Парсинг сайта с помощью Excel
На первый взгляд Excel и парсинг понятия несовместимые. Как с помощью табличного редактора можно получать информацию из сети? И ведь многие недооценивают Excel, а это вполне посильная задача для него. При этом все делается стандартными методами без необходимости дополнительно что-то устанавливать/настраивать.
20K открытий
Разберем на конкретном примере по получению информации с сайта Минюста, а именно, нам необходим перечень действующих адвокатов Российской Федерации. Кнопки «выгрузить списочно всех адвокатов» — конечно же, нет. На официальном сайте http://lawyers.minjust.ru/ выводится по 20 адвокатов на 1 странице, всего 74 754 страниц, итого на выходе мы должны получить чуть меньше 150 тыс. адвокатов.
Для начала открываем VBA и создаем объект InternetExplorer, посредством которого будем получать данные.
Затем надо определить, как будем переходить между страницами на сайте – для этого просматриваем элемент перехода на следующую страницу. Ссылка между станицами отличается значением в конце и соответствует номеру страницы – 1.
Имея информацию о ссылке страницы — осуществляем их перебор, загружаем в InternetExplorer и забираем все данные со страницы.
В коде страницы представлена структура таблицы со всеми столбцами, которые нам необходимы: реестровый номер, ФИО адвоката, субъект РФ, номер удостоверения, текущий статус.
Для получения этой информации с помощью ключевых слов осуществляем поиск по тегам и забираем требуемые данные.
В итоге получаем список всех адвокатов в таблицу Excel для дальнейшей обработки.
Парсер таблиц Excel
Обработать все файлы Excel в заданной папке, и извлечь информацию из определенных ячеек.
Искать в файлах данные не привязываясь к адресам ячеек (структура файлов немного отличается, часть данных смещена)
| Настройки парсера для обработки файлов Excel | 2.95 КБ |
| Архив с файлами Excel для обработки (извлечь в любую папку) | 85.15 КБ |
| Пример результата в таблице Excel | 10.63 КБ |
ИНСТРУКЦИЯ: Как добавить файл настроек в парсер
Этот парсер опубликован как пример использования парсера для обработки файлов, в частности, для парсинга таблиц Excel.
В качестве основы был использован парсер для перебора всех файлов в папке, но с незначительным отличием: если при парсинге файлов других типов (текстовых / Word / PDF) нам достаточно только считать данные из файла (файл временно открывается, данные считываются, и файл сразу закрывается), то при загрузке данных из файлов Excel, обрабатываемый файл должен быть открыт всё то время, пока из него считываются данные в разные столбцы.
Подробнее об этом — в инструкции по парсингу файлов Excel
Для извлечения данных с листа используется многофункциональное действие «Поиск ячеек на листе».
Оно позволяет найти на листе нужные ячейки, ориентируясь на значения соседних ячеек (например, найти на листе ячейку с заданным текстом, отступить от неё вниз/вправо/влево/вверх на заданное количество строк/столбцов, и из этой ячейки считать значение / ссылку / примечание)
Поскольку некоторые из обрабатываемых файлов могут отличаться по структуре (присутствует первый пустой столбец), необходима дополнительная коррекция файла перед обработкой (при условии, что в первом столбце меньше 5 заполненных ячеек, надо значения ячеек первого столбца перенести во второй столбец, а первый столбец листа целиком удалить). Это тоже можно сделать парсером, — в настройках этого парсера присутствует набор действий «Коррекция файла», содержащий 5 команд:
| Действие | Параметр | Значение |
|---|---|---|
| Поиск ячеек на листе | Адрес ячейки / диапазона для поиска | a1:a15 |
| Маска поиска | ?* | |
| Смещение от найденного | 0;0 | |
| Действие для целевой ячейки | GetValue | |
| Задаваемое значение | ||
| Маска найденного значения | * | |
| Заменять пустые значения на | ||
| Количество элементов массива | Сохранить результат в переменную | |
| Использовать новое значение | да | |
| Проверка на выполнение условия | Режим проверки | больше |
| Значение для сравнения | 5 | |
| Действие при выполнении условия | Новое значение, и остановить | |
| Параметр действия | Коррекция не требуется (первый столбец не пустой) | |
| Проверять другое значение | нет | |
| Другое проверяемое значение | ||
| Поиск ячеек на листе | Адрес ячейки / диапазона для поиска | a:a |
| Маска поиска | ?* | |
| Смещение от найденного | 0;1 | |
| Действие для целевой ячейки | SetValue | |
| Задаваемое значение | ||
| Маска найденного значения | * | |
| Заменять пустые значения на | ||
| Действия со столбцами | Столбцы | 1 |
| Действие для выбранных столбцов | Удалить | |
| Параметр действия |
Статья является примером использования программы «Парсер сайтов и файлов» для решения нижеописанной задачи.
Парсер сайтов и файлов (парсинг данных с сайта в Excel)

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
На видео рассказывается о работе с программой, и показан процесс настройки парсера интернет-магазина:
Парсинг нетабличных данных с сайтов
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК: 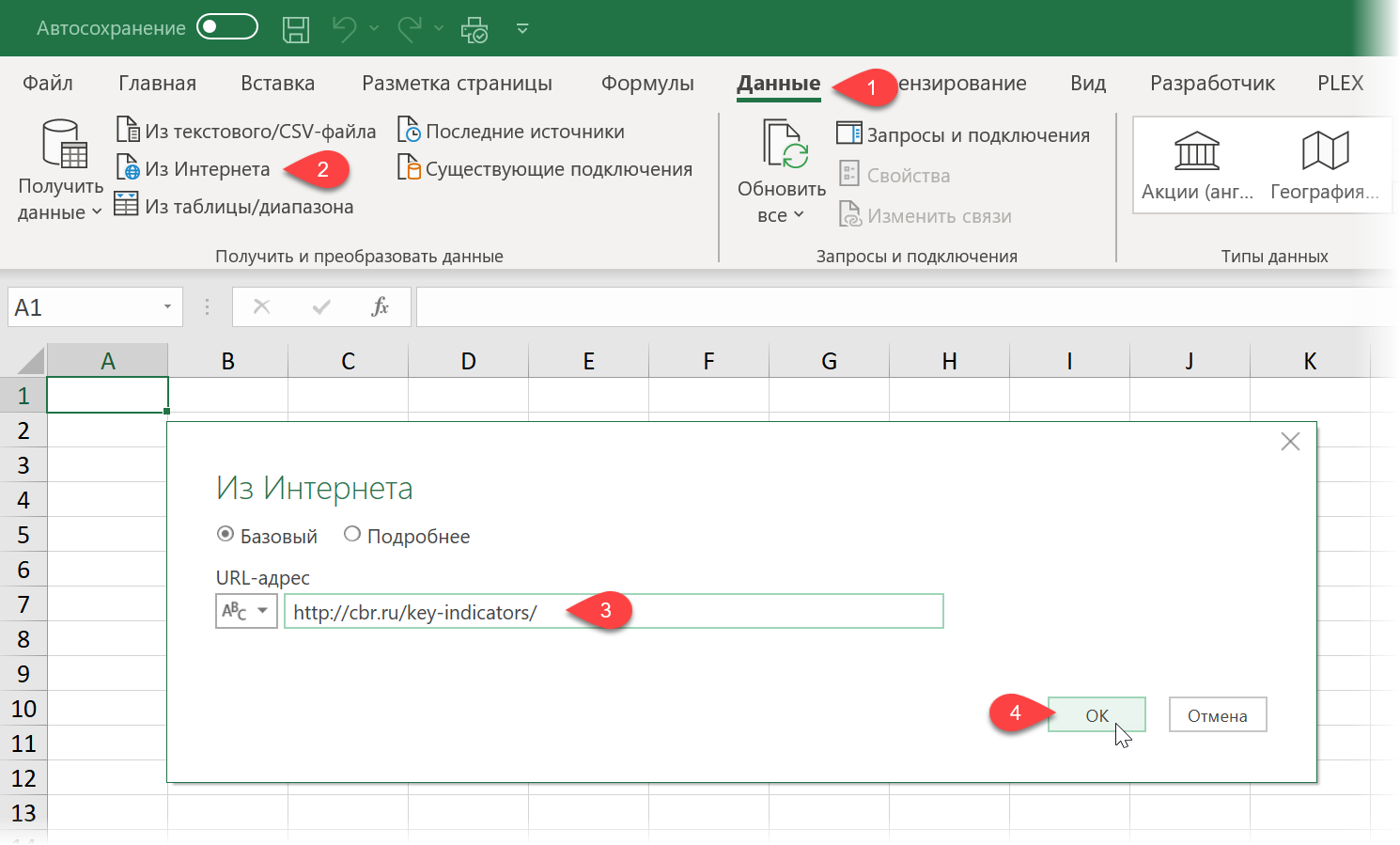
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора: 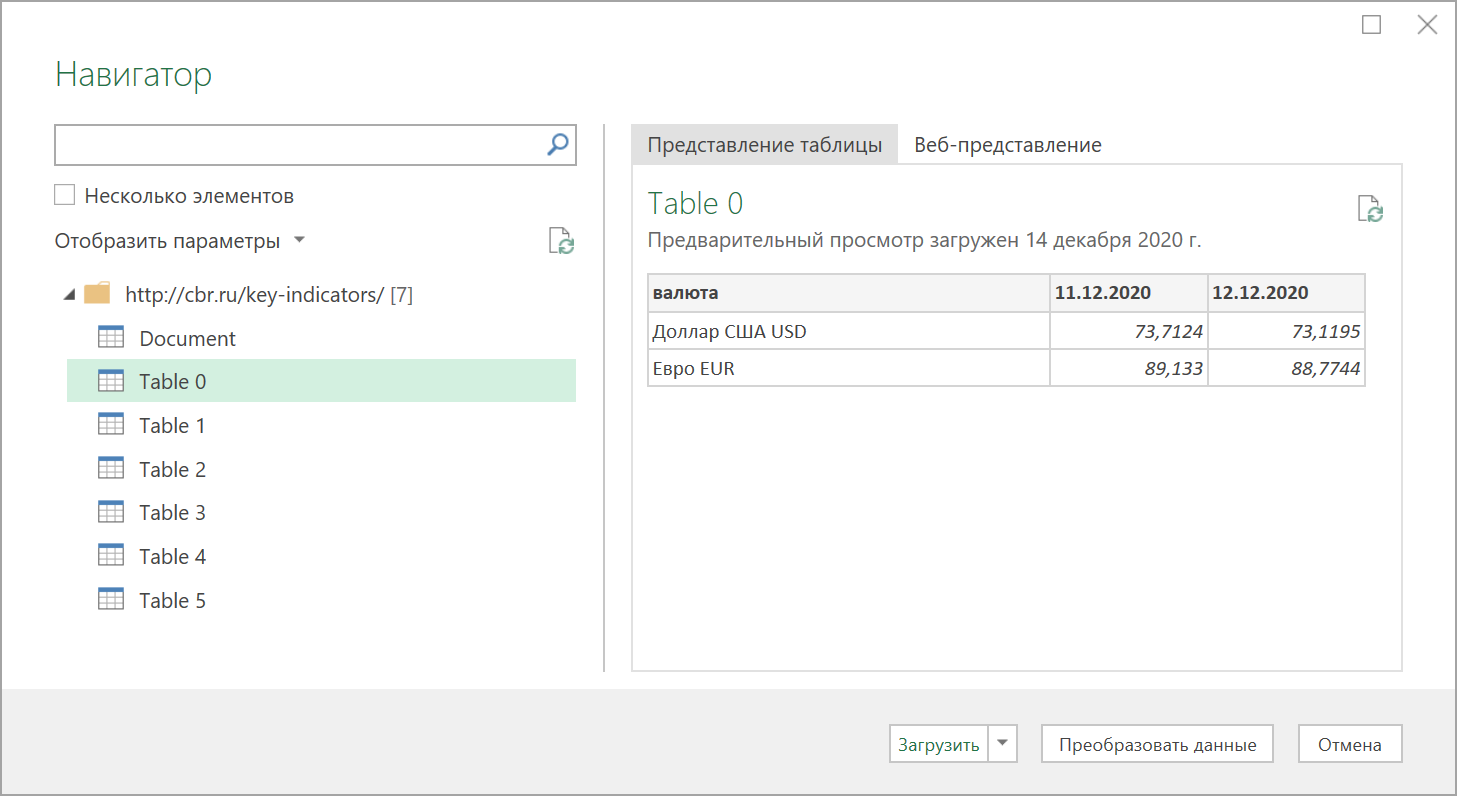
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2. или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом , а её аналог — вложенные друг в друга теги-контейнеры . Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel. Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы: 
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы: https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document: 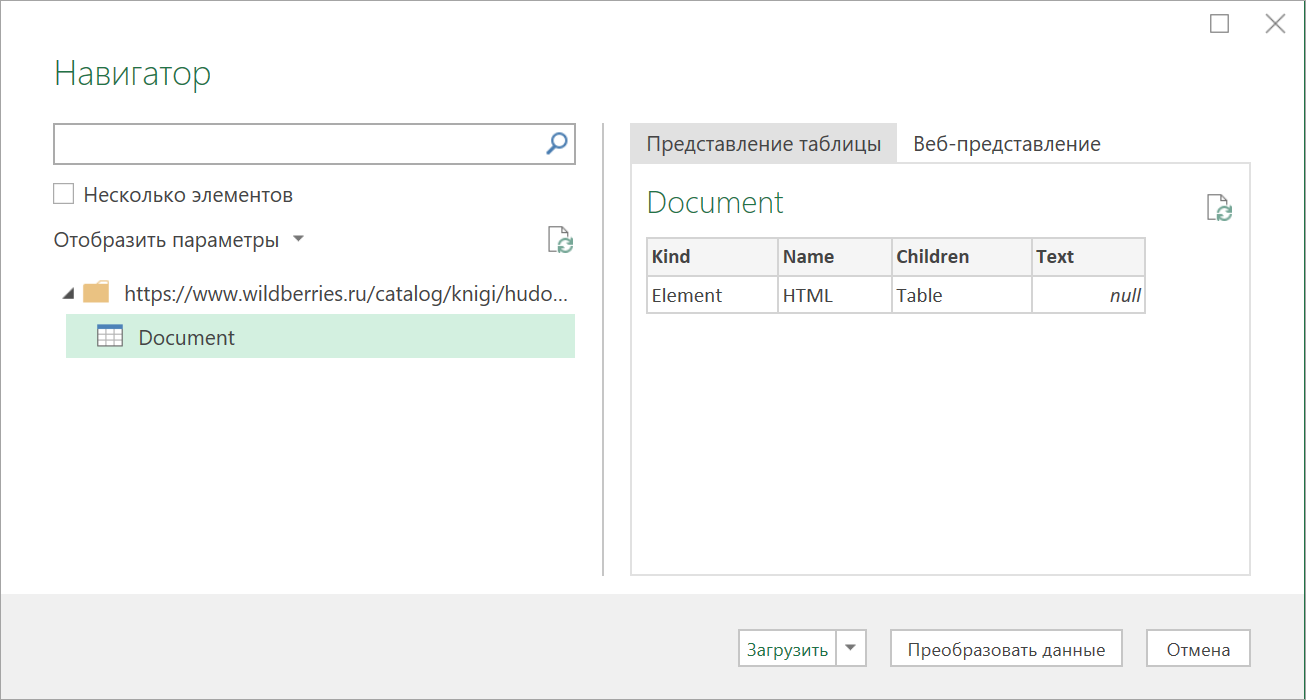
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data) , чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом: 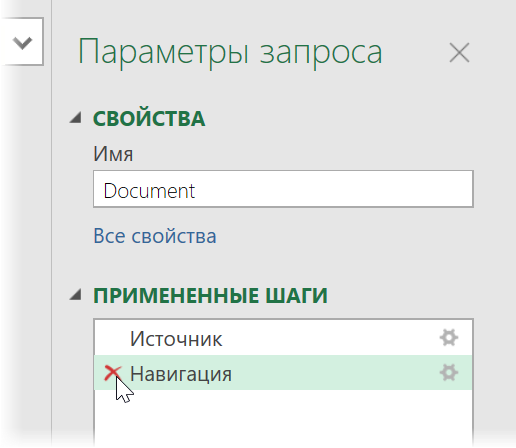
. и затем щёлкаем по значку шестерёнки справа от шага Источник (Source) , чтобы открыть его параметры: 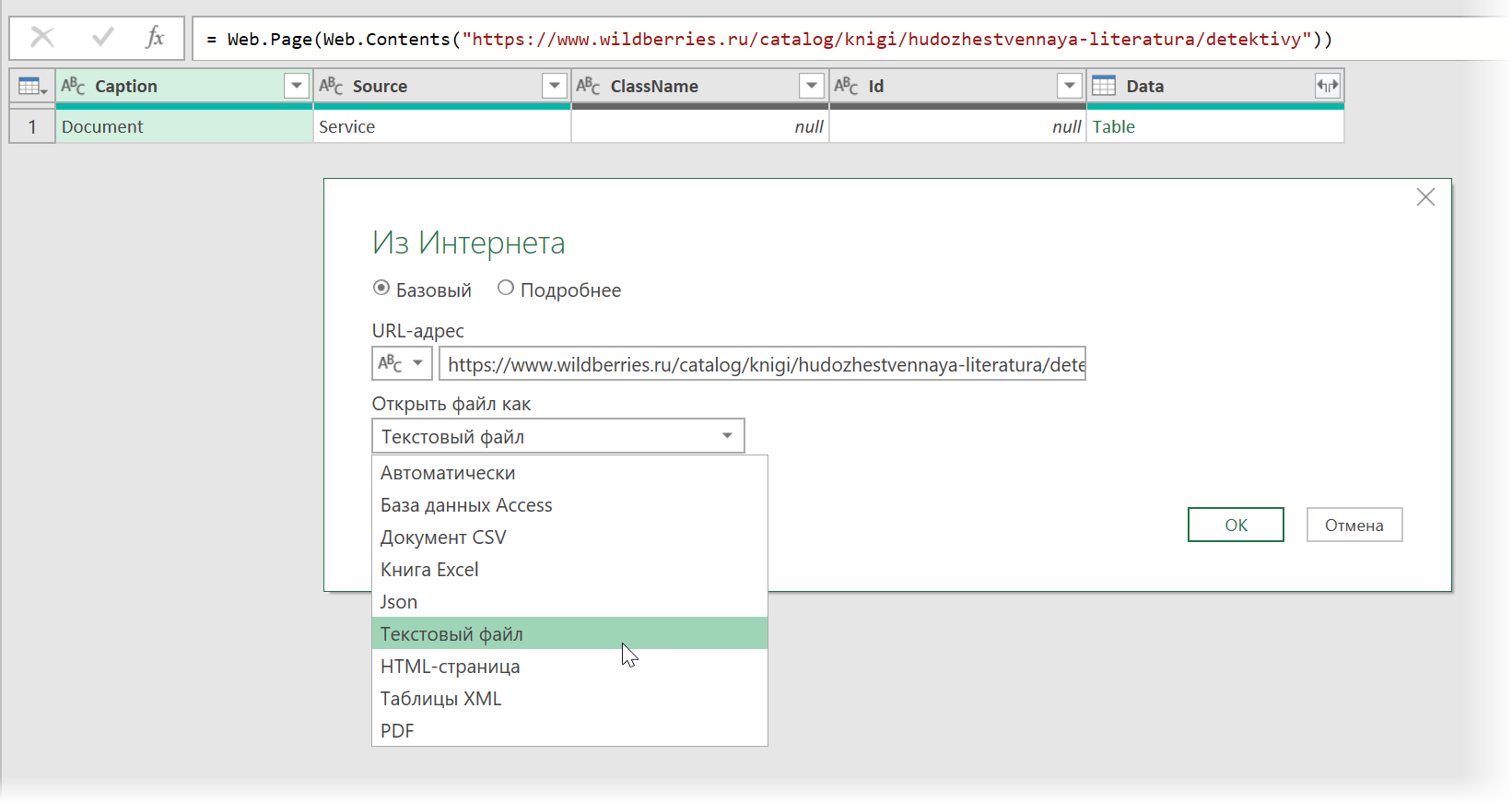
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file) . Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь): 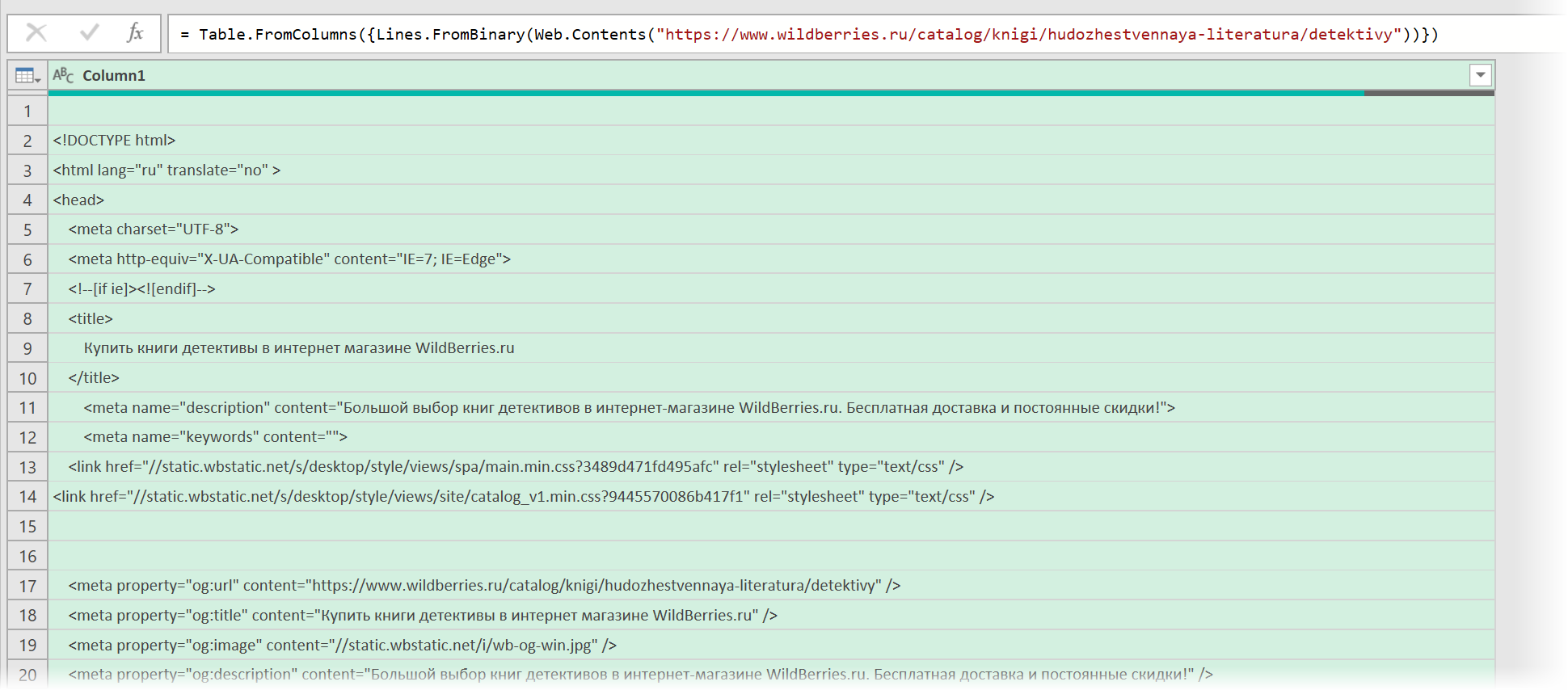
Ищем за что зацепиться
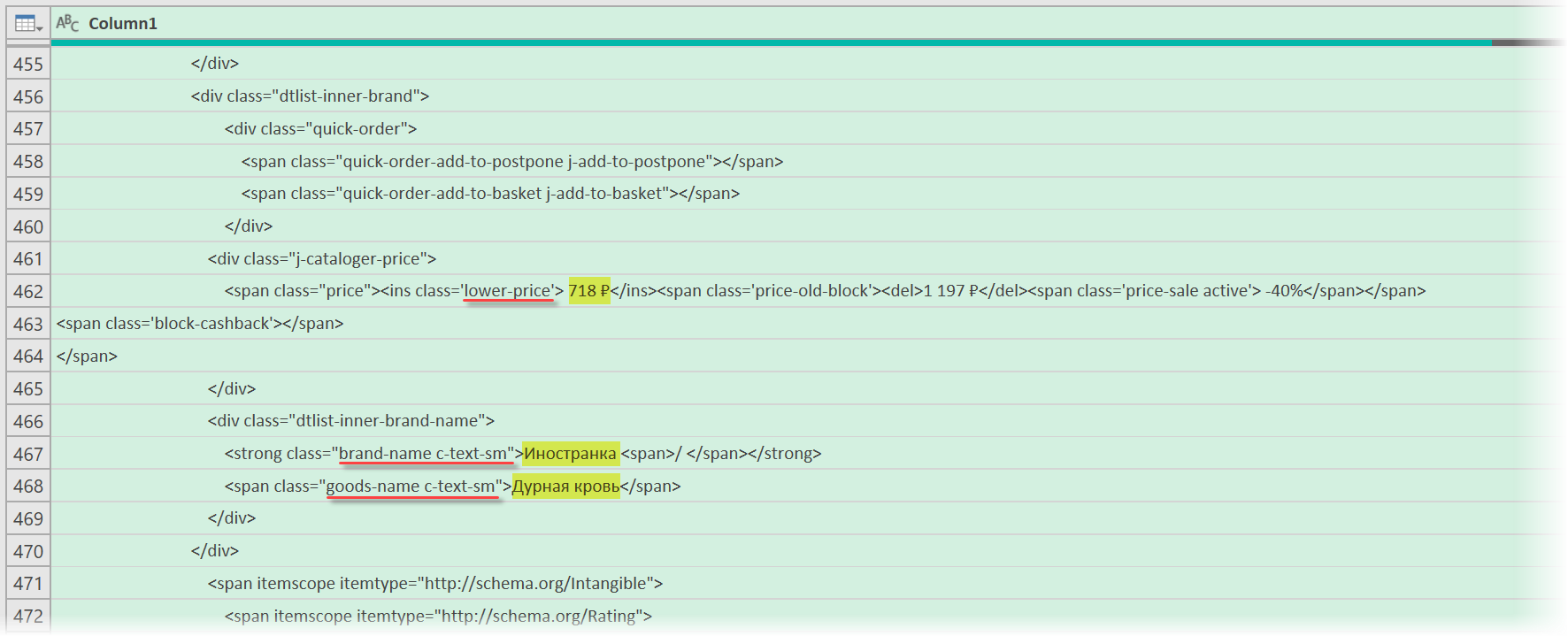
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать. В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
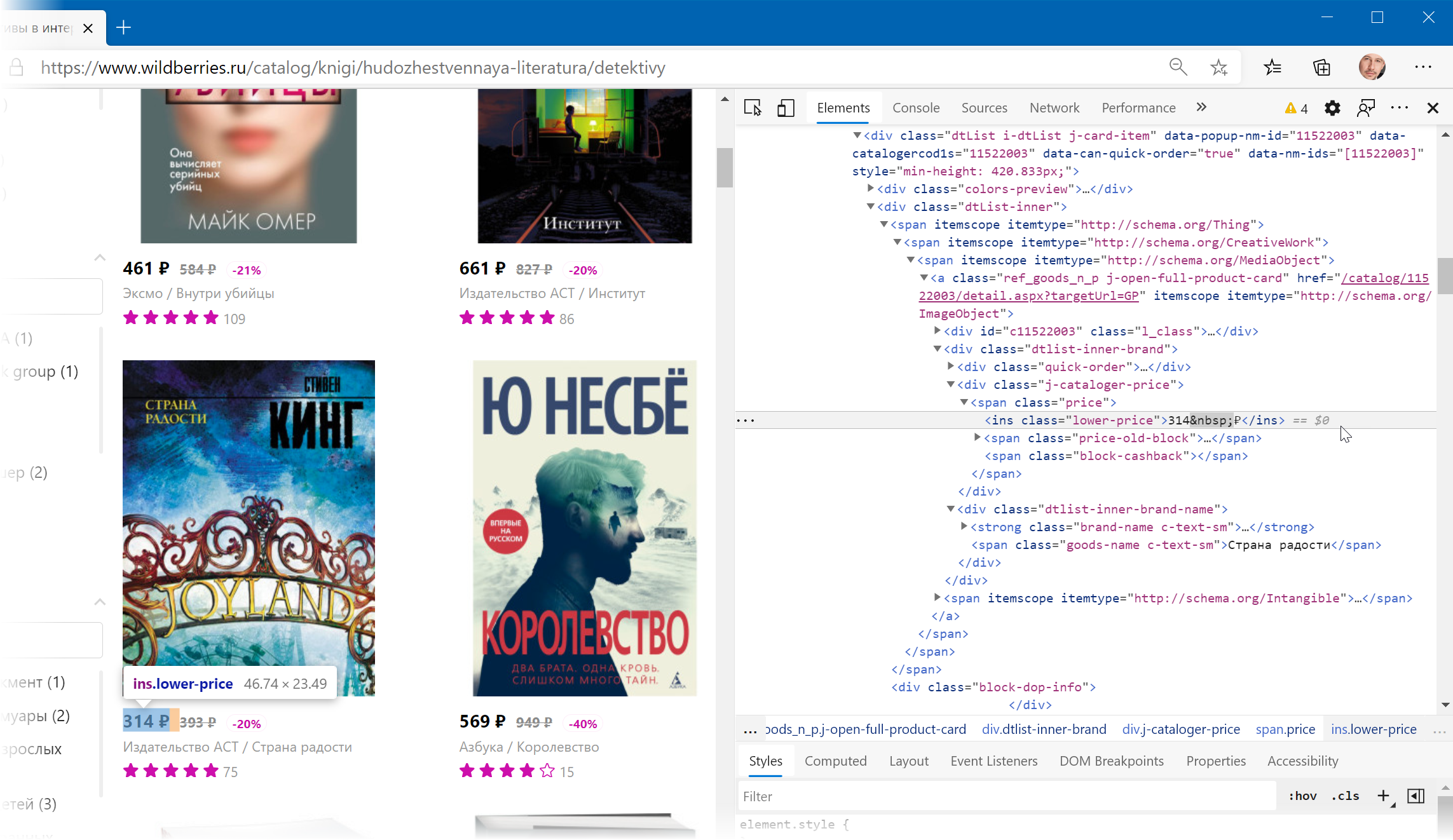
Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains) , переключаемся в режим Подробнее (Advanced) [ 2] и вводим наши критерии:
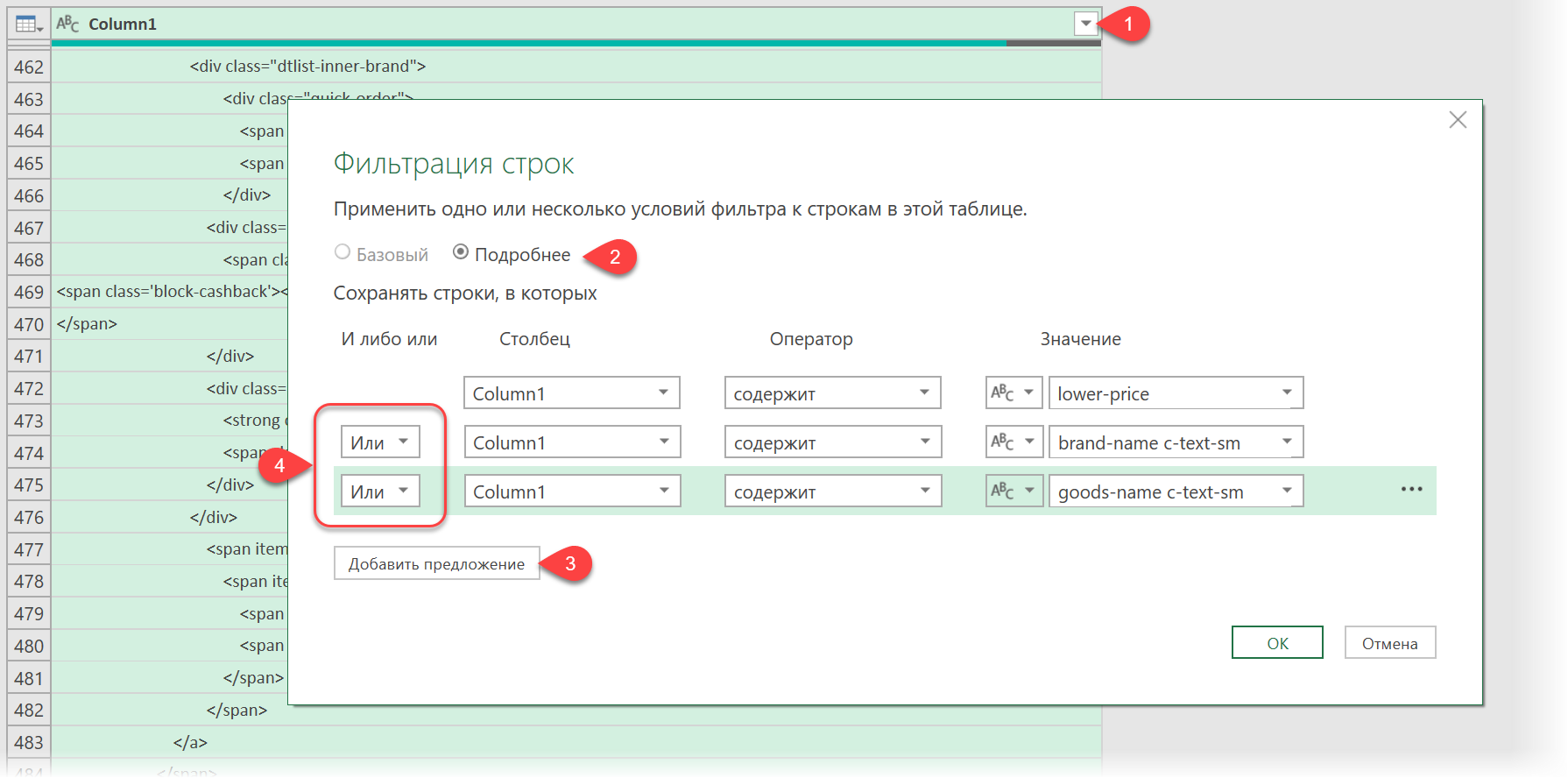
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [ 3] . И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
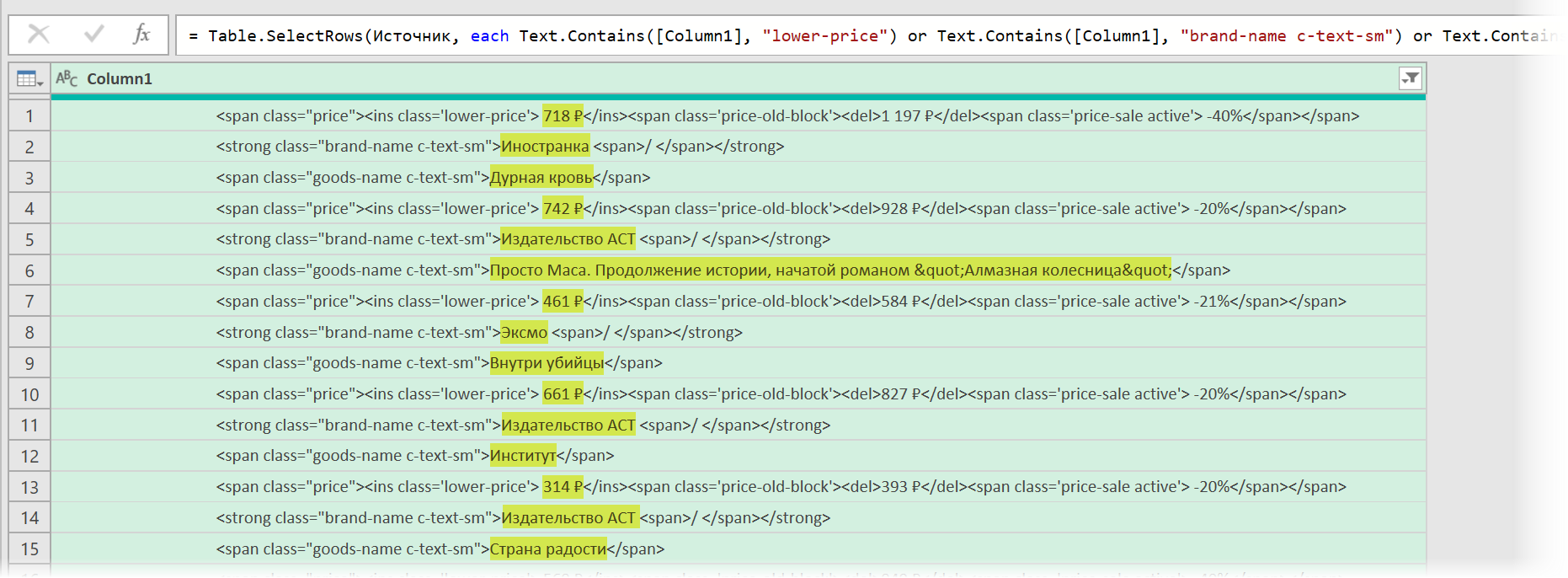
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: через команду Главная — Замена значений (Home — Replace values) .
- Разделить получившийся столбец по первому разделителю » > » слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя » < " слева, чтобы отделить полезные данные от тегов:
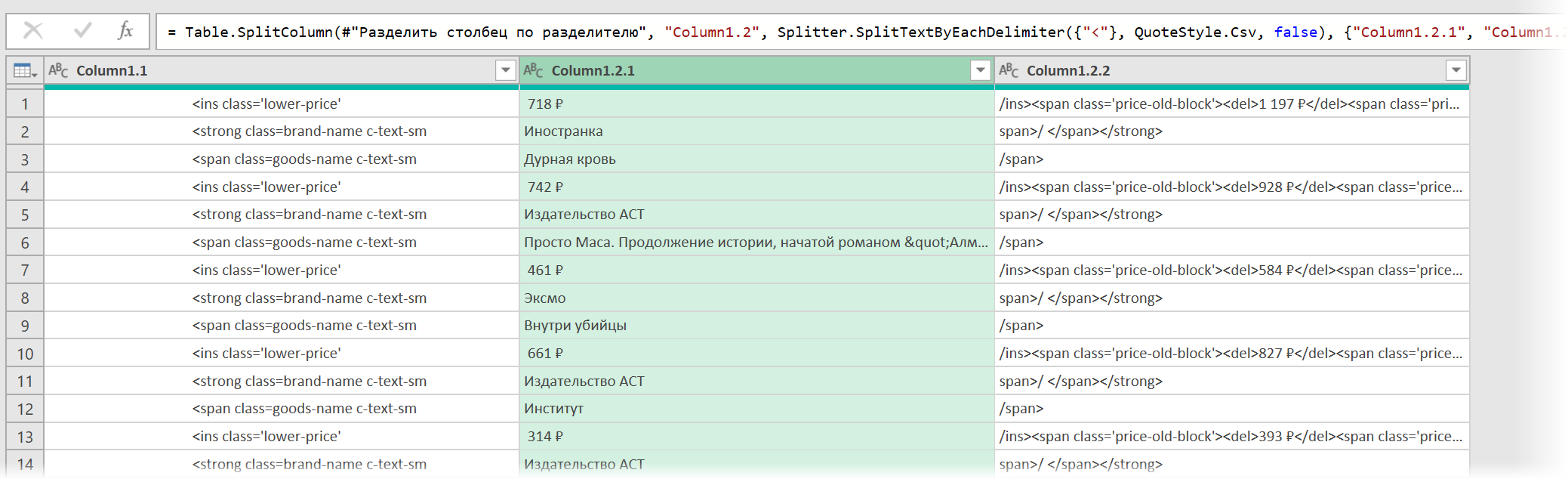
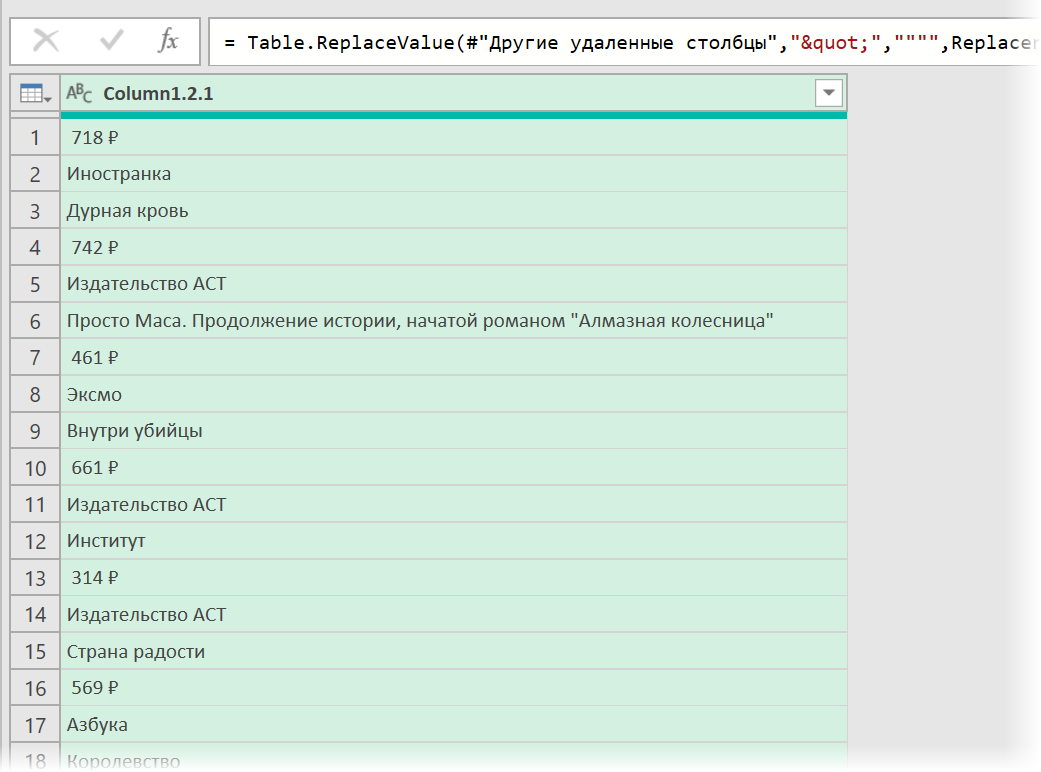
Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View) ) и вводим следующую конструкцию:
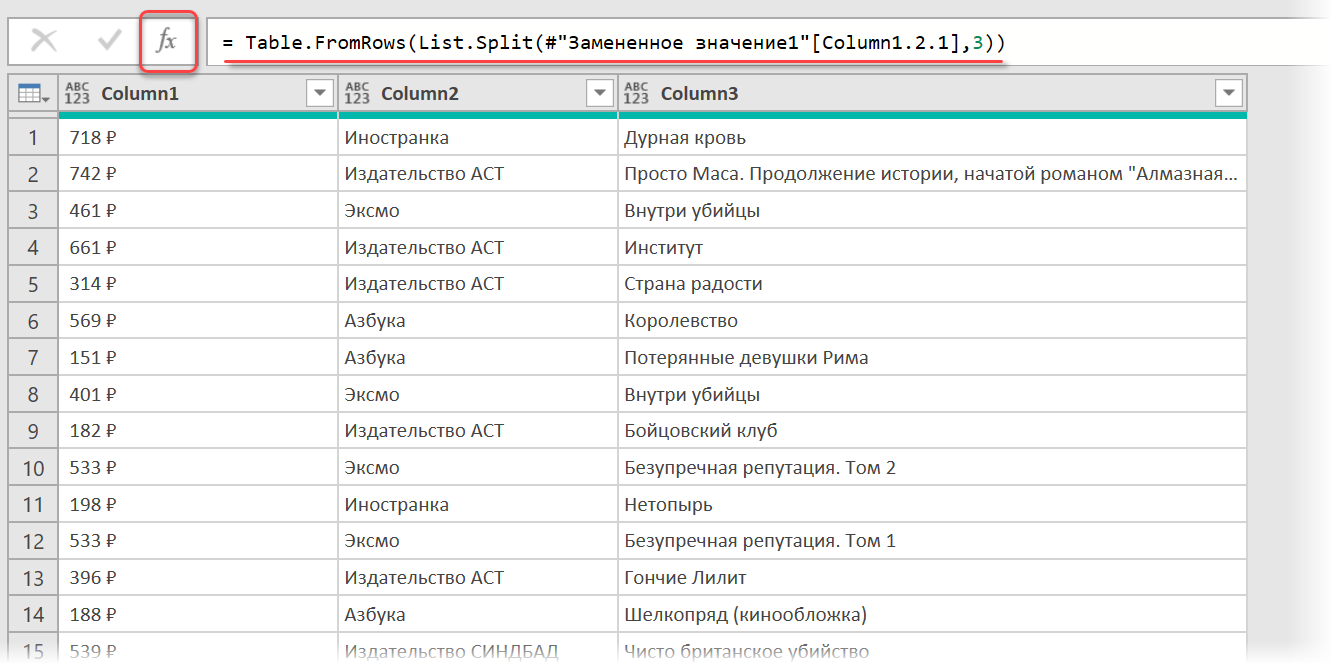
= Table.FromRows(List.Split( #»Замененное значение1″ [Column1.2.1] , 3 ))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load. )
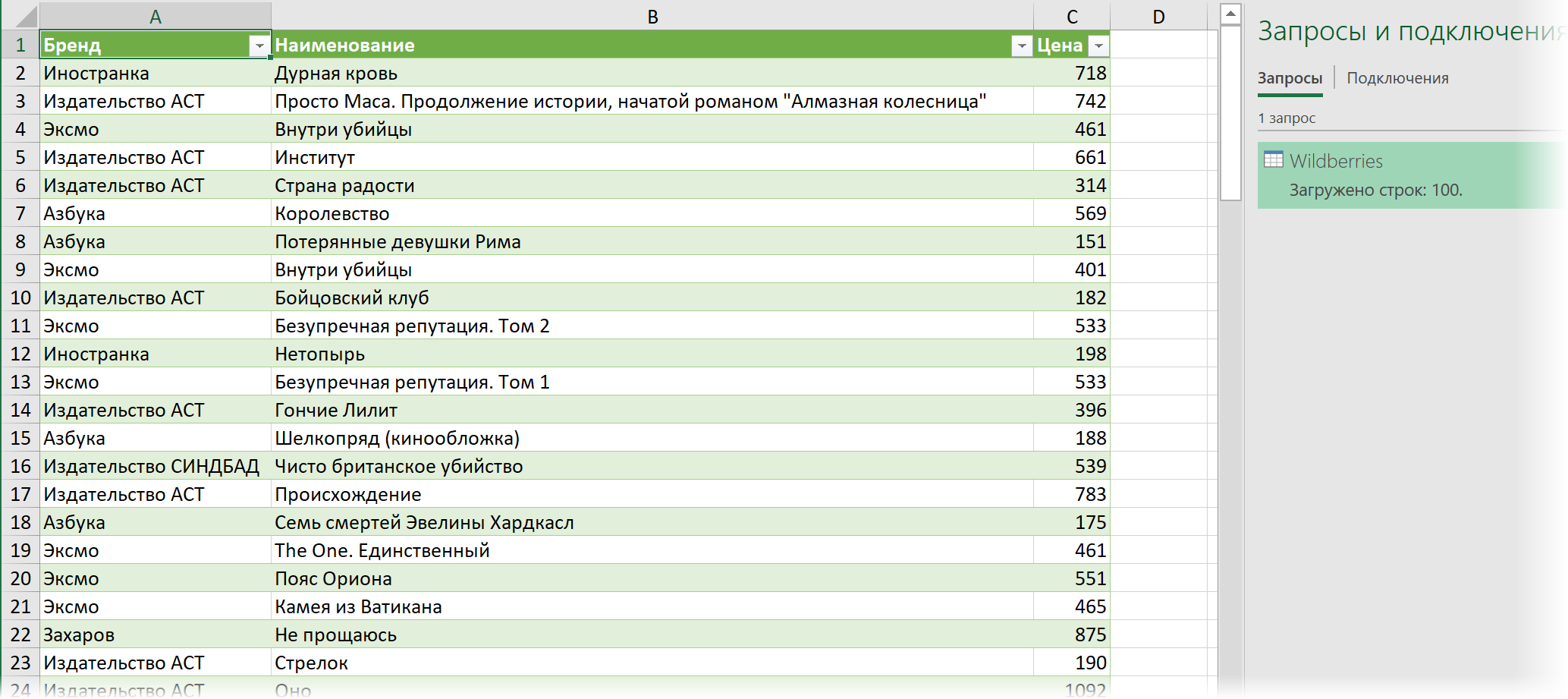
Вот и все хитрости 🙂
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query