Как работают алгоритмы Twitter: особенности работы с платформой Твиттер
Хола, котаны! Маркетинг в Twitter — это непросто. Алгоритм ранжирования – уникальный инструмент в борьбе за внимание пользователя. В среднем в день отправляется 500 миллионов твитов, поэтому освоение алгоритмов Twitter не даст вам потеряться в шуме. Сегодня мы разберемся, как одни посты попадают в топ, а другие залегают на морское дно, но прежде давайте рассмотрим алгоритм ранжирования в Twitter.
Поделиться
@gdetraffic
Что такое алгоритм Twitter
Понять, как работает Twitter, не сложно: он использует почти тот же алгоритм, что и любая другая социальная сеть. Если вы любите футбол, вы увидите больше твитов о любимых командах. Интересуетесь политикой — получите больше политического контента в своей ленте. Алгоритм использует машинное обучение для сортировки контента с помощью сигналов ранжирования, о которых мы поговорим позже.
Обновления алгоритмов Twitter
- Самый популярный твит — твиты ранжируются в зависимости от людей, на которых вы подписаны, и аналогичного контента от тех, на которых вы еще не подписаны;
- Последние твиты — вы также можете переключиться и видеть последние твиты по умолчанию;
- ICYMI (на случай, если вы это пропустили) — содержит самые популярные твиты из всех, которые появились за время вашего отсутствия в приложении. Чем дольше вы работаете в приложении, тем меньше их вы увидите;
- Что происходит сейчас — показывает последние события и темы, относящиеся к вашей деятельности;
- Тенденции для вас — алгоритм трендов Twitter включает в себя трендовые хэштеги и популярные шаблоны, основанные на ваших интересах.
Как работает алгоритм шкалы времени Twitter
Twitter хочет, чтобы пользователи видели интересующий их контент, не ища его. Если люди не получают то, что их интересует, в конечном итоге они перестанут использовать Twitter. Вот почему маркетологам нужно найти время, чтобы досконально понять свою целевую аудиторию и интересный для нее контент.
На шкале времени Twitter можно настроить отображение твитов в двух разных режимах: лучшие и последние твиты. Эти режимы можно изменить, щелкнув значок звездочки в правом верхнем углу ленты.
В режиме Лучшие твиты отображаются твиты в том порядке, который может заинтересовать пользователя. Алгоритм основан на популярности и актуальности твитов. Такой режим ленты новостей Twitter создан для того, чтобы уберечь пользователей от перегруженности и помочь им быть в курсе контента, который им действительно небезразличен.
В режиме Последние твиты ваша временная шкала формируется в обратном хронологическом порядке, причем самые последние твиты находятся наверху. Твиты показываются по мере их публикации в режиме реального времени, поэтому больше контента будет появляться от большего количества людей, но он по-прежнему не будет отображать каждый твит.
Прошли те времена, когда простое знание того, как работает Twitter, позволило бы вам обойти систему. Это всего лишь первый шаг к расширению органического охвата ваших твитов. В основе алгоритма лежат ранжирующие сигналы. Когда вы предлагаете контент Twitter, помните о сигналах ранжирования.


Сигналы ранжирования Twitter
- Новизна. Твиттеру нужен свежий контент. По этой причине они продолжают использовать свое первоначальное предпочтение перечислять твиты в обратном хронологическом порядке. Вот почему всегда полезно обращать внимание на то, в какой день и время вы публикуете новый твит.
- Актуальность. Ключевые слова и хэштеги, используемые в твите, сообщают алгоритму, о чем он и какова его целевая аудитория. Если пользователи взаимодействуют с этими ключевыми словами и хэштегами в других публикациях, они с большей вероятностью увидят ваш твит
- Вовлеченность. Это доказательство того, что людям нравится то, что они видят. Чем больше ретвитов, избранного, кликов и показов получит твит, тем лучше. Twitter также учитывает общее взаимодействие, он ищет постоянство, а не одноразовые чудеса.
Советуем почитать — Рекламные возможности Twitter в 2021. Как добывать трафик из Твиттера?
- Будьте активны — чем больше вы публикуете, тем больше у вас шансов быть замеченным;
- Публикуйте в периоды пиковой активности, лучшее время для публикации — с 11:00 до 13:00;
- Следуйте хэштегу Ttrends — придерживайтесь того, что популярно, но не спамьте хэштегами. Twitter рекомендует не более двух на один пост;
- Используйте мультимедиа — текстовые твиты менее привлекательные, чем изображения, видео и GIF-файлы;
- Поощряйте участие пользователей — просите своих подписчиков отвечать на ваши твиты. Призыв к действию повысит уровень вашей вовлеченности;
- Используйте конкурсы — они способствуют вовлечению, что является ключевым сигналом ранжирования;
- Получайте обратную связь — узнайте, что думают ваши подписчики, с помощью опроса в Twitter. Отлично подходит для вовлечения и планирования будущего контента;
- Присоединяйтесь к актуальным трендам — публикуйте материалы, относящиеся к тому, что происходит в онлайн-мире прямо сейчас. Twitter расскажет вам, что популярно на платформе в данный момент, чтобы вы могли подбирать актуальный контент;
- Переупаковка — переработайте часть вашего контента, но не просто скопируйте и вставьте его, а переупакуйте и используйте повторно. Если он преуспел раньше, скорее всего, у него получиться это сделать еще раз.
Вывод
Алгоритмы Twitter существуют для того, чтобы помочь вам донести пост до заинтересованной аудитории, а не похоронить его в постоянном потоке новых постов. Twitter также постоянно развивается, и понимание того, как работают алгоритмы ранжирования, поможет вам улучшить планирование контента и понять, почему ваши публикации успешны или терпят неудачу. Если вы ищете простые способы попасть в топ Twitter и вывести его на новый уровень, следуйте советам, которые были перечислены в статье. Желаем вам удачи!
Исследование: алгоритмическая лента Twitter скрывает твиты с внешними ссылками и предпочитает политику
Вся правда об эхо-комнатах и о том, как работает алгоритм Twitter, выбирая, что же нам читать.
Поделиться
Поделиться
Ленту Twitter жедневно пролистывает больше 150 миллионов активных пользователей, и по уверениям соцсети, именно алгоритм, формирующий персонализированную ленту, помогает привлечь и удержать не платформе миллионы новых людей. При этом мы всё ещё довольно мало знаем о нюансах его работы: что он повышает в выдаче? До какой степени? И каковы возможные последствия?

Сам Twitter говорит, что использует систему глубокого обучения под внутренним названием DeepBird, чтобы определить, какие твиты будут интересны пользователю. Без особых нюансов и подробностей. Но что скрывается за этим «чёрным ящиком»? Эксперты протестировали его с помощью аккаунтов-марионеток.
Новое исследование, проведённое Computational Journalism Lab, выявило, что алгоритмическая лента Twitter:
1. Содержит меньше твитов с внешними ссылками
Оказалось, что алгоритм Twitter значительно понижает охваты постов с ссылками на внешние источники. Если в хронологической ленте в среднем 51% твитов имеют внешнюю ссылку, то в алгоритмической — 18%. При этом выдача внутренних ссылок Twitter выростает с 12% до 13%, а внутренних изображений — с 19% до 30%.
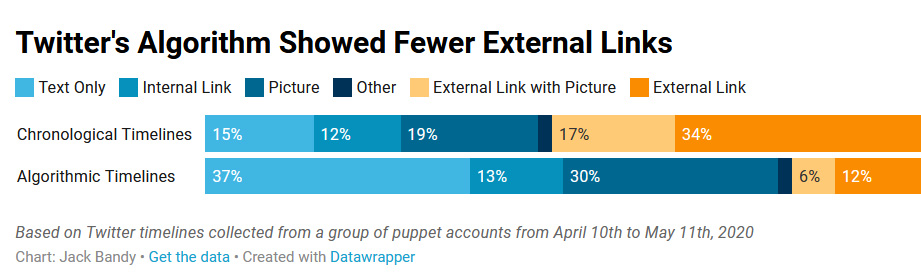
2. Увеличивает количество рекомендуемых твитов (из неподписанных аккаунтов)
В среднем предлагаемые твиты (из неподписанных аккаунтов) составляют 55% алгоритмической ленты. При этом ленты аккаунтов-марионеток изучали дважды в день и анализировали только первые 50 твитов. Возможно, если анализировать первые 200, а не 50 постов, соотношение будет несколько иным.
3. Предлагает большее разнообразие источников
В среднем алгоритм почти удваивает количество уникальных учётных записей в ленте — с 663 до 1169. Алгоритм соцсети также несколько понижает выдачу постов от аккаунтов, которые часто твитят: в среднем на десять аккаунтов с наибольшим количеством твитов приходилось 52% твитов в хронологической ленте, и только 24% — в алгоритмической. К тому же более низкий Gini-коэффициент для алгоритмических лент (0,59 против 0,72) указывает на большее неравенство именно в хронологических лентах.
Таким образом алгоритм не создаёт эффект полноценного информационного пузыря, который многие приписывают соцсетям.
Эти данные как раз доказывают, что алгоритм Twitter диверсифицирует персонализированную ленту за счёт учётных записей, которые не отображаются в хронологической ленте, а также контролирует аккаунты, которые доминировали бы в хронологической. Таким образом алгоритмическая лента несколько шире и беспристрастнее хронологической.
4. Немного изменяет выдачу постов в рамках одной тематики
Эффект выявился при анализе четырёх групп твитов, связанных с пандемией COVID-19, — с уклоном в политику (например, описание реакции президента на пандемию), с информацией о здоровье (например, о факторах риска), с новостями экономики (например, о ВВП или потере работы) и о жертвах болезни (например, отчёты о смертельных случаях). В целом алгоритм Twitter сократил выдачу твитов в каждой из групп, кроме политики:
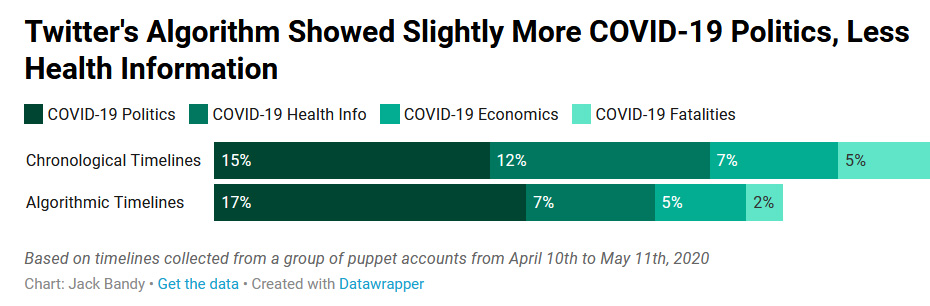
Таким образом алгоритмы социальных сетей могут иногда снижать доступ к важной информации (например, информации о здоровье и смертности в связи с COVID-19), одновременно приоритезируя другие темы.
Тем не менее, эффект представлял собой не герметичный информационный пузырь, а скорее эхо-камеру, в которой одни темы поднимались чаще, а другие — заглушались. Как в анализе партий — в следующем пункте.
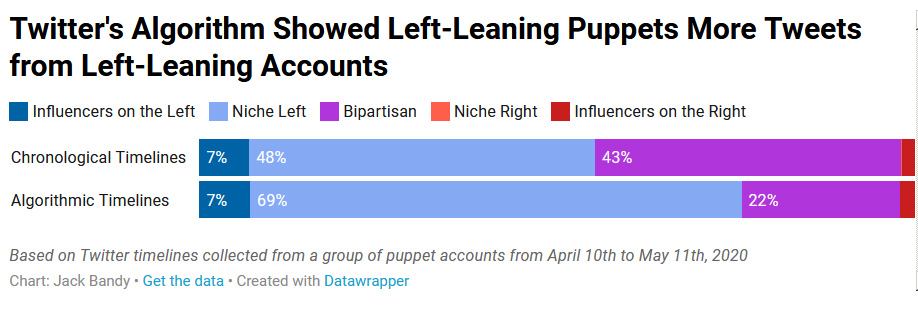
5. Создаёт небольшой эффект эхо-камеры
При анализе партийных предпочтений, эксперты измерили, как алгоритм Twitter меняет охваты аккаунтов с разными политическими взглядами. Это не было проверкой на «политическую предвзятость» алгоритма, скорее — на то, как алгоритм влияет на охваты сторонних аккаунтов по сравнению с хронологической лентой.
Результаты отчасти перекликаются с данными исследования Facebook от 2015 года, которое показало, что основная «предвзятость» алгоритма определяется выбором самого пользователя (за счёт собранных данных — за кем он следит и на что кликает). Тем не менее, небольшой эффект эхо-камеры всё-таки наблюдается.
Например, алгоритмическая лента понижает охват аккаунтов, которые классифицировала как двухпартийные. Так, у марионеток с левым уклоном хронологическая лента содержала 43% твитов двухпартийных аккаунтов (фиолетовый цвет на диаграмме ниже), а алгоритмическая — не больше 22%:
Схожий эффект наблюдался и у марионеток с правым уклоном: их хронологические ленты на 20% состояли из твитов двухпартийных аккаунтов, а алгоритмические — только на 14%:
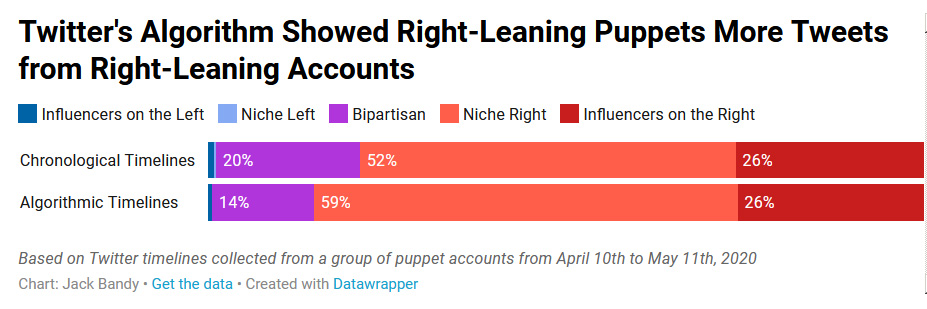
Эффект эхо-камеры трудно измерить, поэтому, если вы хотите узнать больше, ознакомьтесь с техническими деталями или полным текстом исследования.
Примечательно, что, например, Барака Обаму и Fox News Twitter тоже счёл «двухпартийными» — потому что за их постами обычно следили как правые, так и левые.
Итак, каковы же возможные последствия такой персонализации?
Например, уменьшение количества внешних ссылок может серьёзно повлиять на новостную экосистему. Согласно опросу Pew 2018 года, около семи из десяти взрослых пользователей Twitter в США используют соцсеть для чтения новостей. Поскольку алгоритм Twitter сокращает доступ к внешним новостным ссылкам, у пользователей меньше шансов прочитать высококачественные СМИ, а у новостных агентств — снижается веб-трафик, а значит — и доходы от рекламы.
В то же время нужно чётко понимать, что алгоритм — это не очередная страшилка, а просто часть большой и сложной медиа-экосистемы.
Мы, конечно, можем настроить алгоритм(ы), но должны также рассматривать и другие возможности для улучшения обмена новостями и информацией в интернете. Например, повышать медиаграмотность, совершенствовать пользовательские интерфейсы, структуры управления и нормативные меры — всё это улучшит экосистему, наряду с потенциальными настройками алгоритма.
Как недавно написали Энн Эпплбаум и Пётр Померанцев, «интернет не обязательно должен быть ужасным».

A/B-тестирование от Flocktory: быстрый запуск тестов и оптимизация вашего сайта для роста конверсий
A/B-тесты — инструмент продуктового и маркетингового тестирования контента и функциональности сайта с комплексной аналитикой результатов.
С помощью этого инструмента вы сможете менять содержимое сайта на основе лучших практик Flocktory и кастомных гипотез, которые мы поможем сформулировать. А также повысить конверсию сайта и сэкономить время продуктовых и технических команд.
Тестирование и оптимизация сайта проходят без вовлечения вашей IT-команды, а результаты тестов доступны в личном кабинете в реальном времени.
Как работают алгоритмы Facebook, Youtube, Twitter, Instagram. И как их усмирить
У человечества масса причин опасаться созданных своими же руками алгоритмов искусственного интеллекта. Автор статьи для Mashable Крис Тейлор рассказывает, как алгоритмы соцсетей определяют, какой и чей контент (не) предстанет перед глазами пользователей. Публикуем перевод статьи.
YouTube
Алгоритм автовоспроизведения YouTube вредит демократии не меньше, если не больше, чем любовь Facebook к провокационным постам. Около 70% просматриваемых нами видеороликов рекомендованы движком сервиса, который оптимизирован так, чтобы любым способом заставить людей просмотреть как можно больше контента и рекламы. К слову, средняя длительность пользовательской сессии на YouTube — уже больше часа.
А значит, YouTube будет отдавать приоритет острому контенту, потому что хотите вы этого или нет, вы продолжите смотреть его. И когда закончится один «неоднозначный» ролик, алгоритм подбросит ролики, которые дальше включали другие пользователи, тоже смотревшие его. Это объясняет, почему после безобидного новостного репортажа можно очнуться за просмотром видео на тему конспирологических теорий.
Экс-гуглер Гийом Часлот обнаружил следы влияния предвзятого алгоритма YouTube на исход американских выборов 2016 года, перевес в которых составил всего 77 тысяч голосов в трёх штатах. Более 80% рекомендованных видео носили протрамповский характер независимо от того, был ли изначальный запрос «Трамп» или «Клинтон», писал он об алгоритме. Большинство этих рекомендаций приходились на видео спорного содержания и фейковые новости, пишет Числот.
Он также заметил, что 90% рекомендованных видео в выдаче по запросу «является ли Земля плоской» положительно отвечают на этот вопрос.
Эта проблема существует не только в США. Один из самых показательных кейсов о политическом влиянии YouTube — Бразилия: правого кандидата Жаира Болсонару избрали президентом после того, как он стал звездой видеохостинга. «Поисковая и рекомендательная система YouTube систематически уводила пользователей на крайние правые и конспирологические бразильские каналы», — предположили по итогу расследования в 2019 году журналисты New York Times. Вклад алгоритма в победу Болсонару признают даже его сторонники.
Как исправить
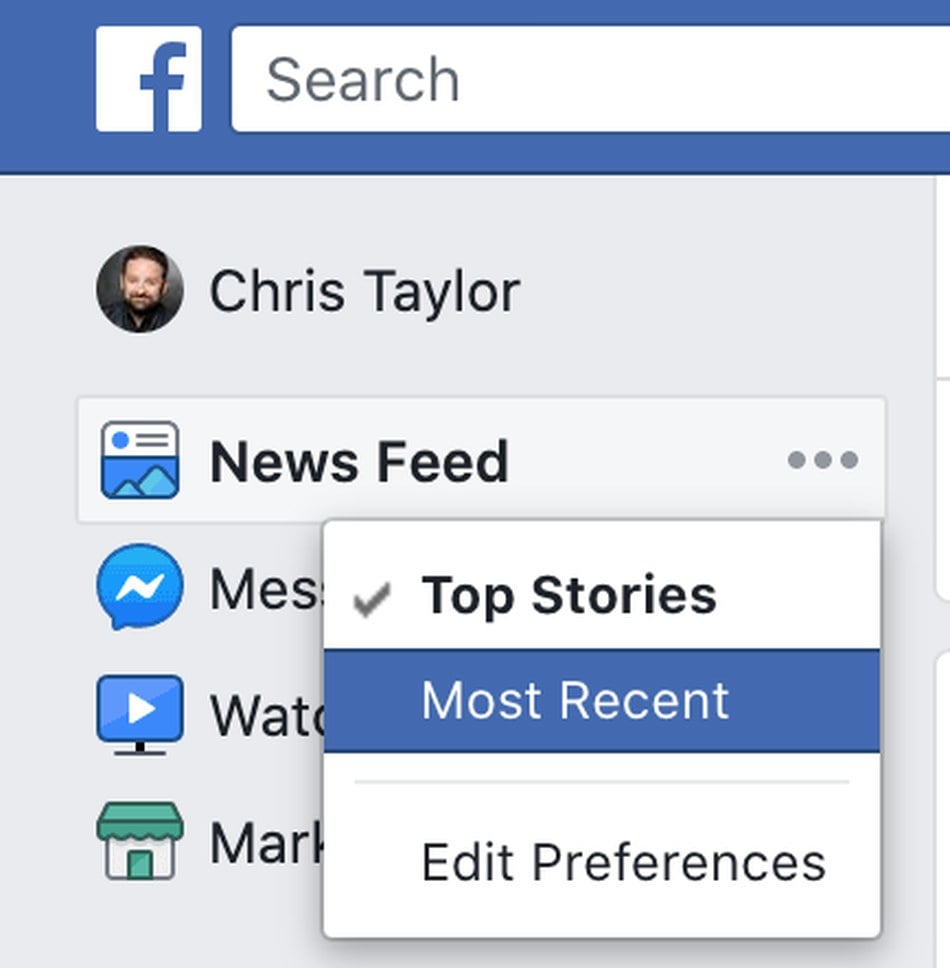
Выключайте автовопроизведение — нужно просто перетянуть влево тумблер рядом с надписью «Следующее» на панели с видеороликами справа. Так вы хотя бы перестанете на автопилоте смотреть всё подряд, что предлагает YouTube. Полностью отключить рекомендации нельзя, но можно хоть немного защитить менее «прошаренных» родственников от алгоритма, который манипулирует их взглядами ради просмотров.
Кстати, если вы дрессировали алгоритм лайками и дизлайками на протяжении нескольких лет и он хорошо знает ваши интересы, то его рекомендации будут вполне адекватными. У новых пользователей YouTube картина совсем другая.
Instagram, в отличие от материнской компании, полностью отказался от хронологического отображения постов в 2016 году. Из-за этого сервис стали подозревать в использовании «теневого бана», или блокировки контента юзера без его ведома. Instagram отображает все фото и сторис — вопрос в том, сколько до них придётся скролить, но некоторые имена появляются на верху ленты настолько часто, что можно почувствовать себя Instagram-сталкером.
Как исправить
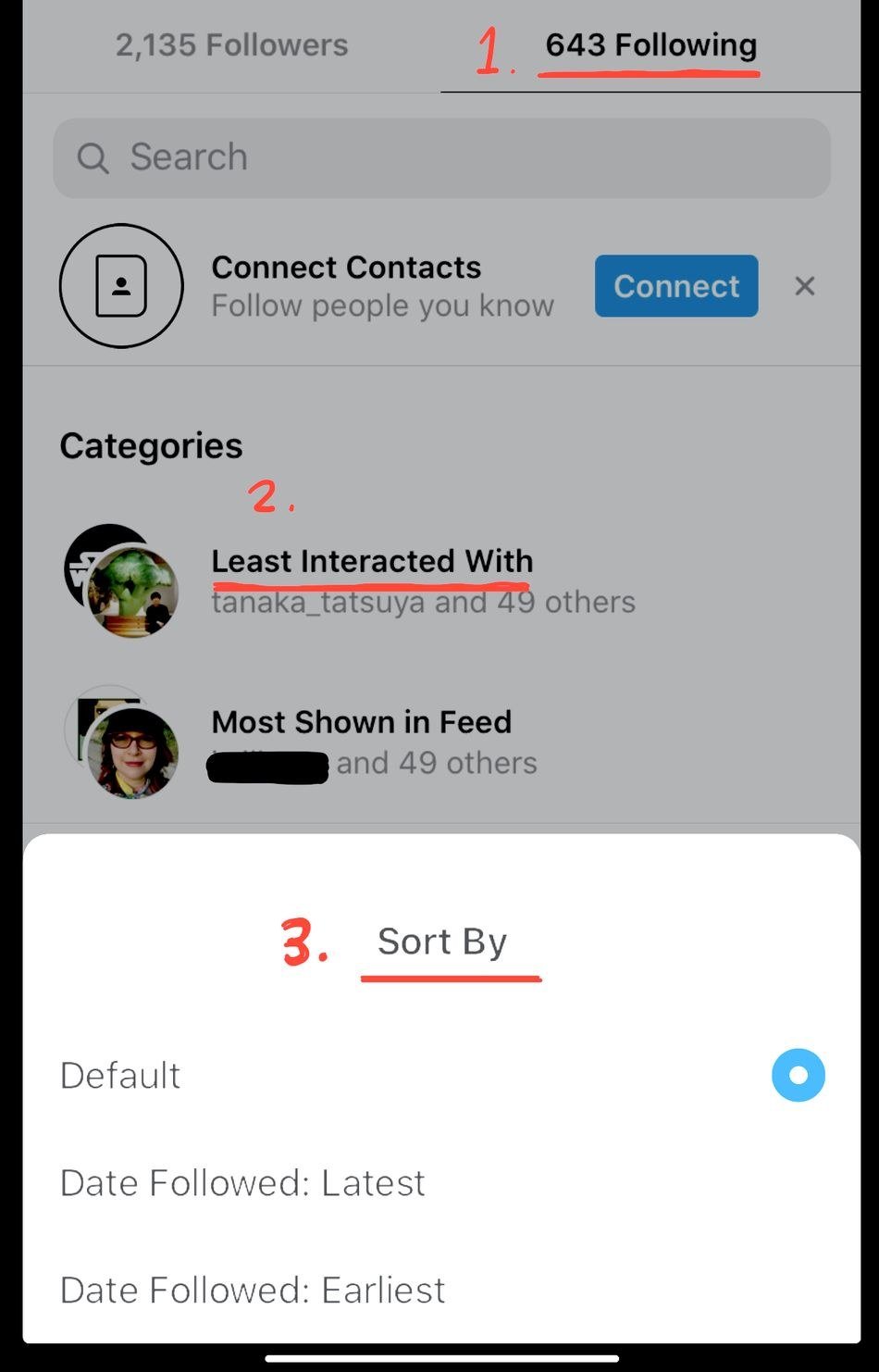
В февральском обновлении Instagram появилась функция, которая позволяет посмотреть, с какими подписками вы взаимодействуете чаще или меньше всего. Для этого нужно нажать на значок профиля в правом нижнем углу интерфейса, перейти в раздел «Подписки», где отобразятся категории «Меньше всего взаимодействий» и «Чаще всего показываются в ленте». Выберите первый пункт и просматривайте посты, обделённые вашим вниманием.
Также в Instagram есть сортировка постов в ленте по дате подписки на аккаунты. Помимо этого, соцсеть тестирует опцию «Последние публикации» для показа контента в порядке опубликования, но широкой публике она пока недоступна.
4. Twitter
В этом плане Twitter ничем не отличается от своих конкурентов и тоже экспериментирует с подачей контента не в традиционном для себя хронологическом порядке. К примеру, платформа Джека Дорси выкатила опцию отслеживания не только людей, но и твитов по различным темам. Хотя в 2018 году соцсеть вернула хронологическую ленту.
Как исправить
Настройки ленты в Twitter находятся рядом с надписью «Главная» по центру в верху страницы. Нажмите на «звёздочки» справа от неё, после чего — «Показывать вместо этого последние твиты». Из всех соцсетей отключить «умную» ленту проще всего именно в Twitter.
Листать до чего-то интересного, возможно, придётся дольше, а наполнение ленты будет зависеть, например, от времени суток, в которое вы сидите в Twitter. Но для тех, кто не хочет отдавать в руки алгоритма подбор постов в ленте, режим «Последние твиты» — то что надо.
Алгоритм рекомендаций Twitter: как он работает

Почти год назад Илон Маск предложил сделать алгоритм рекомендаций Twitter общедоступным. Недавно компания выложила исходный код своего алгоритма на GitHub.
В статье — перевод их блог‑поста с описанием работы алгоритма рекомендаций. Он подойдет:
- любым желающим узнать, как алгоритмы выбирают, что вам показать в ленте,
- Data Scientist‑ам и ML‑инженерам, как уникальный источник инсайтов о работе большой рекомендательной системы.
Twitter стремится показать вам наиболее релевантное из того, что происходит в мире в данный момент. Для этого нужен алгоритм рекомендаций, который сможет извлечь из 500 миллионов твитов ежедневно те лучшие, которые в итоге будут показаны в разделе «Для вас» (For You). В этой статье мы расскажем, как алгоритм выбирает твиты для вашей ленты.
Как мы выбираем твиты?
Основой рекомендаций Twitter является набор алгоритмов и функций, которые извлекают скрытую информацию из твитов, пользователей и данных о взаимодействиях. Эти модели стремятся ответить на важные вопросы, например, «Какова вероятность того, что вы будете взаимодействовать с этим пользователем в будущем?» или «Какие сообщества выделяются в Twitter и какие твиты в них популярны?» Точные ответы на эти вопросы позволяют делать более релевантные рекомендации.
Система рекомендаций состоит из трех основных этапов:
- Отбор кандидатов — извлечение лучших твитов из разных источников рекомендаций.
- Ранжирование этих твитов с помощью модели машинного обучения.
- Применение эвристик и фильтров, например, фильтрация твитов от пользователей, которых вы заблокировали, NSFW‑контента и твитов, которые вы уже видели.
Сервис, который отвечает за создание и предоставление ленты For You, называется Home Mixer. Home Mixer создан на основе Product Mixer, нашей специальной платформы на Scala, которая облегчает создание ленты контента. Этот сервис связывает различные источники кандидатов, функции скоринга, эвристики и фильтры.
Диаграмма ниже иллюстрирует основные компоненты, используемые для создания ленты:
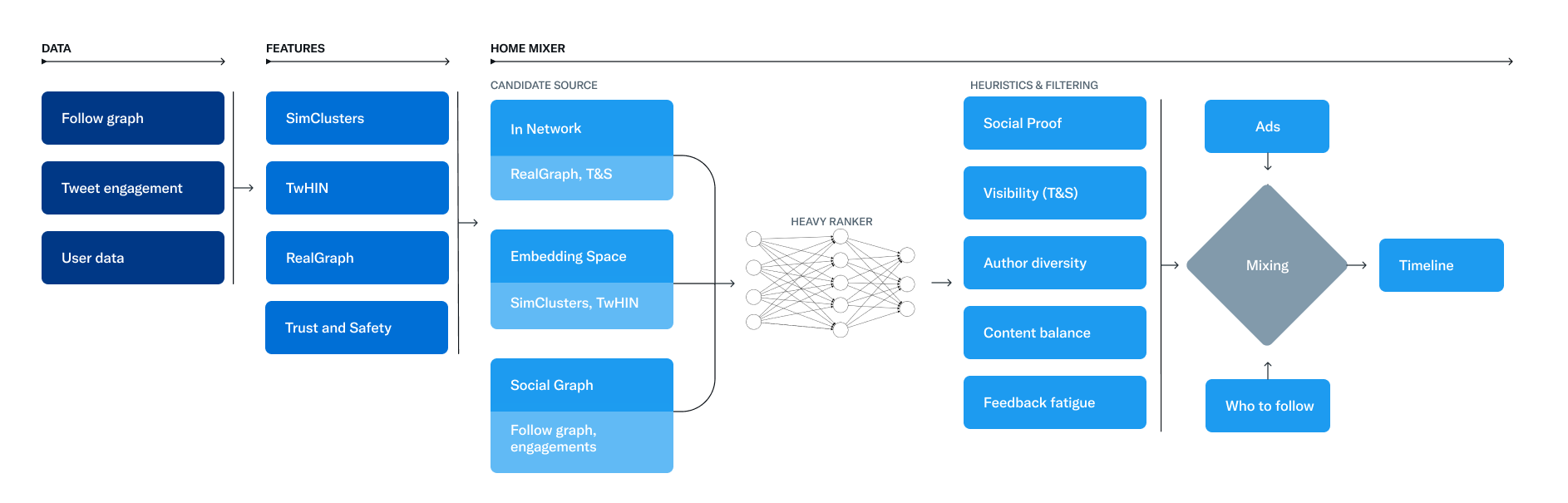
Рассмотрим ключевые элементы этой системы примерно в том порядке, в котором они вызываются во время одного запроса на показ ленты. Начинем с получения кандидатов из Источников кандидатов.
Источники кандидатов
У Twitter есть несколько источников кандидатов для получения свежих и актуальных твитов. Через эти источники мы пытаемся извлечь лучшие 1500 твитов из сотен миллионов для каждого запроса. Мы находим кандидатов от пользователей, на которых вы подписаны (In‑Network), и от пользователей, на которых вы не подписаны (Out‑of‑Network). Лента For You состоит в среднем на 50% из твитов In‑Network и на 50% из твитов Out‑of‑Network, хотя этот процент может варьироваться от пользователя к пользователю.
Источник In-Network
In-Network является наиболее крупным источником кандидатов. Он предоставляет твиты от пользователей, на которых вы подписаны. С помощью модели логистической регрессии эти твиты сортируются по их релевантности. Лучшие твиты затем отправляются на следующий этап.
Самый важный компонент в ранжировании твитов In-Network — это Real Graph. Real Graph — это модель, которая предсказывает вероятность взаимодействия между двумя пользователями. Чем выше показатель Real Graph между вами и автором твита, тем больше мы будем включать его твиты.
Источник In-Network был недавно переработан. Мы перестали использовать Fanout Service — 12-летний сервис, который предоставлял твиты из кэша для каждого пользователя. Также мы перерабатываем модель ранжирования логистической регрессии, которая последний раз была обновлена и обучена несколько лет назад!
Источники Out-of-Network
Нахождение релевантных твитов вне сети пользователя — более сложная проблема: Как мы можем определить, будут ли определенные твиты для вас актуальны, если вы не подписаны на автора? Twitter использует два подхода для решения этой проблемы.
1. Social Graph
Первый подход анализирует лайки людей, на которых вы подписаны, или тех, кто имеет похожие на вас интересы.
Мы проходим по графу взаимодействий и подписок, чтобы ответить на следующие вопросы:
- Какие твиты недавно лайкнули люди, на которых я подписан?
- Кто лайкает те же твиты, что я, и что еще они лайкнули недавно?
Мы создаем кандидатов на основе ответов на эти вопросы и ранжируем полученные твиты, используя модель логистической регрессии. Такие обходы графа критичны для наших рекомендаций. Для этого мы разработали GraphJet, движок обработки графов, который в реальном времени поддерживает граф взаимодействий между пользователями и твитами. Хотя этот подход оказался полезным (на него приходится около 15% твитов ленты домашней страницы), подходы, основанные на пространстве эмбеддингов, дают больший вклад.
2. Пространства эмбеддингов (Embedding Spaces)
Подходы на основе эбеддингов хотят получить ответ на более общий вопрос о схожести контента: Какие твиты и пользователи похожи на мои интересы?
Эмбеддинг — численное представление интересов пользователей и содержимого твитов. По ним мы можем рассчитать сходство между любыми двумя пользователями, твитами или парами пользователь-твит в этом пространстве эмбеддингов. Это сходство можно использовать в качестве замены релевантности при условии достаточно точных эмбеддингов.
Одним из наиболее полезных пространств эмбеддингов в Twitter являются SimClusters. SimClusters находят сообщества вокруг влиятельных пользователей (инфлюенсеров), используя собственный алгоритм матричного разложения. Существует 145 тыс. сообществ, которые обновляются каждые три недели. Пользователи и твиты могут принадлежать нескольким сообществам. Сообщества имеют размер от нескольких тысяч пользователей для отдельных групп друзей до сотен миллионов пользователей для новостей или поп-культуры. Вот некоторые из самых больших сообществ:
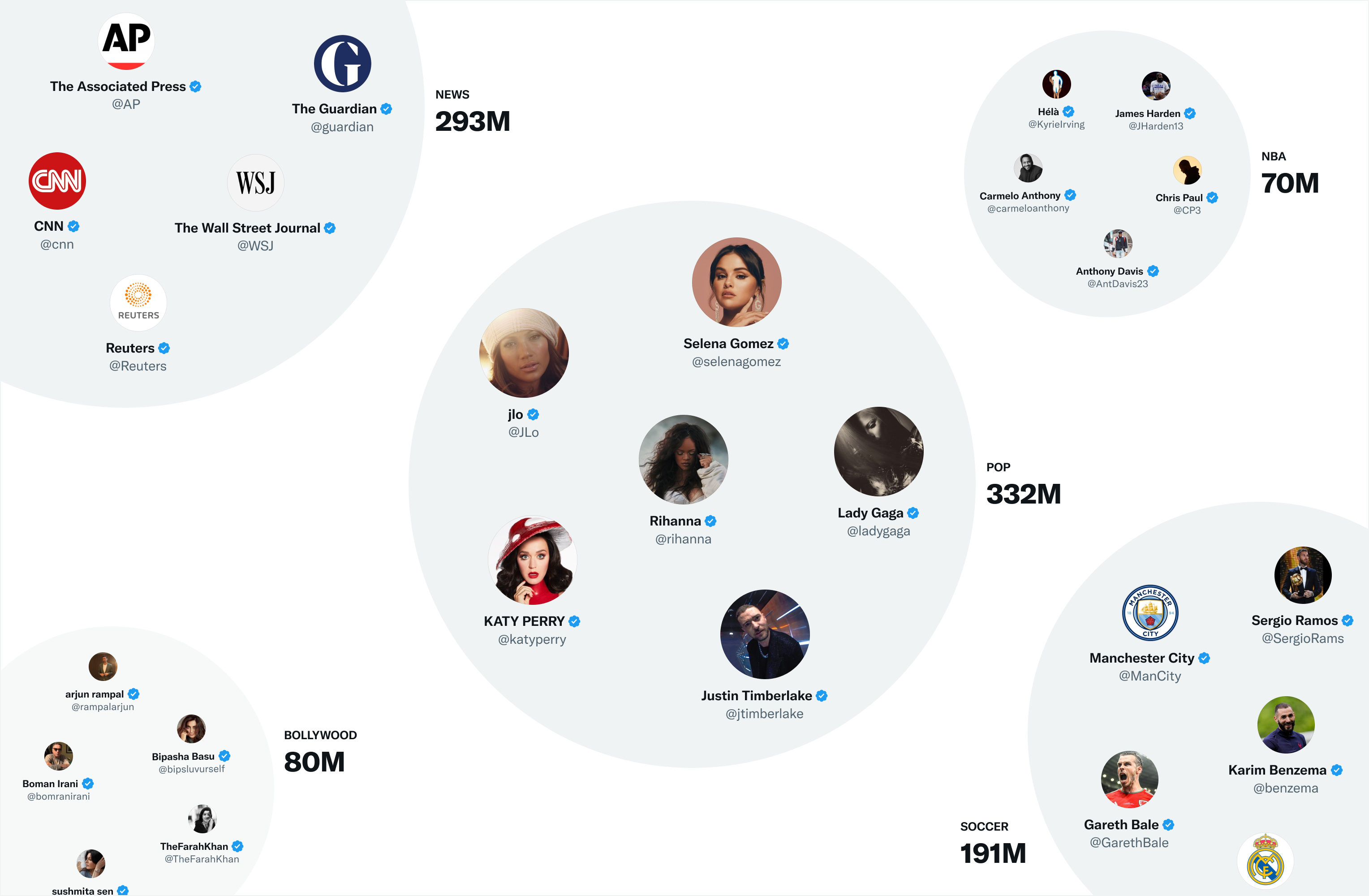
Мы включаем твит в сообщество по его текущей популярности в этом сообществе. Чем большим пользователям из сообщества он нравится, тем больше этот твит будет связан с этим сообществом.
Ранжирование
На данном этапе мы имеем ~1500 потенциально релевантных кандидатов. Следующим шагом необходимо проскорить каждого кандидата на предмет соотвествия именно вашей ленте. Здесь все кандидаты обрабатываются одинаково, вне зависимости от источника.
Ранжирование достигается с помощью нейронной сети с ~48 миллионами параметров, которая непрерывно обучается на взаимодействии с твитами. Она оптимизирует положительную обратную связь (например, лайки, ретвиты и ответы). Этот механизм ранжирования учитывает тысячи признаков и выдает десять меток. Таким образом, каждый твит получает составную оценку, где каждая метка показывает вероятность взаимодействия. Мы ранжируем твиты на основе этих оценок.
Эвристики, фильтры и дополнительные функции
Следующим шагом мы применяем эвристики и фильтры для улучшения качества продукта. Дополнительные фичи взаимодействуют между собой, чтобы создать сбалансированную и разнообразную ленту. Вот некоторые примеры:
- Фильтрация по видимости: фильтрация твитов на основе их содержания и ваших предпочтений. Например, убрать твиты от аккаунтов, которые вы заблокировали.
- Разнообразие авторов: избегание длинных последовательностей твитов от одного автора.
- Баланс контента: обеспечение баланса In-Network и Out-of-Network твитов.
- Учет негативного фидбека: снижение скора твитов, близких к тем, где вы дали отрицательную обратную связь.
- Подтверждение от окружения: исключение твитов пользователей более 2-го уровня связи. То есть, гарантируется, что среди ваших подписок есть пользователь, который взаимодействовал с данным твитом или подписан на его автора.
- Переписка: добавление оригинального твита к ответу.
- Отредактированные твиты: определение твитов, устаревших сейчас на устройстве, и замена их отредактированными версиями.
Обогащение и передача данных
На этом этапе Home Mixer получает набор готовых к отправке на устройство твитов. Твиты замешиваются с другим контентом, например, рекламой, рекомендациями по подпискам и подсказками, которые затем возвращаются на устройство для отображения.
Вышеописанный пайплайн работает примерно 5 миллиардов раз в день и выполняется в среднем за 1,5 секунды. При этом один запуск пайплайна требует 220 секунд времени CPU — почти в 150 раз больше, чем задержка, которую вы видите в приложении.

Основная цель в рамках проекта с открытым исходным кодом — полностью прозрачно предоставить вам, нашим пользователям, информацию о том, как работают наши системы. Мы сделали код рекомендаций доступным для более детального ознакомления с нашим алгоритмом, его можно посмотреть здесь (и здесь). Также мы работаем над предоставлением большей прозрачности по другим функциям внутри нашего приложения. Некоторые из планируемых новых разработок включают в себя:
- Лучшая аналитическая платформа для создателей контента с более подробной информацией об охватах и вовлеченности.
- Большая прозрачность в отношении любых меток безопасности, применяемых к вашим твитам или аккаунтам.
- Большая наглядность в том, почему твиты появляются в вашей ленте.
Если вы хотите больше читать про Data Science, машинное обучение и не только, подписывайтесь на мой телеграм‑канал.
- recsys
- рекомендательные системы
- open source
- машинное обучение
- data science
- big data
- алгоритм
- deep learning
- нейронные сети