика», чтобы появились кнопки для установки и обновления расширений.
1.1.2. Взять файл расширения с окончанием «CRX», переименовать окончание в «ZIP» и распаковать полученный архив в папку (сделанную, например, в общей папке для расширений, созданной для этих целей. Пример: c:\myFiles\chromeExtensions\habrajax).
1.1.3. Установить распакованное расширение из папки нажатием на кнопку «Загрузить распакованное расширение», далее — выбрать каталог, в котором оно распаковано (удобно просто внести в поле имени папки путь к папке, затем Enter, чем идти мышью, выбирая путь).
1.2. Установка юзерскрипта — файла с расширением *.user.js
Юзерскрипт придётся оформить как простенькое расширение — «слепить» из файла *.user.js и файла манифеста manifest.json, за основу которого взять шаблон, в котором заменить вручную несколько полей, чтобы затем в списке расширений было удобно читать описание юзерскрипта (название, версию, описание. Затем оба файла положить в такую же поименованную папку, как в п. 1.1.2.
Всё это генерируется автоматически забрасыванием файла расширения на страницу chrome://extensions, как раньше. Лишь работать расширение не будет, и всё равно надо будет переходить к распакованному расширению по п. 1.3.1. Ручной процесс описан для понимания простоты и взаимосвязи юзерскрипта и расширения.
1.2.1. Скачать и получить файл юзерскрипта с расширением *.user.js.
1.2.2. Подготовить папку, например, c:\myFiles\chromeExtensions\habrPercentageRing\, в которую положить файл *.user.js.
1.2.3. В начале файла юзерскрипта посмотреть директивы скрипта — строчки вида
// @name . // @version . // @description . // @include . (может быть несколько) // @exclude . (может быть несколько) и заполнить данными (на месте троеточий) шаблон в файле manifest.json, который создать в той же новой папке.
Заготовка (шаблон) файла manifest.json:
< "content_scripts": [ < "exclude_globs": [ "все_домены_и_пути_из_exclude_директив" ], "exclude_matches": [ ], "include_globs": [ "все_домены_и_пути_из_include_директив" ], "js": [ "имя_файла_юзерскрипта.js" ], "matches": [ "http://*/*", "https://*/*" ], "run_at": "document_idle" >], "converted_from_user_script": true, "description": "описание_вашего_юзерскрипта", "key": "можно_удалить_не мешает", "name": "имя_вашего_юзерскрипта", "version": "номер_версии_юзерскрипта", "manifest_version": 2 > (заменяемые слова написаны одним словом с подчёркиваниями, чтобы удобно было выделять в редакторах двойным кликом);
номер_версии_юзерскрипта — до 4 чисел не более 32767, разделённые точками.
имя_файла_юзерскрипта.js — имя файла скрипта, лежащего рядом с файлом manifest.json
все_домены_и_пути_из_include_директив — в кавычках каждый, разделённые запятыми, со всеми метасимволами типа «*» — все пути из директив @include, которые пишутся в начале файла юзерскрипта;
все_домены_и_пути_из_exclude_директив — то же, для директив @exclude
Строчки без заменяемых слов должны присутствовать в манифесте, чтобы расширение на базе юзерскрипта работало. Все старательно внесённые данные помогут не запутаться в списке установленных расширений позже на странице chrome://extensions.
1.2.4. Установить расширение, как в п. 1.1.3.
1.3. Восстановление ранее установленного расширения или юзерскрипта
Если оказалось, что браузер «заупрямился» и отключил ранее установленное расширение, отказываясь выполнять его далее — не обязательно скачивать и устанавливать его снова.
1.3.1. Найдём каталог с этим расширением на системном диске (например, в WinXP — в каталоге С:\Documents and Settings\\, в Win7 — С:\Users\\ (открыть скрытые папки), используя длинное кодовое слово типа «gggcejmogjjjkpidlfinoaonmkpmegnn», написанное после слова «ID:» в блоке описания расширения.
1.3.2. Используем папку, которую браузер успел сделать ранее для этого расширения или юзерскрипта. Обычно, во вложенной папке имеется папка с номером версии расширения. Выбираем нужную — и загружаем как распакованное расширение (можно просто вставить путь к папке в поле Browse for Folder — Folder).
Лучше, конечно, перенести папки с ценными расширениями в другое место (как в прежних примерах, в c:\myFiles\chromeExtensions), иначе при удалении браузера из системы (или пользователя) они могут удалиться.
1.3.3. Это ещё не конец приключений — в расширении, сделанном на базе юзерскрипта, может быть не прописана в файле manifest.json строчка «manifest_version»: 2, о чём браузер скажет, отказываясь его установить. Пропишем
"manifest_version": 2,
в первом уровне структуры JSON эту пару «ключ-значение».
1.3.4. Загрузилось? Теперь не забудьте установить галочку «Включить».
(конец вариантов)
После подобных установок в списке расширений будет отображаться путь к каталогу, в котором находится каждое распакованное расширение. Как плюс для разработчиков, крайне просто его будет самостоятельно модифицировать. После модификации потребуется лишь ещё раз установить через кнопку «Загрузить распакованное расширение» (далее — выбрать каталог, в котором оно распаковано). Даже предварительно удалять имеющееся в списке — не обязательно. Действие сводится к нажатию 2 кнопок, если браузер помнит путь к каталогу расширения. Или просто нажать кнопку «Обновить расширения», если надо обновить все.
Да, работа ручная и бессмысленная — ранее это делал браузер. Чтобы её избежать, надо пользоваться «девелоперской» версией браузера, в котором по-прежнему можно ставить юзерскрипты затаскиванием или использовать другие «костыли» и прочие гениальные сложности. Перечисляем далее способы обеспечения установки расширений другими хитрыми путями.
Если будет желание «усовершенствовать» скрипт, превратив его в расширение, добавлением новых параметров в манифест, то тогда пропадёт важное преимущество юзерскрипта — его возможная кроссбраузерность, когда один и тот же скрипт может работать в 3 браузерах, включая старую Оперу. И в 4-м — Safari, если его таким же нехитрым путём заставить выглядеть как расширение Safari (по своим правилам, которые здесь описывать не будем).
Что ещё характерно — если у вас есть «легальное» точно такое же расширение Хрома из магазина WebStore с тем же именем и версией, оно не будет стираться распакованным вариантом расширения, а оба будут работать одновременно. Одно из них разумно отключить во избежание неожиданных эффектов «наложения».
Способ 2, «химия командной строки». Простой, но с неизвестной длительностью поддержки. Придётся запускать из специального ярлыка (shortcut).
2.1 Запустить браузер из командной строки с параметром «—enable-easy-off-store-extension-install». Это можно сделать из консоли, но удобнее для будущего — через ярлык, в котором дописывается параметр. Пример:
"C:\Program Files\Google\Chrome\Application\chrome.exe" --enable-easy-off-store-extension-install 2.2. Если был сделан ярлык с параметром — запускать браузер кликом по нему или комбинацией назначенных клавиш. Возможен незапуск, если в момент запуска работал скрытый процесс ранее запущенного Хрома без параметра (проверить и убить в менеджере задач, Ctrl-Shift-Esc). Скрытые процессы остаются, если установлена настройка в браузере «Продолжать работу приложений в фоновом режиме после закрытия браузера».
Способ 3, «химия реестра». Тоже простой, но с неизвестной длительностью поддержки. По отзывам, он работает в версии 35.0.1916.114 m, но не работает в версии Хрома 35.0.1916.153. Был описан 16.03.2014 в http://my-chrome.ru/2014/03/yes-we-can/. У некоторых работает и в обновлённых версиях старше 114 m, судя по отзывам, поэтому условия срабатывания ещё предстоит выяснять.
3.1. Для 64-битной Windows 7 в реестре по пути HKEY_LOCAL_MACHINE \ SOFTWARE \ Wow6432Node \ Google \ Update \ ClientState \ прописываем вместо ap: «-multi-chrome» или «1.1-beta-multi-chrome» (тип REG-SZ) значение «2.0-dev-multi-chrome» (без кавычек):
Для Win XP путь будет такой: HKEY_LOCAL_MACHINE \ SOFTWARE \ Google \ Update \ ClientState \
3.2. Повторить то же для папки и такого же параметра в ней.
Пишут, что может помочь и такое значение: «2.0-Canary-multi-chrome».
3.3. Перезапуск браузера, полный, с убиванием скрытых процессов. Признак того, что расширения стали работать — активный чекбокс для включения расширения.
(в данном примере кроссбраузерный юзерскрипт (для Хабра) был взят прямо из папки его использования в Firefox, и там же был добавлен manifest.json, что уменьшило количество размещений скрипта)
3.4. Включить расширение установкой чекбокса.
Смысл фокуса в том, что сообщаем браузеру, что это якобы DEV-версия браузера. Он, как побочный эффект, начинает хотеть обновиться до DEV-версии, что видно в попапе «About. ».
Если в реестре не нашлось этого пути — попробуйте поискать поиском по реестру значение «multi-chrome» и заменить все такие находки.
Способ 4, «троянский конь в магазине». Ставим расширение SimpleExtManager, после чего средствами настроек в этом расширении можем включать отключённые чекбоксы при именах всех расширений независимо от их происхождения. Нечаянно эта лазейка оказалась работающей. Правда, включать чекбоксы придётся при каждом полном (холодном) запуске браузера. Но всё равно, налицо — красивый троянский эффект, пусть и с ручным приводом.
Способ 5: ещё проще, но без перспектив: установить старую версию браузера Chrome и запретить в ней обновления.
Раз уж мы собрались рассмотреть все способы, рассмотрим и самые странные. Из комбинации двух нелогичных действий, действительно — получается решение. Первое нелогичное — обречь себя на устаревший браузер. Второе нелогичное — отключить обновления. От первого появляются дыры в безопасности, от второго — тоже. Но расширения будут жить. Может быть, кого-то тоже это устроит и кто-то давно мечтает отключить обновления Хрома, но до сих пор не знает, как.
Старые версии брать отсюда.
Для отключения обновлений подсказывают такой батник:
reg ADD "HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update" /v UpdateDefault /t REG_DWORD /d 0 /f reg ADD "HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update" /v AutoUpdateCheckPeriodMinutes /t REG_DWORD /d 0 /f reg ADD "HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update" /v DisableAutoUpdateChecksCheckboxValue /t REG_DWORD /d 1 /f reg ADD "HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update" /v Update /t REG_DWORD /d 0 /f Способ 6, «прикинься разработчиком». Эту возможность оставил тебе Гугл. Если пользоваться версией браузера, скачанной с Dev- или Canary- канала, ограничения работоспособности немагазинных расширений не будет. Canary не будет конфликтовать с установленным в системе Хромом стабильной версии.
Минусы — очевидно, в том, что надо заново собирать свои настройки браузера, а затем следить за версиями и переходить на новые. Не всем «жизнь ради браузера» подходит.
Добрый Гугл обещает не запрещать установку расширений в Dev Channel и Canary-версиях. Тут всё логично: на эксперименты идут разработчики, маргиналы, а они знают, чем грозит установка непроверенных расширений. Другим же рекомендовать это не с руки, потому что выглядит как принудительное привязывание к непроверенным, сырым версиям браузера. Даже большинству разработчиков это не нужно — у каждого есть много других задач и увлечений… Но, продолжим парад странностей.
Способ 7, «думай иначе» («think different»). Свежая мысль Apple: «Зачем нам Windows?». Ох, как же это банально! Переходим на Mac или Linux.
Способ 8, «думай иначе, но в Windows». Даже так? Да. Переходим на другой браузер, основанный на Chromium. Если он поддерживает расширения, то он не будет иметь залочивания расширений на гугловском магазине.
Первый кандидат для выбора — это, конечно, Chromium: браузер, служащий основой для Chrome, но без закрытых (с точки зрения кодов и политики компании) технологий Google.
Способ 9, «будь боссом». Для уважаемых владельцев корпоративных сетей предприятия (громко сказано, но всё гораздо проще) есть способ иметь собственный домен, с которого пользователи могут установить расширения.
Способ 10, «шаблоны политик». Перевод и инструкции будут на днях (27.06.2014), пока что — ссылка (англ.) на оригинал, присланная читателем kvark (не с Хабра). Способ сложен в настройке и прописывании каждого расширения на начальном этапе, зато не требует, как в способе 1, подтверждения при каждом запуске браузера.
В сравнении с вышеперечисленными способами — лучше не усложнять себе жизнь, если нет реальной необходимости придерживаться браузера Chrome и политики предприятия по установке расширений.
- Chrome — такой Chrome
- Google Chrome
- JavaScript
- GreaseMonkey
- Расширения для браузеров
Создание расширения браузера Google Chrome для извлечения всех изображений web-страницы. Часть 1
Расширения браузера — это web-приложения, которые устанавливаются в web-браузер, чтобы расширить его возможности. Обычно, для того чтобы воспользоваться расширением, пользователю нужно найти его в Chrome Web Store и установить.
В этой статье я покажу как создать расширение для браузера Google Chrome с нуля. Это расширение будет использовать API браузера, для того чтобы получить доступ к содержимому web-страницы любой открытой вкладки. С помощью этих API можно не только читать информацию с открытых web-сайтов, но и взаимодействовать с этими страницами, например, переходить по ссылкам или нажимать на кнопки. Таким образом расширения браузера могут использоваться для широкого круга задач автоматизации на стороне клиента, таких как web-scrape или даже автоматизированное тестирование frontend.
Мы создадим расширение, которое называется Image Grabber. Оно будет содержать интерфейс для подключения к web-странице и для извлечения из нее информации о всех изображениях. Далее, при нажатии на кнопку «GRAB NOW» список абсолютных URL этих изображений будет скопирован в буфер обмена. В этом процессе вы познакомитесь с фундаментальными строительными блоками, которые в дальнейшем можно будет использовать для создания других расширений.
Расширения, создаваемые таким образом для браузера Chrome совместимы с другими браузерами, основанными на движке Chromium и могут быть установлены, например, в Yandex-браузер или Opera.
В результате при правильном выполнении всех шагов, вы получите расширение, которое будет выглядеть и работать так, как показано на следующем видео:
Это только первая часть истории. Во второй части я покажу, как расширить интерфейс, чтобы выгрузить все или выбранные изображения в виде ZIP-архива, а также, как опубликовать свое расширение в Chrome Web Store.
Базовая структура расширения
Расширение Google Chrome — это web-приложение, содержащее любое количество HTML-страниц, файлов CSS и изображений, а также, файл manifest.json, который определяет как расширение выглядит и работает. Все эти файлы должны быть в одной папке.
Минимальное расширение состоит только из одного файла manifest.json. Вот пример этого файла, который вы можете использовать как шаблон при начале создания любого расширения:
< "name": "Image Grabber", "description": "Extract all images from current web page", "version": "1.0", "manifest_version": 3, "icons": <>, "action": <>, "permissions": [], "background":<> >Здесь только manifest_version должен быть равен 3. Остальные поля заполняются произвольно в зависимости от назначения расширения: name — название расширения, description — краткое описание, version — версия. Остальные параметры мы будем заполнять по ходу разработки интерфейса. Полный список параметров manifest.json можно найти в официальной документации.
Папка с одним файлом manifest.json — это минимальное расширение, которое может быть установлено в Google Chrome и запущено. Оно ничего не будет делать, однако именно с установки нужно начинать. Поэтому создайте папку image_grabber, затем добавьте в нее текстовый файл manifest.json с содержимым приведенным выше.
Установка расширения
В процессе разработки расширения, оно представляет собой папку с файлами. В терминологии Google Chrome это называется «unpacked extension». После завершения разработки, его нужно упаковать в ZIP-архив и загрузить в Chrome Web Store, откуда оно потом может быть установлено в браузер.
Однако на этапе разработки, «unpacked extension» тоже можно установить, просто как папку с файлами. Для этого нужно ввести chrome://extensions в браузере, чтобы открыть Chrome Extensions Manager:

Это покажет список уже установленных расширений. Чтобы устанавливать в него «unpacked extensions», включите флажок «Developer mode» в правом верхнем углу. После этого должна отобразиться панель управления расширениями.

Затем нажмите первую кнопку Load unpacked и укажите папку, в которой находится расширение с файлом manifest.json. В нашем случае это папка image_grabber. Расширение должно отобразиться в списке:
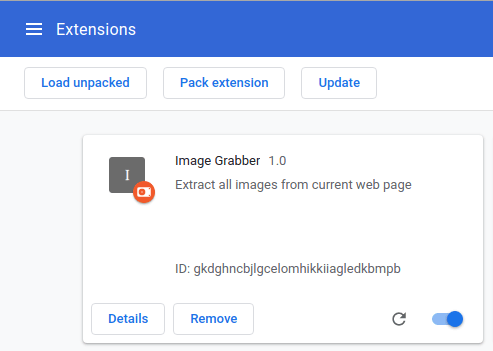
Эта панель должна показывать данные расширения такие как имя, описание и версию, ранее указанные в manifest.json, а также уникальный идентификатор, присвоенный этому расширению. Каждый раз после изменения manifest.json и файлов, непосредственно указанных в нем, нужно обновлять расширение в браузере, нажимая на кнопку «Reload«:

Чтобы запустить и использовать установленное расширение в браузере, нажмите кнопку Extensions на панели инструментов Google Chrome рядом с URL и найдите «Image Grabber» в списке установленных расширений:

Также можно нажать иконку Pin в списке рядом с расширением, чтобы добавить кнопку данного расширения на панель Chrome, рядом с другими расширениями:


Вот как выглядит минимальное расширение — кнопка с серым прямоугольником и буквой внутри. При нажатии на эту кнопку ничего не происходит. Давайте заполним остальные поля файла manifest.json, чтобы изменить картинку расширения и заставить его выполнять нужные действия.
Добавление иконок
Параметр icons файла manifest.json принимает объект JavaScript, ключами которого являются размеры иконок, а значениями пути к файлам с этими иконками. Иконка это картинка с расширением PNG (для прозрачности). Расширение должно иметь иконки разных размеров: 16×16, 32×32, 48×48 и 128×128. Я создал иконки для всех этих размеров и поместил их в папку «icons» внутри папки с расширением. Сделайте то же самое. Имена файлов могут быть любыми:
< "name": "Image Grabber", "description": "Extract all images from current web page", "version": "1.0", "manifest_version": 3, "icons": < "16":"icons/16.png", "32":"icons/32.png", "48":"icons/48.png", "128":"icons/128.png" >, "action": <>, "permissions": [], "background":<> >Как видно, здесь указаны относительные пути к файлам в папке icons.
После изменения manifest.json нажмите кнопку «Reload» на панели расширения Image Grabber в Chrome Extensions Manager, чтобы обновить установленное расширение. Если все сделано как описано выше, то картинка на кнопке расширения должна измениться:

Так значительно лучше, однако когда мы нажимаем на эту кнопку все еще ничего не происходит. Пришло время добавить «действия» (actions) к расширению.
Создание интерфейса расширения
Расширение должно что-то делать, то есть запускать определенные действия. Расширение может выполнять действия двумя способами:
- В фоне, при запуске расширения и при дальнейшей его работе
- Из интерфейса, когда пользователь нажимает кнопку расширения и затем взаимодействует с различными интерфейсными элементами.
Расширение может использовать обе эти возможности одновременно.
Чтобы запускать действия в фоне, нужно создать Javascript-файл и указать путь к нему в параметре «background» файла manifest.json. Этот скрипт может содержать функции обработчики различных событий браузера и жизненного цикла самого расширения. Background-скрипт слушает эти события и запускает написанные для них функции обработчики.
Однако в этом расширении мы этим пользоваться не будем и параметр «background» останется пустым. Он присутствует только для того, чтобы показать что это возможно и что данный файл manifest.json может использоваться для создания расширений любого типа. Однако расширение Image Grabber выполняет действия только когда пользователь нажимает кнопку «GRAB NOW» из интерфейса.
Соответственно мы создадим интерфейс для расширения. Интерфейс расширения это фактически Web-сайт, состоящий из HTML-страниц с элементами управления, CSS-таблиц стилей и скриптов, которые реагируют на события элементов управления из этих HTML-страниц и выполняют определенные действия, используя в частности API расширений Google Chrome.
Интерфейс должен содержать главную страницу, которая появляется при нажатии на кнопку расширения. Эта страница может появляться либо в новой вкладке браузера, либо внутри всплывающего окна, как было показано на видео. Именно так и будет реализован интерфейс Image Grabber. Чтобы создать интерфейс всплывающего окна, внесите следующие изменения в manifest.json:
< "name": "Image Grabber", "description": "Extract all images from current web page", "version": "1.0", "manifest_version": 3, "icons": < "16":"icons/16.png", "32":"icons/32.png", "48":"icons/48.png", "128":"icons/128.png" >, "action": < "default_popup":"popup.html" >, "permissions": [], "background":<> >Здесь определено, что основное действие (action) расширения это всплывающее окно (popup), которое содержит страницу popup.html.
Теперь создайте файл popup.html с заголовком Image Grabber и кнопкой «GRAB NOW» и поместите его в папку с расширением:
Image Grabber Image Grabber
Кнопка имеет идентификатор grabBtn который в дальнейшем будет использоваться из скрипта, чтобы реагировать на нажатия.
Чтобы увидеть, что изменилось, снова обновите расширение в Chrome Extensions Manager. Если все было сделано как написано выше, то при нажатии на иконку расширения будет появляться содержимое файла popup.html во всплывающем окне:
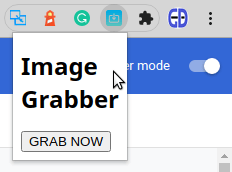
Работает!! Но выглядит не очень. Теперь нужно стилизовать этот интерфейс с помощью CSS.
Создайте файл popup.css со следующим содержимым и поместите его в папку с расширением:
body < text-align:center; width:200px; >button
Этот файл определяет стили для кнопки и для body всей страницы: все содержимое выровнено по центру, а также, ширина содержимого будет 200 пикселей.
Добавьте ссылку на файл с этими стилями в popup.html:
Image Grabber Image Grabber
Теперь при нажатии на кнопку расширения появится стилизованный интерфейс:

Обратите внимание, что в данном случае не требовалось нажимать кнопку Reload, для того чтобы обновить расширение. Изменения в файлах web-интерфейса расширения начинают работать автоматически.
Чтобы придать интерфейсу завершенность, добавим JavaScript-код, который будет реагировать на нажатия кнопки «GRAB NOW«. Создайте файл popup.js в папке с расширением со следующим содержимым:
const grabBtn = document.getElementById("grabBtn"); grabBtn.addEventListener("click",() => < alert("CLICKED"); >)и добавьте ссылку на этот файл в popup.html:
Image Grabber Image Grabber
Таким образом мы добавили событие onClick для кнопки с идентификатором «grabBtn«. Теперь, при нажатии на кнопку «GRAB NOW» в интерфейсе, должно появляться предупреждение «CLICKED».
В результате мы имеем такую файловую систему расширения:

Это все файлы, других больше добавлять не будем. Такую структуру можно использовать как базу для создания расширений Google Chrome с интерфейсом основанном на всплывающих окнах.
Теперь реализуем бизнес логику расширения: при нажатии на кнопку «GRAB NOW» расширение должно извлечь список путей ко всем картинкам текущей страницы в браузере и скопировать этот список в буфер обмена.
Функция «GRAB NOW»
Используя Javascript в расширении можно делать все то же самое, что и при использовании JavaScript на web-сайте, например открывать различные web-страницы из текущей или делать AJAX HTTP-запросы к различным серверам. Но в дополнении к этому, Javascript-код в расширении браузера может использовать различные API Chrome для взаимодействия с компонентами самого браузера. Большинство этих API доступно через пространство имен chrome . В частности, расширение Image Grabber будет использовать следующие API:
- chrome.tabs — Chrome Tabs API. Будет использоваться для доступа к активной вкладке браузера.
- chrome.scripting — Chrome Scripting API. Будет использоваться для внедрения кода JavaScript на web-страницу активной вкладки и для исполнения этого кода в контексте этой страницы.
Получение необходимых разрешений
По умолчанию, из соображений безопасности, расширение Chrome не имеет доступа ко всем API браузера. Необходимо запросить этот доступ через механизм разрешений. Для этого нужно указать список требуемых разрешений в параметре permissions в файле manifest.json. Существует множество различных разрешений, которые описаны здесь: https://developer.chrome.com/docs/extensions/mv3/declare_permissions/. Для Image Grabber нужно указать следующие из них:
- activeTab — разрешение для получения доступа к текущей вкладке браузера.
- scripting — разрешение для получения доступа к Chrome Scripting API для исполнения скриптов в контексте Web-страницы, открытой в браузере.
Добавьте эти разрешения в параметр permissions в файле manifest.json:
< "name": "Image Grabber", "description": "Extract all images from current web page", "version": "1.0", "manifest_version": 3, "icons": < "16":"icons/16.png", "32":"icons/32.png", "48":"icons/48.png", "128":"icons/128.png" >, "action": < "default_popup":"popup.html", >, "permissions": ["scripting", "activeTab"], "background":<> >и обновите расширение в Chrome Extensions Manager.
Между тем, листинг выше — это окончательный вариант файла manifest.json для расширения. Теперь здесь есть все: название, описание, версия, иконки, ссылка на главную страницу интерфейса и разрешения на доступ к браузеру, которые этому интерфейсу необходимы.
Получение информации об активной вкладке браузера
Для получения информации о вкладках браузера используется функция chrome.tabs.query , которая определена следующим образом:
chrome.tabs.query(queryObject,callback)- queryObject — объект запроса в котором указываются параметры поиска нужных вкладок.
- callback — функция обратного вызова, которая выполняется после выполнения этого запроса. В нее передается массив tabs , содержащий все найденные вкладки, соответствующие критерию запроса. Каждый элемент этого массива — это объект типа Tab , содержащий информацию о вкладке, включая ее уникальный идентификатор. Этот идентификатор будет использоваться для исполнения Javascript-кода на этой вкладке.
Здесь я не буду полностью описывать синтаксис queryObject , а также все поля возвращаемых объектов Tabs . Эту информацию можно найти в официальной документации по chrome.tabs : https://developer.chrome.com/docs/extensions/reference/tabs/.
Для расширения Image Grabber нужно получить только активную вкладку. Для этой цели queryObject должен быть определен как: .
Теперь давайте изменим код обработчика нажатия кнопки grabBtn в popup.js чтобы он получал активную вкладку и ее идентификатор, когда пользователь нажимает на кнопку «GRAB NOW» в интерфейсе расширения:
const grabBtn = document.getElementById("grabBtn"); grabBtn.addEventListener("click",() => < chrome.tabs.query(, (tabs) => < const tab = tabs[0]; if (tab) < alert(tab.id) >else < alert("There are no active tabs") >>) >)Этот код выполняет запрос ко всем вкладкам, которые активны. Может быть только одна такая вкладка, поэтому к ней можно обратиться как tabs[0] . Если такая вкладка существует, то функция отображает ее id, а если не существует, то показывает сообщение об ошибке.
Если все сделано как описано выше, то при нажатии кнопки GRAB NOW должен появляться идентификатор текущей вкладки браузера. Далее мы изменим этот код таким образом, чтобы этот идентификатор использовался для доступа к web-странице, открытой на этой вкладке.
Извлечение изображений из текущей страницы
Расширение может взаимодействовать с открытыми страницами с помощью интерфейса Chrome Scripting API, доступного через chrome.scripting . В частности, мы будем использовать функцию для внедрения своего кода в текущую web-страницу и для исполнения этого кода в ее контексте. При запуске этот код будет иметь доступ к DOM-дереву этой страницы и сможет делать нужные нам действия с любыми HTML-тэгами.
Для внедрения скрипта в страницу Web-браузера используется функция executeScript , определенная следующим образом:
chrome.scripting.executeScript(injectSpec,callback)Рассмотрим ее параметры.
injectSpec
Это объект типа ScriptInjection. В нем определяется какой Javascript-код, в какую web-страницу и каким образом внедрить. В частности, в параметре target указывается идентификатор вкладки браузера со страницей, которая нам нужна. Мы получили его ранее. Остальные параметры указывают каким образом передать скрипт на эту страницу. Возможно использовать следующие параметры для передачи скрипта:
- files — указывается список путей к JS-файлам, которые нужно внедрить, относительно корневой папки расширения
- func — указывается Javascript-функция, которую нужно внедрить. Функция должна быть предварительно написана.
Скрипт, который планируется внедрить, будет извлекать список изображений с web-страницы и возвращать список URL этих изображений. Это небольшой скрипт, поэтому достаточно создать функцию для него. Она будет называться grabImages . Эта функция должна извлекать список URL изображений web-страницы и возвращать его. Возвращаемое значение этой функции будет передано расширению.
В итоге injectSpec будет определен следующим образом:
< target:< tabId: tab.id, allFrames: true >, func: grabImages, >, Здесь функция, указанная в параметре func будет внедрена на страницу, определенную параметром target . В параметре target указывается полученный на предыдущем этапе идентификатор вкладки, а также, устанавливается параметр allFrames . Этот дополнительный параметр говорит что скрипт должен выполняться во всех фреймах web-страницы, в случае если они на этой странице есть.
Саму функцию grabImages мы напишем чуть позже.
callback
Это функция обратного вызова, которая будет вызвана после того, как внедренный скрипт исполнится на странице и во всех ее фреймах. В качестве параметра в ней будет массив результатов, которые вернула функция grabImages для каждого фрейма (возможно это будет всего один элемент, если фреймов нет). Каждый элемент этого массива — это объект типа InjectionResult. Он в частности содержит свойство result . Именно оно содержит то, что возвращает функция grabImages, т.е. список URL-ов.
Теперь соберем все вместе в следующем коде:
const grabBtn = document.getElementById("grabBtn"); grabBtn.addEventListener("click",() => < chrome.tabs.query(, function(tabs) < var tab = tabs[0]; if (tab) < chrome.scripting.executeScript( < target:, func:grabImages >, onResult ) > else < alert("There are no active tabs") >>) >) function grabImages() < // TODO - Запросить список изображений // и вернуть список их URL-ов >function onResult(frames) < // TODO - Объединить списки URL-ов, полученных из каждого фрейма в один, // затем объединить их в строку, разделенную символом перевода строки // и скопировать в буфер обмена >Функция grabImages может быть определена следующим образом:
/** * Функция исполняется на удаленной странице браузера, * получает список изображений и возвращает массив * путей к ним * * @return Array массив строк */ function grabImages() < const images = document.querySelectorAll("img"); return Array.from(images).map(image=>image.src); >Здесь все просто: получаем список DOM-элементов и извлекаем свойство src каждого из них в итоговый массив. Считаю нужным напомнить, что объект document , указанный в этой функции указывает на содержимое не той HTML-страницы, где находится функция grabImages , а удаленной web-страницы, в которую эта функция будет внедрена.
После того как данная функция выполнится в каждом фрейме, результаты будут объединены в единый массив и переданы в функцию onResult . Эта функция может быть определена следующим образом:
/** * Выполняется после того как вызовы grabImages * выполнены во всех фреймах удаленной web-страницы. * Функция объединяет результаты в строку и копирует * список путей к изображениям в буфер обмена * * @param <[]InjectionResult>frames Массив результатов * функции grabImages */ function onResult(frames) < // Если результатов нет if (!frames || !frames.length) < alert("Could not retrieve images from specified page"); return; >// Объединить списки URL из каждого фрейма в один массив const imageUrls = frames.map(frame=>frame.result) .reduce((r1,r2)=>r1.concat(r2)); // Скопировать в буфер обмена полученный массив // объединив его в строку, используя символ перевода строки // как разделитель window.navigator.clipboard .writeText(imageUrls.join("\n")) .then(()=>< // закрыть окно расширения после // завершения window.close(); >); >Следует упомянуть что не все вкладки браузера — это вкладки с web-страницами. Например, может быть вкладка свойств браузера. Страницы на таких вкладках не имеют свойства document . В этом случае функция grabImages не выполнится и не вернет результатов. Этот случай обрабатывается в самом начале функции. Затем массив массивов результатов объединяется в единый плоский массив используя концепцию map/reduce, затем функция window.navigator.clipboard используется, чтобы скопировать его в буфер обмена. Предварительно массив результатов преобразовывается в строку, разделенную символом перевода строки.
Завершающие штрихи
Здесь я описал только незначительную часть Chrome Scripting API и описал только в контексте данного расширения. Полная документация по Chrome Scripting API доступна здесь: https://developer.chrome.com/docs/extensions/reference/scripting/.
Теперь немного почистим код. Здесь я считаю нужным часть функции обработчика grabBtn, которая выполняет chrome.scripting.executeScript вынести в отдельную функцию execScript . В результате файл popup.js выглядит так:
const grabBtn = document.getElementById("grabBtn"); grabBtn.addEventListener("click",() => < // Получить активную вкладку браузера chrome.tabs.query(, function(tabs) < var tab = tabs[0]; // и если она есть, то выполнить на ней скрипт if (tab) < execScript(tab); >else < alert("There are no active tabs") >>) >) /** * Выполняет функцию grabImages() на веб-странице указанной * вкладки и во всех ее фреймах, * @param tab Объект вкладки браузера */ function execScript(tab) < // Выполнить функцию на странице указанной вкладки // и передать результат ее выполнения в функцию onResult chrome.scripting.executeScript( < target:, func:grabImages >, onResult ) > /** * Получает список абсолютных путей всех картинок * на удаленной странице * * @return Array Массив URL */ function grabImages() < const images = document.querySelectorAll("img"); return Array.from(images).map(image=>image.src); > /** * Выполняется после того как вызовы grabImages * выполнены во всех фреймах удаленной web-страницы. * Функция объединяет результаты в строку и копирует * список путей к изображениям в буфер обмена * * @param <[]InjectionResult>frames Массив результатов * функции grabImages */ function onResult(frames) < // Если результатов нет if (!frames || !frames.length) < alert("Could not retrieve images from specified page"); return; >// Объединить списки URL из каждого фрейма в один массив const imageUrls = frames.map(frame=>frame.result) .reduce((r1,r2)=>r1.concat(r2)); // Скопировать в буфер обмена полученный массив // объединив его в строку, используя возврат каретки // как разделитель window.navigator.clipboard .writeText(imageUrls.join("\n")) .then(()=>< // закрыть окно расширения после // завершения window.close(); >); >Заключение
Теперь, если нажать по иконке расширения Image Grabber и затем кликнуть кнопку GRAB NOW, то в буфере обмена будет список URL-ов всех изображений текущей web-страницы. Можно вставить его в любой текстовый редактор.
Для начала, возможно, неплохо, но практическая ценность такого расширения не велика. Поэтому в следующей части я покажу как выгрузить все эти изображения в виде zip-архива, а также, создать дополнительный интерфейс, для того чтобы выбрать какие картинки добавлять в этот ZIP-архив, а какие нет. Также опишу процесс публикации готового расширения в Chrome Store.
Поэтому подписывайтесь, думаю к концу следующей недели вторая часть будет доступна вместе с полным исходным кодом.
Вторая часть опубликована и доступна здесь.