Освобождаем свои данные из корпоративного рабства. Концепция личного хранилища

Автор программы Mathematica Стивен Вольфрам около 40 лет ведёт цифровой лог многих аспектов профессиональной и личной жизни
Сейчас практически всем стала понятна сущность некоторых интернет-корпораций, которые стремятся получить от людей как можно больше личных данных — и заработать на этом. Они предлагают бесплатный хостинг, бесплатные мессенджеры, бесплатную почту — лишь бы люди отдали свои файлы, фотографии, письма, личные сообщения. Наши данные приносят огромные деньги, а люди стали продуктом. Поэтому техногиганты Google и Facebook — самые крупные корпорации в истории человечества. Это неудивительно, ведь в их распоряжении миллиарды единиц бесплатного «сырья», то есть «пользователей» (кстати, этим словом users называют людей только в двух областях: наркоиндустрии и индустрии программного обеспечения).
Настало время положить этому конец. И вернуть данные под свой контроль. В этом суть концепции личных хранилищ данных (personal data services или personal data store, PDS).
Нам нужны удобные программы, сервисы, базы данных и защищённые хранилища для фотографий, личных финансов, социального графа, данных о личной продуктивности, потреблению продуктов, истории всех чатов в онлайне и офлайне, личного дневника, медицинских данных (пульс, давление, настроение и проч.), прочитанной литературы и публицистических статей, просмотренных веб-страниц, фильмов и видеороликов, прослушанной музыки и так далее.
Разумеется, эти данные должны храниться за всю жизнь человека — в абсолютно надёжном хранилище, к которому нет доступа корпораций и посторонних лиц. Нужны удобные инструменты для анализа и статистики. Нужны персональные нейросети для обработки данных и предсказания личных решений (например, для рекомендации музыкальных групп, блюд кухни или людей для общения).
К сожалению, единого общепринятого и удобного подхода к созданию таких решений пока нет. Но идёт работа в нужном направлении.
Инфраструктура для хранения персональных данных
Некоторые исследователи думают над концептуальным решением проблемы, то есть над тем, какой должна быть вся инфраструктура для персональных данных.
Например, разработчик @karlicoss описал концепцию такой инфраструктуры.
- Простота для людей, чтобы данные было легко просматривать и читать.
- Простота для машинного анализа, для манипулирования данными и взаимодействия.
Что ещё предусмотреть в концепции PDS? Должны быть API для получения любых данных из персонального архива.
Логично, что самый простой способ работы с данными — когда они непосредственно лежат в вашей файловой системе. В реальности персональные данные разбросаны по десяткам разных сервисов и программ, что очень затрудняет работу с ними. Для начала желательно извлечь их оттуда и сохранить локально. Да, теоретически это необязательно, ведь продвинутые PDS могут поддерживать работу с разными источниками данных в разных форматах. Например, данные могут храниться в разных облачных хранилищах, извлекаться через сторонние API из других сервисов и программ. Правда, нужно понимать, что это ненадёжные хранилища.
Например, Twitter через свои API отдаёт 3200 последних твитов, Chrome хранит историю 90 дней, а Firefox удаляет её на основе хитрого алгоритма. Ваш аккаунт в облачном сервисе могут в любой момент закрыть, а все данные удалить. То есть сторонние сервисы никак не предполагают долговременное хранение данных.

Расчётный лист вавилонского рабочего, датирован 3000 г до н. э. Пример долговременного хранения личной информации
Экспорт данных в личное хранилище
В качестве промежуточного решения предлагается концепция зеркала данных (data mirror).
Это специальное приложение, которое непрерывно работает на клиентской стороне в фоновом режиме — и постоянно синхронизирует локальный архив со всеми внешними сервисами. Приложение как бы «высасывает» ваши данные из разных программ и веб-сервисов, сохраняя в открытый машиночитаемый формат вроде JSON/SQLite. По сути, оно строит на диске это самое личное хранилище, которое в будущем должно вместить в себя все виды персональной информации.
На самом деле ещё не создано такое универсальное приложение, которое бы автоматически высасывало информацию всех форматов и типов из всего разнообразия существующих сторонних приложений и сервисов — и сохраняло локально.
Эту работу приходится делать в полуручном режиме.
Речь о том, чтобы выполнять экспорт информации со всех сервисов и программ, которые это позволяют. Экспорт в максимально возможном универсальном формате — и хранение этих данных в архиве. В будущем появится возможность проиндексировать и удобно работать с этими данными, а сейчас наша главная задача — сохранить их, чтобы они не исчезли навсегда.
Люди понимают, насколько важно сохранить навсегда личные фотографии. Но мало кто осознаёт то же самое для истории чатов во всех мессенджеров, а ведь это поистине бесценная летопись жизни человека. Эта информация с годами стирается из человеческой памяти.
Например, чаты ICQ хранились в простом текстовом виде, так что не нужно было предпринимать особых усилий для их сохранения. Так вот, если сейчас прочитать свои чаты из 90-х годов, то вы откроете заново целый пласт личной истории, которую уже давно забыли. Пожалуй, это очень важная часть персонального архива.
Так же важны медицинские данные о состоянии здоровья, пульсе, давлении, времени сна и других характеристиках, которые сейчас измеряются в течение жизни фитнес-трекерами.

Визуализация более миллиона электронных писем, которые Стивен Вольфрам отправил с 1989 года, показывает нарушения сна в годы напряжённой работы
Чтобы упростить себе регулярный экспорт/скрапинг личных данных из разных программ @karlicoss написал ряд скриптов для Reddit, Messenger/Facebook, Spotify, Instapaper, Pinboard, Github и других сервисов, которыми он пользуется.
В идеале, эти программы позволяют найти любое сообщение или заметку, то есть практически любую вашу мысль из прошлого, где бы она ни была зафиксирована — в чате Telegram или Вконтакте, комментарии на Хабре, прочитанной книге или в коде, который вы писали. Вся информация хранится в единой базе с полнотекстовым поиском.
Софт
Вместо облачных корпоративных сервисов нужно переходить на локально-ориентированный софт (local-first software). Он так называется по контрасту с облачными приложениями.
Локально-ориентированный софт работает гораздо быстрее, с меньшей задержкой, чем облачные приложения, потому что здесь при нажатии одной кнопки пакеты не путешествуют по всему земному шару, а все данные хранятся локально.

Предусмотрена синхронизация локальных данных между всеми устройствами, полный контроль человека над его данными, работа в офлайне в первую очередь (движение Offline First), безболезненное решение конфликтов в совместной работе, максимальная защищённость информации, длительная сохранность данных для наших потомков, как тот расчётный лист вавилонского рабочего выше (кстати, в 2016 году расшифровка текста выявила, что труд вавилонского рабочего оплатили спиртным напитком, а конкретно пивом).
Таким образом, локально-ориентированный софт соответствует всем семи обозначенным принципам. По мнению специалистов, лучше всего для реализации такого программного обеспечения подходят структуры данных типа CRDT (conflict-free replicated data type). Эти структуры данных могут реплицироваться среди множества компьютеров в сети, причём реплики обновляются независимо и конкурентно без координации между ними, но при этом всегда сохраняется математическая возможность устранить несогласованность. Это модель сильной согласованности в конечном счёте (Strong Eventual Consistency).
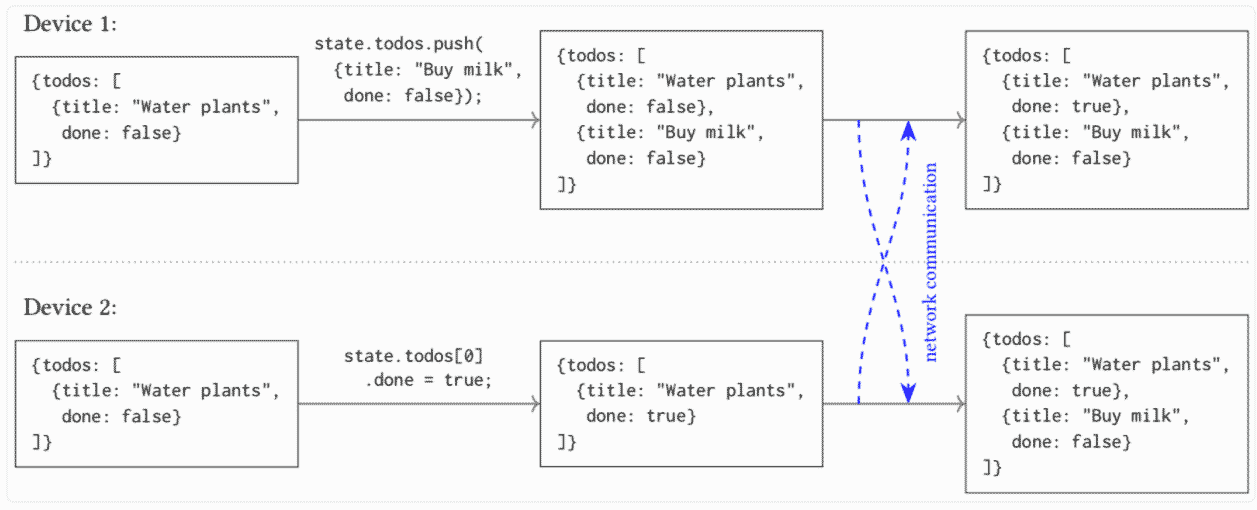
Благодаря такой модели согласованности структуры данных CRDT похожи на системы контроля версий типа Git. Для лучшего знакомства с CRDT можно почитать статью Алексея Бабулевича.
Гит-скрапинг
Идея освобождения личных данных из «корпоративного рабства» с долговременным локальным хранением в последнее время приобретает особую популярность. Жизнь показала, что от коммерческих веб-сервисов ничего хорошего ждать не приходится. Поэтому отдельные разработчики пытаются создать примеры личных информационных хранилищ.
Например, FOSS-разработчик и консультант Саймон Уиллисон работает над двумя инструментами Datasette и Dogsheep, которые весьма полезны для личных хранилищ.
Datasette — веб-приложение для обработки данных и публикации их в читаемом формате, в виде интерактивного веб-сайта (демо). Это лишь один элемент большой экосистемы Datasette — опенсорсных инструментов для сбора, анализа и публикации интересных данных. Экосистема делится на две части: инструменты для построения баз данных SQLite (для использования с Datasette) и плагины, которые расширяют функциональность Datasette.
Разные плагины позволяют комбинировать данные друг с другом. Например, накладывать координаты объектов из одной базы данных на географическую карту.
Уиллисон экспериментирует с регулярным скрапингом разных сайтов с публикацией данных в репозитории GitHub. Получается срез данных по изменению некоего объекта во времени. Он называет эту технику гит-скрапингом. В дальнейшем собранные данные можно преобразовать и Datasette.
См. примеры гит-скрапинга на Github. Это одна из ключевых техник для наполнения информацией личного хранилища данных — в стандартном открытом формате для долговременного хранения.

Предстоит ещё долгий путь, чтобы освободить свои данные и создать инфраструктуру для надёжного и безопасного хранения личной информации. В будущем можно представить, что эта информация включит в себя также воспоминания и эмоции, которые снимаются с нейро-компьютерного интерфейса типа Neuralink, так что в совокупности хранилище будет практически полностью отражать личность владельца, представляя своеобразный «цифровой жизненный слепок» или аватар человека.
Очень вдохновляют отдельные примеры героических усилий по цифровизации своей жизни, как у Стивена Вольфрама. На фотографии слева — домашний RIAD-массив с его хранилищем информации за 40 лет.
Стивен Вольфрам старается журналировать все события в своей работе. Главное — их сохранить. А сохранить их можно только под своим контролем, на собственном сервере. Человек должен полностью контролировать и железо, и программное обеспечение, и данные, которыми он владеет.
На правах рекламы
Закажите и сразу работайте! Создание VDS любой конфигурации в течение минуты, в том числе серверов для хранения большого объёма данных до 4000 ГБ, CEPH хранилище на основе быстрых NVMe дисков от Intel. Эпичненько 🙂

- personal data services
- personal data store
- PDS
- локально-ориентированный софт
- local-first software
- JSON
- CRDT
- Datasette
- Dogsheep
- гит-скрапинг
- персональная аналитика
«Истина в последней инстанции» или зачем нужен Database First Design
В этой весьма запоздалой статье я объясню почему, по моему мнению, в большинстве случаев при разработке модели данных приложения необходимо придерживаться подхода «database first». Вместо «Java[любой другой язык] first» подхода, который выведет вас на длинную дорожку, полную боли и страданий, как только проект начнет расти.

«Слишком занят, чтобы стать лучше» Licensed CC by Alan O’Rourke / Audience Stack. Оригинальное изображение
Интересные reddit-обсуждения /r/java и /r/programming.
Кодогенерация
К моему удивлению, одна небольшая группа пользователей похоже была потрясена тем фактом, что jOOQ сильно «завязан» на генерации исходного кода.
При том, что вы можете использовать jOOQ именно так как вам удобно, предпочтительным способ (согласно документации) является начать именно с уже существующей схемы БД, затем сгенерировать необходимые клиентские классы (соответствующие вашим таблицам) с помощью jOOQ, а после этого уже спокойно писать типобезопасные запросы для этих таблиц:
for (Record2 record : DSL.using(configuration) // ^^^^^^^^^^^^^^^^^^^^^^^ Type information derived from the // generated code referenced from the below SELECT clause .select(ACTOR.FIRST_NAME, ACTOR.LAST_NAME) // vvvvv ^^^^^^^^^^^^ ^^^^^^^^^^^^^^^ Generated names .from(ACTOR) .orderBy(1, 2)) < // . >Код может генерироваться либо вручную вне сборки, либо автоматически с каждой сборкой. Например, такая генерация может происходить сразу же после установки Flyway-миграций, которые также могут запускаться как вручную, так и автоматически.
Генерация исходного кода
Существуют разные философии, преимущества и недостатки в отношении этих подходов к кодогенерации, которые я не хочу обсуждать в этой статье. Но по сути, смысл сгенерированного кода заключается в том, что он является Java-представлением того, что мы считаем неким «эталоном» (как внутри, так и снаружи нашей системы). В некотором роде компиляторы делают то же самое, когда генерируют байт-код, машинный код или какой-либо другой исходный код из исходников — в итоге мы получаем представление о нашем «эталоне» на другом специфичном языке.
Существует достаточно много таких генераторов кода. Например, XJC может генерировать Java-код из файлов XSD или WSDL. Принцип всегда один и тот же:
- Существует некий эталон (внешний или внутренний), такой как спецификация, модель данных и пр.
- Необходимо получить собственное представление об этом эталоне на нашем привычном языке программирования.
И почти всегда имеет смысл именно генерировать это представление, чтобы избежать лишней работы и лишних ошибок.
«Type providers» и обработка аннотаций
Примечательно, что еще один, более современный, подход к генерации кода в jOOQ — это Type Providers, (как он сделан в F#), где код генерируется компилятором при компиляции и никогда не существует в исходной форме. Аналогичный (но менее сложный) инструмент в Java — это обработчики аннотаций, например, Lombok.
В обоих случаях происходит все тоже самое что и в обычной кодогенерации, кроме:
- Вы не видите сгенерированный код (возможно, для многих это уже большой плюс?)
- Вы должны обеспечить доступность вашего «эталона» при каждой компиляции. Это не доставляет никаких проблем в случае с Lombok, который непосредственно аннотирует сам исходный код, который и является «эталоном» в данном случае. Немного сложнее с моделями баз данных, которые полагаются на всегда доступное «живое» соединение.
В чем проблема с генерацией кода?
Помимо каверзного вопроса, нужно ли генерировать код вручную или автоматически, некоторые люди считают, что код вообще не нужно генерировать. Причина, которую я слышу чаще всего — что такую генерацию сложно реализовать в CI/CD pipeline. И да, это правда, т.к. мы получаем накладные расходы на создание и поддержку дополнительной инфраструктуры, тем более если вы новичок в используемых инструментах (jOOQ, JAXB, Hibernate и др.).
Если накладные расходы на изучение работы кодогенератор слишком высоки, то действительно пользы будет мало. Но это единственный аргумент против. В большинстве остальных случаев совершенно не имеет никакого смысла вручную писать код, который является обычным представлением модели чего-либо.
Многие люди утверждают, что у них нет времени на это, т.к. именно сейчас нужно как можно скорее «выкатить» очередной MVP. А доработать свой CI/CD pipeline они смогут когда-нибудь потом. В таких случаях я обычно говорю: «Ты слишком занят, чтобы стать лучше».
«Но ведь Hibernate/JPA делает Java first разработку гораздо проще»
Да, это правда. Это одновременно и радость, и боль для пользователей Hibernate. С помощью него вы можете просто написать несколько объектов, вида:
@Entity class Book
И все, почти готово. Далее Hibernate возьмет на себя всю рутину по поводу того, как определить этот объект в DDL и на нужном SQL-диалекте:
CREATE TABLE book ( id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, title VARCHAR(50), CONSTRAINT pk_book PRIMARY KEY (id) ); CREATE INDEX i_book_title ON book (title);Это действительно отличный способ для быстрого старта разработки — остается только запустить приложение.
Но не все так радужно. Еще остается множество вопросов:
- Сгенерирует ли Hibernate нужное мне имя для первичного ключа?
- Создаст ли необходимый мне индекс на поле TITLE?
- Будет ли генерироваться уникальное значение ID для каждой записи?
Похоже, что нет. Но пока проект находится в стадии разработки, вы всегда можете выбросить свою текущую базу данных и сгенерировать все с нуля, добавив нужные аннотации к модели.
Итак, класс Book в конечном виде будет выглядеть примерно так:
@Entity @Table(name = "book", indexes = < @Index(name = "i_book_title", columnList = "title") >) class Book
Но вы заплатите за это, чуть позже
Рано или поздно ваше приложение попадает в production, и описанная схема перестанет работать:
В живой и настоящей системе вы больше не сможете просто так взять и выбросить свою базу данных, т.к. данные в ней используются и могут стоить кучу денег.
С этого момента вам необходимо писать скрипты миграций на каждое изменение в модели данных, например, используя Flyway. При этом, что происходит с вашими клиентскими классами? Вы можете либо адаптировать их вручную (что приведет к двойной работе), либо попросить Hibernate генерировать их (но насколько велики шансы того, что результат такой генерации будет соответствовать ожиданиям?). В итоге вас могут ожидать большие проблемы.
Как только код попадает в production, в него почти сразу необходимо вносить исправления, причем как можно быстрее.
И т.к. установка миграций БД не встроена в ваш сборочный конвейер, придется устанавливать такие патчи вручную на свой страх и риск. Чтобы вернуться назад и сделать все правильно уже не хватит времени. Его хватит только на то, чтобы винить Hibernate во всех своих бедах.
Вместо этого вы могли бы поступить совершенно иначе с самого начала. А именно использовать круглые колеса вместо квадратных.
Вперед к «Database First»
Эталон схемы данных и контроль над ней находится в ведомстве вашей СУБД. База данных — это единственное место, где определена схема, и все клиенты имеют копию этой схемы, но не наоборот. Данные находятся в вашей базе данных, а не в вашем клиенте, поэтому имеет смысл обеспечить контроль схемы и ее целостности именно там, где находятся данные.
Это старая мудрость, ничего нового. Первичные и уникальные ключи хороши. Внешние ключи прекрасны. Проверка ограничений на стороне БД замечательна. Assertion (когда они окончательно реализованы) великолепны.
И это еще далеко не все. Например, если вы используете Oracle, вы можете указать:
- В каком табличном пространстве находится ваша таблица
- Какое значение PCTFREE она имеет
- Каков размер кэша последовательности (sequence)
Возможно все это не имеет значения в небольших системах, зато в более крупных системах вам не придется идти по пути «больших данных», пока вы не выжмите все соки из своего текущего хранилища. Ни одна ORM, которую я когда-либо видел (в том числе jOOQ) не позволит вам использовать полный набор параметров DDL, которые предоставляет ваша СУБД. ORM предлагают только некоторые инструменты, которые помогут написать DDL.
В конечном счете, хорошо продуманная схема должна быть написана только вручную с помощью СУБД-специфичного DDL. Весь автоматически сгенерированный DDL являются лишь приближением к этому.
Что насчет клиентской модели?
Как уже упоминалось ранее, вам понадобится некое представление схемы БД на стороне клиента. Излишне говорить, что это представление должно быть синхронизировано с реальной моделью. Как это сделать? Конечно же используя генераторы кода.
Все базы данных предоставляют доступ к своей метаинформации посредством старого доброго SQL. Вот так, например, можно получить список всех таблиц из разных баз данных:
-- H2, HSQLDB, MySQL, PostgreSQL, SQL Server SELECT table_schema, table_name FROM information_schema.tables -- DB2 SELECT tabschema, tabname FROM syscat.tables -- Oracle SELECT owner, table_name FROM all_tables -- SQLite SELECT name FROM sqlite_master -- Teradata SELECT databasename, tablename FROM dbc.tablesИменно такие запросы (а также аналогичные запросы для представлений, материализованных представлений и табличных функций) выполняются при вызове метода DatabaseMetaData.getTables() конкретного JDBC-драйвера, либо в модуле jOOQ-meta.
Из результатов таких запросов относительно легко создать любое клиентское представление модели БД, независимо от того, какая именно технология доступа к данным используется.
- Если вы используете JDBC или Spring, вы можете создать группу String-констант
- Если используете JPA, можете сами создавать объекты
- Если используете jOOQ, можете создать метамодели jOOQ
В зависимости от количества функций, предлагаемых вашим API доступа к данным (jOOQ, JPA или что-то еще), сгенерированная метамодель может быть действительно богатой и полной. Как пример, функция неявного соединения в jOOQ 3.11, которая опирается на метаинформацию о взаимоотношениях внешних ключей между вашими таблицами.
Теперь любое изменение схемы базы данных автоматически приведет к обновлению клиентского кода.
Представьте, что нужно переименовать колонку в таблице:
ALTER TABLE book RENAME COLUMN title TO book_title;Вы уверены, что хотите выполнить эту работу дважды? Ни за что. Просто закомитьте этот DDL, запустите сборку и наслаждайтесь обновленным объектом:
@Entity @Table(name = "book", indexes = < // Would you have thought of this? @Index(name = "i_book_title", columnList = "book_title") >) class Book
Так же полученный клиентский нет необходимости компилировать каждый раз (как минимум до следующего изменения в схеме БД), что уже может быть большим плюсом!
Большинство изменений DDL также являются семантическими изменениями, а не только синтаксическими. Таким образом, здорово видеть в сгенерированном коде клиента на что именно повлияли последние изменения в БД.
Правда всегда одна
Независимо от того, какую технологию вы используете, всегда должна быть только одна модель, которая и является эталоном для подсистемы. Или, как минимум, мы должны стремиться к этому и избегать неразберихи в бизнесе, где «эталон» есть везде и нигде одновременно. Это делает все намного проще. К примеру, если вы обмениваетесь XML-файлами с какой-либо другой системой, вы наверняка используете XSD. Как метамодель INFORMATION_SCHEMA jOOQ в формате XML: https://www.jooq.org/xsd/jooq-meta-3.10.0.xsd
- XSD хорошо понятен
- XSD отлично описывает XML-контент и позволяет осуществлять валидацию на всех клиентских языках
- XSD позволяет легко управлять версиями и сохранять обратную совместимость
- XSD можно превратить в Java-код с помощью XJC
Обратим отдельное внимание на последний пункт. При общении с внешней системой через XML-сообщения мы должны быть уверены в валидности сообщений. И это действительно очень легко сделать с помощью таких вещей как JAXB, XJC и XSD. Было бы сумасшествием думать об уместности Java-first подхода в данном случае. Генерируемый на основе объектов XML получится низкого качества, будет плохо задокументирован и трудно расширяем. И если на такое взаимодействие есть SLA, то вы будете разочарованы.
Честно говоря, это похоже на то, что сейчас происходит с различными API для JSON, но это уже совершенна другая история.
Чем базы данных хуже?
При работе с БД тут все тоже самое. База данных владеет данными, и она так же должна быть хозяином схемы этих данных. Все модификации схемы должны быть выполнены посредством DDL напрямую, чтобы обновить эталон.
После обновления эталона все клиенты должны обновить свои представления о модели. Некоторые клиенты могут быть написаны на Java, используя либо jOOQ и/или Hibernate, либо JDBC. Другие клиенты могут быть написаны на Perl (удачи им) или даже на C#. Это не имеет никакого значения. Основная модель находится в базе данных. Тогда как модели, созданные с помощью ORM, имеют низкое качество, недостаточно хорошо документированы и трудно расширяемы.
Поэтому не делайте этого, причем с самого начала разработки. Вместо этого начните с базы данных. Создайте автоматизированный CI/CD конвейер. Используйте в нем генерацию кода, чтобы автоматически генерировать модель базы данных для клиентов при каждой сборке. И перестаньте волноваться, все будет хорошо. Все что требуется — немного первоначальных усилий по настройке инфраструктуры, но в результате вы получите выигрыш в процессе разработки для остальной части вашего проекта на годы вперед.
Не надо благодарностей.
Пояснения
Для закрепления: эта статья никоим образом не утверждает, что модель базы данных должна распространяться на всю вашу систему (на предметную область, бизнес-логику и пр.). Мои заявления заключается лишь в том, что клиентский код, взаимодействующий с базой данных, должен быть лишь представлением схемы БД, но никак не определять и не формировать ее.
В двухуровневых архитектурах, которые по-прежнему имеют место быть, схема БД может быть единственным источником информации о модели вашей системы. Однако в большинстве систем я рассматриваю уровень доступа к данным как «подсистему», которая инкапсулирует модель базы данных. Как-то так.
Исключения
Как и в любом другом хорошем правиле, в нашем тоже есть свои исключения (и я уже предупреждал, что подход database first и генерация кода не всегда является правильным выбором). Вот эти исключения (возможно, список не полный):
- Когда схема неизвестна заранее и ее необходимо исследовать. Например, вы поставщик инструмента, помогающего пользователям осуществлять навигацию по любой схеме. Само собой, тут не может быть никакой генерации кода. Но в любом случае, придется иметь дело с самой БД напрямую и ее схемой.
- Когда для какой-то задачи необходимо создать схему «на лету». Это может быть похоже на одну из вариаций паттерна Entity-attribute-value, т.к. у вас нет четко определенной схемы. Также как и нет уверенности, что RDBMS в данном случае это верный выбор.
Особенность этих исключений в том, что они довольно редко всречаются в живой природе. В большинстве же случаев при использовании реляционных БД схема заранее известна и является «эталоном» вашей модели, а клиенты должны работать с копией этой модели, сгенерированной с использованием генераторов кода.
Концепция Digital First, современные ИТ-компании и коррекция Минцифры
Цифровая составляющая стала основной в современном бизнесе, а не дополнительной и тем более не служебной — к такому выводу пришли аналитики IDC. Ситуацию рассматривают как дальнейшее развитие «цифровой трансформации» (DX), динамика которой активизирована как естественными процессами в экономике и ИТ, так и форс-мажорами двадцатых годов.
В происходящем есть своя логика
Процессы внедрения компьютеров в бизнес — от разработки и торговли до логистики и производства — проходили в четыре этапа. Три нам знакомы, а четвертым является Digital First.
Первым этапом принято считать «оцифровку», когда корпоративные пользователи информацию переносили с бумажных носителей в компьютеры. Например, амбарные книги или зарплатные ведомости стали вести не только на бумаге, но и в digital-формате. Однако оцифровка не изменяла структуры компании, бизнес-процессы, бизнес-модели и т. д., они оставались по сути «аналоговыми», просто получая цифровое «отражение».
Второй этап — «цифровизация», которая возможна при накоплении цифровых данных в количестве, достаточном для аналитики, на основании которой компании могут оптимизировать бизнес- и технологические процессы. Процессы изменений стало возможно моделировать, тестируя управленческие гипотезы в цифровой среде, что радикально снижает риск при выполнении изменений в физическом мире. На этом этапе бизнес становится все более data driven.
DX — третий этап, при котором происходит слияние операционной деятельности и цифровых технологий, а поэтому обеспечивается синергия инструментов из двух миров: цифрового и физического. В компаниях, которые окончательно становятся киберфизическими структурами, DX ведет к реорганизации ряда процессов как внутренних, так и предусматривающих взаимодействие с внешним миром: поставщиками, покупателями, партнерами, регуляторами, аудиторами и т. д. Эти изменения могут обеспечить бизнесу оптимизацию и конкурентные преимущества, приводя к значительному росту эффективности, что будет видно по ряду бизнес-показателей.
Классический пример — изменение в результате DX бизнес-модели у таксопарков. Компании либо прошли «цифровую трансформацию» — поменяв модель на «uber’образную» или, предположим, превратившись в каршеринг — либо были вынуждены навсегда уйти с рынка. Данный канонический пример стал показательным.
Digital First — это «DX сегодня»
Цифровые технологии достаточно быстро стали определяющими для эффективности операционной деятельности, что и отражено в концепции Digital First. Компании в первую очередь оптимизируют бизнес-процессы и софт, что является путем для достижения конкурентного превосходства или как минимум оптимизации и повышения эффективности. Физические активы все больше становятся «исполнительными механизмами», которые реализуют команды софта, определяемые бизнес-логикой.
Например, упомянутые таксопарки, разумеется, должны иметь в распоряжении парк чистых и исправных авто, оптимальных по стоимости владения, и штат качественных водителей. Но в современных условиях не получить конкурентное преимущество ни техобслуживанием, ни мойкой авто, ни традиционными методами HR по подбору и контролю персонала — все это элементы необходимые, но не достаточные. Нужна модификация и оптимизация софта, что позволит быстрее и эффективней работать с имеющимся ресурсом.
Например, анализ параметров вождения каждого водителя позволит определить его квалификацию и получить ответы на ряд актуальных вопросов (его лучше уволить, послать на курсы или перевести на обслуживание перевозок более высокого класса?). Данные пригодятся для скоринга (индивидуальной оценки страховых рисков), что позволяет оптимизировать условия страхования. Анализ позволит уточнить периодичность техобслуживания и сделает возможным проактивные реакции на возможные неисправности. Оптимизация мобильного клиента и серверной составляющей естественным образом позволит поднять степень удовлетворенности клиентов.
Аналогичные примеры можно привести с курьерскими службами, логистикой, агрокомплексами, ЖКХ, городскими районами, банками и сотнями других разноплановых структур, для которых оптимизация также является первоочередной задачей, позволяющей оптимизировать бизнес, получить конкурентные преимущества, увеличить прибыль и т. д. Разумеется, это же справедливо для государственного и муниципального управления — тут тоже ограничены возможности, поэтому на первое место выходит софт для оптимального управления имеющимися ресурсами, что позволит повысить уровень жизни и степень удовлетворенности жителей.
А что на российском рынке?
Процессы перехода от DX к Digital First в российской реальности тоже идут, причем начались достаточно давно и протекают активно. Например, концепция «Тинькофф — технологическая компания с банковской лицензией» широко известна благодаря агрессивному маркетингу, это революционно звучало несколько лет назад, но сейчас выглядит естественно, причем применима практически для любого банка.
Рынок банковских услуг достаточно коммодизирован, что делает крайне проблемным создание прорывных сервисов, имеющих значимые «killer features». Чтобы оптимизировать имеющиеся ресурсы, банки активно создают и развивают ИТ-сервисы, на основе которых снижают себестоимость внутренних процессов и, более того, предлагают рынку собственные цифровые товары.
ример: анализ BigData, который стараниями российских банков стал доступен не только для крупных корпораций и федеральных сетей, но и для СМБ. Напомним, что «Платформа ОФД» — оператор фискальных данных (ОФД), ЭДО и электронной отчетности, входящая в экосистему «Сбера» — сделал аналитику на основе агрегированных данных рабочим инструментом для многих: функция «Сравнение с рынком», доступная в личном кабинете ОФД, дает клиентам онлайн-доступ к анализу рыночного окружения, а также возможность сравнения своих показателей с другими игроками рынка и т. д. Это только один из многих примеров грамотной диверсификации бизнеса, в результате которой банки получают выгоды от работы с данными, ИТ-сервисов и пр.
Заметим, что сказанное актуально для операторов связи, девелоперов и многих других структур, которые становятся ИТ-компаниями с лицензиями на предоставление коммуникационных услуг, на строительство и проч.
ИТ-компания?
Упомянутый «Тинькофф банк» был внесен 6 июня в реестр российских ИТ-компаний Минцифры, где ранее находились несколько дочерних структур, например, «Тинькофф центр разработки». Вчера, 1 августа, «Тинькофф банк» был исключен из реестра российских ИТ-компаний вместе с «Альфа-банком», «Сбербанком» и рядом других банковских структур (всего в списке исключенных 32 банка). Какое это имеет отношение к рассмотренному выше? Никакого.
В данном случае признание — или непризнание — бизнеса «ИТ-компанией» лишь некоторый формализм, который открывает доступ к ряду льгот, предоставляемых государством цифровому сектору национальной экономики. Льготы хороши и разнообразны — более того, их список расширяют! — но они требуют затрат, накладных для госбюджета, а поэтому не могут действовать на протяжении длительного времени.
Однако «Тинькофф» и другие банки, исключенные из списка Минцифры, а также страховые структуры (их только во вчерашнем списке 12) и другие бизнесы, хотя и утратили формальный статус и причитающиеся льготы, остаются ИТ-компаниями. А концепция Digital First продолжает быстрое развитие и повсеместное проникновение.
Источник: Александр Маляревский, внештатный обозреватель IT Channel News
Становление концепции Data Driven маркетинга Текст научной статьи по специальности «Экономика и бизнес»
Data Driven организация / Data Driven маркетинг / Data Driven культура / цифровая революция / прогностическая аналитика. / Data Driven Organization / Data Driven Marketing / Data Driven Culture / Digital Revolution / Predictive Analytics.
Аннотация научной статьи по экономике и бизнесу, автор научной работы — Юлдашева Оксана Урняковна, Пирогов Дмитрий Евгеньевич
В статье рассматриваются проблемы становления Data Driven организаций и Data Driven маркетинга в цифровой экономике. Авторы показывают, что Data Driven организация строит процессы принятия решений не на интуиции, а на регулярном и систематическом сборе и анализе данных, а также на их продвинутой аналитике, которая должна носить прогностический характер. Создание Data Driven организаций требует предварительного формирования Data Driven культуры , которая исходит от топ-менеджеров и распространяется на всех сотрудников. Data Driven маркетинг часто является первым шагом к созданию Data Driven организации и так же построен на внедрении специализированных технологий автоматического сбора и обработки клиентских данных. В статье показаны этапы создания Data Driven организации , модель и структура элементов Data Driven маркетинга и мероприятия по его становлению в компании.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по экономике и бизнесу , автор научной работы — Юлдашева Оксана Урняковна, Пирогов Дмитрий Евгеньевич
ПРИМЕНЕНИЕ BIG DATA МАЛЫМ БИЗНЕСОМ В СОВРЕМЕННОМ МАРКЕТИНГЕ
СИСТЕМАТИЗАЦИЯ ФЕНОМЕНОВ ЦИФРОВИЗАЦИИ МАРКЕТИНГА: КОНЦЕПЦИЯ И ПРИМЕР РЕАЛИЗАЦИИ
Классификация ИКТ в маркетинговой деятельности современных предприятий. Влияние ИКТ на эффективность работы предприятий
ОРГАНИЗАЦИЯ CRM-АНАЛИТИКИ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ DATA MINING
Цифровой маркетинг как современный тренд
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Data Driven Marketing: Concept Development
The article deals with the problems of the formation of Data Driven organizations and Data Driven marketing in the digital economy. The authors show that a Data Driven organization builds its decision-making processes not on intuition, but on regular and systematic data collection and analysis, as well as on their advanced analytics, which should be predictive in nature. Creating a Data Driven organization requires the preliminary formation of a Data Driven culture that comes from top managers and extends to all employees. Data driven marketing is often the first step towards creating a data driven organization and is also built on the introduction of specialized technologies for the automatic collection and processing of customer data. The article shows the stages of creating a Data driven organization , the model and structure of the elements of Data Driven marketing and measures for its formation in the company.
Текст научной работы на тему «Становление концепции Data Driven маркетинга»
В статье рассматриваются проблемы становления Data Driven организаций и Data Driven маркетинга в цифровой экономике. Авторы показывают, что Data Driven организация строит процессы принятия решений не на интуиции, а на регулярном и систематическом сборе и анализе данных, а также на их продвинутой аналитике, которая должна носить прогностический характер. Создание Data Driven организаций требует предварительного формирования Data Driven культуры, которая исходит от топ-менеджеров и распространяется на всех сотрудников. Data Driven маркетинг часто является первым шагом к созданию Data Driven организации и так же построен на внедрении специализированных технологий автоматического сбора и обработки клиентских данных. В статье показаны этапы создания Data Driven организации, модель и структура элементов Data Driven маркетинга и мероприятия по его становлению в компании.
Ключевые слова: Data Driven организация; Data Driven маркетинг; Data Driven культура; цифровая революция; прогностическая аналитика.
СТАНОВЛЕНИЕ КОНЦЕПЦИИ DATA DRIVEN МАРКЕТИНГА
Юлдашева Оксана Урняковна,
д.э.н., профессор, заведующий кафедрой маркетинга, Санкт-Петербургский государственный экономический университет, член Европейской Академии маркетинга (EMAC); ул. Садовая, 21, г. Санкт-Петербург, Россия, 119571 uldasheva2006@yandex.ru
Пирогов Дмитрий Евгеньевич,
аспирант кафедры маркетинга, Санкт-Петербургский государственный экономический университет;
ул. Садовая, 21, г. Санкт-Петербург, Россия, 119571
Цифровая революция — этот термин отражает переход от аналоговых технологий к цифровым, а также быстрое и повсеместное распространение коммуникационно-информационных технологий, среди которых наиболее трансформационными являются персональные компьютеры, интернет и персональные портативные коммуникационные устройства (типа смартфонов). Начавшись еще в 80-х годах, сегодня цифровая революция вступила в свою решающую фазу, а придавшая ей скорости пандемия способствовала фактически ее полной победе. Современная жизнь прочно связана с цифровым миром, роботами, искусственным интеллектом, big data и всеми другими атрибутами циф-
ровизации, что существенно меняет поведение как потребителей, так и компаний. Компании вынуждены ориентироваться на использование цифровых технологий, сбор и анализ большого количества данных для поддержания своей конкурентоспособности. Именно сектор цифровой экономики растет и создает предпосылки для роста бизнеса.
Так, цифровая экономика растет в 2,5 раза быстрее мирового ВВП. Согласно данным Аналитического центра при правительстве РФ, рост ВВП РФ на горизонте до 2030 года более чем на половину связан с цифровизацией1.
В связи с этим компании активно внедряют новое программное обеспечение, а сектор ИКТ демонстрирует опережающий рост.
В подтверждение этому, результаты 2020 года в России показывают, что отрасль информационно-телекоммуникационных технологий (ИКТ) вошла в число лидеров по динамике валовой добавленной стоимости — рост составил 2,8% (в постоянных ценах) по сравнению с 2019 годом2. Основной рост внутри сектора ИКТ продемонстрировали информационныетехнологии (12,7% роста в постоянных ценах), а также оптовая торговля ИКТ-товарами (30,9% роста). И это на фоне общего падения экономики РФ на 2,8%.
Согласно Gartner, рост сектора ИКТ продолжился и в 2021 году, достигнув по результатам года +8,4% в мировом масштабе3.
На фоне таких событий стремительно меняется мир бизнеса
1 Чукарин А. Цифровая экономика России: оценка и стратегии развития регионов, Аналитический центр при Правительстве РФ,
15.06.2021. https://itforum.admhmao.ru/upload/iblock/d2c/TSifrovaya-ekonomika-Rossii-_CHukarin-A.V._.pdf (08.12.20210).
2 Cектор ИКТ выработал иммунитет к COVID-перегрузкам. Исследование Института статистических исследований и экономики знаний
(ИСИЭЗ) НИУ ВШЭ. https://issek.hse.ru/news/446639217.html (08.12.2021).
3 Gartner: в 2021 году мировой рынок ИТ превысит 4 триллиона долларов, 08.04.2021. https://www.computerworld.ru/news/Gartner-v-
и, конечно, маркетинга. Так, все более популярной становится концепция Data Driven маркетинга и Data Driven организации, которые поддерживают переход в компании к более продвинутому уровню сбора и обработки данных и использованию аналитики. В чем суть данных концепций и как они внедряются в компаниях будет рассмотрено в данной статье.
DATA DRIVEN ОРГАНИЗАЦИЯ
И DATA DRIVEN МАРКЕТИНГ —
В 2021 году один из ведущих академических журналов Journal of Business Research подготовил выпуск, посвященный теме развития Data Driven маркетинга под названием «Marketing in a Data-Driven Digital World» (вып.125, 2021). В установочной статье к данному выпуску Дэниш Шах и Б. Мурси продемонстрировали эволюцию роли маркетинг-аналитики, начиная с акцента на аналитике в рекламе для создания эффективного креатива для клиентов, затем в развитии аналитики для поддержки клиентоцентрич-ности компании и продаже правильного продукта правильному клиенту и в правильное время и далее к использованию в маркетинге биг-дата и технологий искусственного интеллекта [1].
Действительно, в начале 2000-х маркетинг потребовал все больших способностей обработки возросшего объема данных о клиентах, все более актуальной стала работа с большими данными, что коренным образом изменило способ работы маркетинговой функции в организации. Быстрое проникновение Интернета, распространение смартфонов и более широкое использование социальных сетей обеспечили тройной эффект для беспрецедентного
сбора данных, большая часть которых стала поступать из цифровой сферы. Данных стало не только много, их стало легко архивировать и хранить, хранение данных стало все более цифровым, а затраты на хранение быстро снизились. Данные очень быстро превратились в большие данные, которые потребовали новых методов обработки.
Большие данные — термин, который используется для описания больших объемов сложных наборов данных, состоящих как из структурированных, так и неструктурированных данных. Большие данные требуют применения новой нетрадиционной методологии обработки данных. К современным методам обработки данных относят сложные статистико-ма-тематические модели, позволяющие не только прогнозировать будущее с определенной вероятностью, но и предсказывать конкретные последствия и исходы событий при отсутствии и наличии влияния на них со стороны управляющего субъекта. Все более важную роль сегодня играют методы обработки естественной ин-формации,которую маркетологи получают непосредственно из социальных сетей и обрабатывают с помощью современного языка программирования Python.
В современном бизнесе постоянно растут требования к оцифровке маркетинговых данных и их способности отражать влияние маркетинговых действий на прибыль организации. Рост затрат на маркетинг заставляет руководство компаний требовать окупаемости маркетинговых мероприятий. Это также приводит к совершенствованию методов маркетинг-аналитики.
Современный маркетинг 21 века построен на эффективном исполь-
зовании цифровых технологий искусственного интеллекта, машинного обучения, data mining, технологий интеллектуального анализа данных — распознавания лиц и речи, обработки изображений, выявления мошенничества и т.п. Чат-боты, виртуальные помощники и другие технологии, включенные в наши мобильные приложения, программы, клиентские сервисы, помогают покупателям справляться с огромными объемами данных для выбора той информации, которая действительно релевантна и помогает выбирать продукты, отвечающие требованиям потребителей.
Таким образом, используя свою способность собирать и обрабатывать данные для поддержки принятия клиентоориентирован-ных решений, маркетинг постепенно из функции, которая поддерживала в основном рекламный креатив, превратился в функцию, которая активно использует современные цифровые технологии для обеспечения предсказуемых и прибыльных решений для организации, которые поддерживают клиентоцентричность.
Шет и Келлштадт в своей статье делают важный вывод: «В прошлом техники (обработки данных) занимались поиском данных. В будущем данные будут в поиске техник(обработки данных)»[2, стр. 781]. Речь о том, что раньше развивались техники, с помощью которых можно было бы собирать данные, а сейчас нужны техники обработки огромного объема данных, которые могут помочь получить объективное знание и правильно принять решение.
Компания IBM утверждает, что только 0,5% данных о клиентах в реальности когда-либо обрабатывались. Технологии искусственного интеллекта, которые
разрабатывает IBM, нацелены на обработку данных, которые по-другому никогда не будут систематизированы и использованы в бизнесе для улучшения клиентского опыта.
Таким образом, Data driven маркетинг или маркетинг, движимый данными, нацелен на постоянное и как можно более полное и эффективное обеспечение системы принятия решений клиентскими данными, которые при грамотной обработке можно превратить в знания, а значит — в будущий маркетинговый капитал. Знания о клиентах способны приносить прибыль, а значит — клиентские знания становятся важнейшим активом, которым управляет маркетинг.
ПОДХОДЫ К СОЗДАНИЮ DATA
Глобальный институт McKinsey утверждает, что организации, ориентированные на данные, в 23 раза чаще приобретают клиентов, в 6 раз чаще удерживают клиентов и в 19 раз чаще становятся прибыльными4. Такие компании используют данные для поиска идей, меняющих традиционные правила игры. Новые идеи дают новые положительные результаты, такие как улучшение процесса принятия решений, улучшение бизнес-операций и усиление взаимодействия с клиентами.
Такие организации стали называть Insight Driven, а позже Data Driven. Суть этого термина в том, что организация начинает использовать продвинутую аналитику данных, которая позволяет принимать превентивные решения, основанные на предварительных прогнозах [3].
Что же такое продвинутая аналитика? Аналитику можно разделить
на: описательную, прогнозную и предписывающую (Davenport, 2013) [4].
Описательная аналитика помогает организациям анализировать то, что уже произошло или происходило в прошлом. Хранилище данных — типичный пример описательного подхода к сбору и анализу прошлых событий. Прогнозная аналитика помогает организациям обнаруживать ранее неизвестные закономерности в своих данных с помощью инструментов интеллектуального анализа данных. Предписывающая аналитика помогает организациям автоматизировать решения и тем самым извлекать выгоду из ранее обнаруженных инсайтов. Прогнозная и предписывающая аналитики и представляют собой продвинутую аналитику.
Организации обращаются к продвинутой аналитике в надежде обнаружить новые бизнес-идеи и извлечь из них выгоду. Переход к продвинутой аналитике требует навыков и специальных компетенций, которые обычно отсутствуют в организации. Их нужно создать. И тогда компании нанимают специалиста по анализу данных (data scientist), либо обращаются за помощью в специализированную компанию. Но если компания понимает, что она постоянно нуждается в такой аналитике и это становится частью ее процесса принятия решений, то компания должна ставить задачу создания Data Driven Culture (Franks, 2014) [5], следствием которой и станет Data Driven организация (Anderson, 2015) [6].
Лидеры аналитики говорят, что аналитика приносит больше пользы, когда инструменты дают представление о будущем, а не просто хорошо структурируют
прошлое. Прогнозное моделирование, особенно для поддержки инноваций, в настоящее время является наиболее продвинутой стадией эволюции аналитики. Маркетинг же может стать одним из первых подразделений компании, которое перейдет на продвинутую аналитику и таким образом будет стимулировать создание Data Driven Culture и в конечном итоге Data Driven организации.
Таким образом, ключевой компетенцией Data Driven организации являются ее аналитические способности [7].
Переход к Data Driven организации всегда связан с созданием и развитием Data Driven Culture [4], важными элементами которой являются лидерство, информационная стратегия, процессы принятия решений, основанные на данных (а не на интуиции), гибкая структура управления данными. Все это будет способствовать переходу от интуитивного принятия решений к решениям, основанным на данных и их анализе. Этот процесс может оказаться долгим для многих организаций в силу неготовности не столько персонала, сколько самого топ-менеджмента, который должен стать агентом изменений и первым перейти на принятие решений, основанных на данных. Такой пример лидерства может стимулировать других сотрудников последовать примеру руководителя и процесс сдвинется с места.
Практика формирования Data Driven Culture показывает, что обычно все начинается с внедрения в компанию агента изменений в виде нового сотрудника, который и должен создать организацию, движимую данными (цифровой директор). Вокруг этого
4 Five facts: How customer analytics boosts corporate performance. July 01, 2014. McKinsey. https://www.mckinsey.com/ (14.12.2021).
сотрудника собирается команда специалистов, которые разрабатывают информационную (цифровую) стратегию и воплощают ее в жизнь (рис.1, А).
Но так делают крупные компании, которые инвестируют существенные средства в диджитализацию и аналитику. А малый и средний бизнес начинает свой путь в анализ данных с маркетинга, поскольку маркетинг — основная функция, которая ежедневно имеет дело с данными и от того, как эти данные обрабатываются, зависят многие решения, принимаемые в компании.
В связи с этим маркетологи часто становятся зачинщиками процесса создания Data Driven Culture и Data Driven организации, внедряя Data Driven маркетинг. Data Driven маркетинг по аналогии с Data Driven организацией — это маркетинг, построенный на данных, когда все маркетинговые решения принимаются на анализе реальных данных, полученных из различных источников. Поэтому Data Driven маркетинг начинается с автоматизации процессов сбора и обработки маркетинговых данных (рис. 1, Б).
Начинают обычно с простых инструментов — Google Analytics и Яндекс Метрикс, затем внедряют CRM-систему. Многие сегодня используют Data Google Studio, позволяющий визуализировать данные из большого числа таблиц. Для анализа данных CRM-системы обычно дополнительно подключают BI системы.
Поскольку данные становятся все более разнообразными, и растет количество естественной информации (которая формируется естественным путем, а не по предварительному плану исследования), то все чаще компании исполь-
зуют специальные языки программирования типа Python, R, SQL, а также подключают специализированные программы по интеллектуальному анализу данных.
Основная задача Data Driven маркетинга — понять, сколько стоит привлечение клиента и какие каналы наиболее эффективны в этом процессе. Но если компания нацелена на удержание, а не на привлечение, то аналитика концентрируется на анализе поведения потребителей, а также определении наиболее эффективных инструментов поддержания отношений и взаимодействия с клиентом.
Вообще поведенческая аналитика становится все более актуальной для успешного бизнеса. В подтверждении этому в последние годы все активнее развивается концепция интернета поведения.
Под интернетом поведения (IoBB) понимается сбор данных (В/, Big Data, CDPs и т.д.), которые дают ценную информацию о поведении клиентов, их интересах и предпочтениях. Концепция IoBориентиро-вана на понимание данных, собранных в результате онлайн-ак-тивности пользователей, с точки зрения поведенческой психоло-
гии. Если понимание достигнуто, то следующий шаг — как применить эти знания для разработки и продажи новых продуктов, и все это с точки зрения человеческой психологии. Следующий этап 1оВ — это процесс анализа контролируемых пользовательских данных с точки зрения поведенческой психологии. Результаты этого анализа дают представление о новых подходах к проектированию пользовательского опыта (иХ), его оптимизации (ЭХО) и способах продвижения конечных продуктов и услуг, предлагаемых компаниями. Следовательно, для компании провести 1оВ технически просто, но психологически сложно. Это требует проведения статистических исследований, которые отображают повседневные привычки и поведение, не раскрывая полностью частную жизнь потребителей по этическим и юридическим причинам.
Кроме того, концепция 1оВ объединяет существующие технологии, которые ориентированы непосредственно на человека, такие как распознавание лиц, отслеживание местоположения и большие данные. Таким образом, это сочетание трех областей: технологий, анализа данных
Рис. 1. Формирование Data Driven culture в крупных компаниях и в МСП
и поведенческой психологии5. Например, компания — разработчик программного обеспечения BMC разработала приложение для смартфонов, которое отслеживает диету, режим сна, частоту сердечных сокращений или уровень сахара в крови. Приложение может предупреждать о неблагоприятных ситуациях со здоровьем пользователя и предлагать изменения в поведении для достижения более положительного результата.
Gartner прогнозирует, что к концу 2025 года более половины населения мира будет задействовано хотя бы в одной программе IoB.
КЕЙС С КОМПАНИЕЙ KIA MOTORS
Киа Моторс — крупнейший производитель автомобилей в мире и производитель с самой крупной рыночной долей в России. Компания активно использует маркетинговую аналитику для развития своей конкурентоспособности и кли-ентоориентированности.
Интервью с одним из ключевых сотрудников позволило выявить ряд особенностей по построению data driven организации, которые представлены на рисунке 2.
Киа Моторс некоторое время назад поставила задачу создать организацию, движимую данным. Для этого прежде всего она провела аудит всех источников данных и их валидизацию. Дело в том, что исследования в компании сильно децентрализованы. К примеру, продакт-менеджеры компании проводят регулярные клинические тесты до запуска новой модели в производство и тем более в продажу. Клинический тест представляет собой микс количественных и качественных методов, объединяя проверку работы технических
параметров автомобиля, его систем безопасности, включая использование цифровых двойников.
Сотрудники отдела развития оценивают покупательские ожидания относительно дизайна автомобиля, цены и т.п. Отдел маркетинга (коммуникаций) тестирует все, что связано с брендом нового автомобиля: бренд-трэкинг, бренд-воронка — оценка узнаваемости, фамильярити, мнение о бренде, лояльность бренду. Также анализируется полная веб-аналитика интернет-ресурсов, он-лайн-воронка. Для оценки потенциала рынка привлекаются синдикативные исследования — панельные исследования по автомобильному рынку, которые проводят исследовательские компании. Помимо этого, используется статистика ГИБДД для получения данных о регистрации автомобилей. Отдельное направление исследований — опросы aftersale (Voice of the customer) и опросы для определения CSI на разных стадиях покупки, а также результаты использования техники исследования качества обслуживания — Mystery shopper off и online.
Дистрибьюторы также проводят свои исследования и накапливают огромную базу данных
в своих CRM-системах о клиентском трафике и предпочтениях покупателей.
Рост онлайн продаж позволяет очень качественно оценивать эффективность рекламы и идентифицировать похожих пользователей для их последующего тарге-тирования.
Все эти данные могут оказаться разрозненными и не очень согласовываться, что требует проведения процедуры их валидизации, то есть оценки их объективности. Эта процедура может занять много времени.
Следующим шагом является интеграция данных, создание общих БД для предоставления доступа к ним всех заинтересованных лиц, чтобы исключить дублирование и повысить эффективность использования данных.
Наличие интегрированных БД позволяет нанимать специалистов по анализу данных — data scientists. Эти сотрудники являются основными проводниками data driven culture, поскольку внедряют культуру обязательного использования данных в процессе принятия решений.
Дальнейшим шагом к созданию движимой данными организации является оснащение автомобилей
Аудит всех источников данных и их валидизация
Интеграция данных (автоматизация и внедрение ПО)
Формирование Data Driven культуры и внедрение Data scientists
Установка телематики на автомобили и анализ данных по каждому пользователю
Рис. 2. Мероприятия в рамках создания Data Driven организации
5 What is the internet-of-behaviour job and why is it the future? 17.02.2021. Vector (consulting company). https://www.vectoritcgroup.com/ en/tech-magazine-en/ (19.11.2021)
телематикой, которая позволит изучать специфику их использования (или модели потребления). Эти данные помогут компании лучше управлять спросом для обеспечения повторных продаж иуправ-ления жизненным циклом покупателя.
МОДЕЛЬ DATA DRIVEN
Обзор подходов к становлению Data Driven маркетинга позволяет обрисовать его контуры в виде вербальной модели с выделением наиболее важных элементов.
На рисунке 3 представлен процесс принятия маркетинговых решений в рамках концепции Data Driven маркетинга. Начинается все с источников данных, которые использует компания. Источниками данных могут выступать как внутренние данные компании (например, данные CRM-системы, клиентских сервисов, которыми пользуются покупатели, приложений и т.п.), так и внешние данные, находящиеся в общем доступе — например, данные из социальных сетей, различных интернет-ресурсов. Очевидно, что источниками данных могут являться и классические опросы,а также вторичные данные, полученные от исследовательских компаний, служб статистики и т.п. Важно, чтобы данные охватывали как процесс принятия решения о покупке, то есть когда покупатель только ищет и сравнивает информацию для принятия решений, используя при этом различные источники данных, так и процесс потребления. Процесс потребления фиксируют датчики и сенсоры, установленные на смарт-продуктах, которыми пользуются потребители. В этом смысле получают доступ к данным, а значит — и потенциально выигрывают те компании, которые
первыми оснастят свои продукты таким оборудованием.
Следующий этап процесса принятия маркетинговых решений в Data Driven компании — это обеспечение этого процесса технологиями сбора, обработки, хранения и использования данных. Этот этап требует наличия четкой цифровой стратегии и понимания приоритетов в закупке и внедрении тех или иных технологий. Дело в том, что многие компании, внедряя самое современное программное обеспечение, обнаруживают, что не используют все его возможности, что существенно удлиняет сроки окупаемости. Даже внедрение дорогостоящих и многофункциональных CRM-си-стем не всегда оправдано. К примеру, в последнее время неким более продвинутым аналогом CRM-системы является платформа клиентских данных (CDP). Gartner в своем обзоре отмечает, что CDP — это многообещающая технология, но многие маркетологи, внедрившие ее, признают, что фактически используют ее в качестве CRMсистемы и только [8]. Таким образом, в попытке быть первыми в увеличении своих цифровых компетенций компании-лидеры замораживают в качестве инвестиций огромные средства,
которые могли бы использовать с большей отдачей, если бы внедряли только тот функционал цифровых технологий, который реально необходим в соответствии с цифровой стратегией.
Помимо этого, все более насущным становится вопрос использования клиентских данных — вопрос этики. Потребители все более негативно реагируют на использование компаниями персональных данных без их разрешения. Опасения также происходят из того, что основную массу персональных данных контролируют всего несколько цифровых гигантов. Отсюда любая компания, использующая продвинутую аналитику, должна строго соблюдать законодательство в отношении персональных данных и заботиться о сохранении доверия потребителей в отношении использования их данных.
Следующий этап процесса принятия маркетинговых решений — предикативная аналитика, которая требует как использования технологий искусственного интеллекта, так и специальных сотрудников — data scientists, которые самостоятельно строят модели, позволяющие предсказывать результаты тех или иных решений.
Наконец, последним этапом процесса принятия маркетинговых
Рис. 3. Элементы Data Driven маркетинга
решений является выбор окончательного решения на основе аналитики, а не интуиции. Те компании, которые выстроят процессы таким образом, как показано на рисунке 3, и будут являться движимыми данными.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Становление компаний и маркетинга, движимого данными, является частью цифровой зрелости организации. Согласно исследованиям консалтинговой фирмы UXSSR, 83% российских компаний находятся на 1-м и 2-м уровне цифровизации, когда у них все еще нет CRM-системы, организо-
ванного сбора и анализа данных, а также возможностей анализировать свою аудиторию и ее нужды6. Такая ситуация свидетельствует о том, что в России все еще можно вести бизнес, не обращая внимания на революцию в области цифровых технологий.
Россия — консервативная страна, и большинство компаний только приглядываются и прицениваются к новым цифровым технологиям. Однако времени остается все меньше, поскольку важны не столько технологии, сколько опыт их применения для создания совершенного клиентского опыта и формирования капитала марке-
тинговых знаний. А опыт невозможно получить быстро, он требует времени, которого остается все меньше и меньше.
В заключении добавим, что цифровые технологии уже завоевали мир, и игнорировать этот факт не удастся никому, особенно бизнесу. Поэтому чем раньше компании примут и будут развивать Data Driven культуру, тем скорее они адаптируются и получат возможность заменить процессы принятия решений, построенные на интуиции и высокой неопределенности, на процессы принятия решений, построенные на продвинутой аналитике.
1. Shah D., MurthiB.P.S. (2021) Marketing in a data-driven digital world: Implications for the role and scope of marketing, Journal of Business Research, March, 125, pp. 784-795.
2. Sheth J., Kellstadt C. (2021) Next frontiers of research in data driven marketing: Will techniques keep up with data tsunami? Journal of Business Research, Marcch 2021, 125, pp. 780-784.
3. De Saulles M. (2018) What exactly means data Driven Organization? CIO, October 28, 2018. https://www.cio.com/ article/3449117/what-exactly-is-a-data-driven-organization.html (23.12.2021).
4. Davenport T.H. (2013) Analytics 3.0. Harvard Business Review (December).
5. Franks B. (2014). The Analytics Culture The Analytics Revolution: Wiley.
6. Anderson C. (2015) Creating a Data-Driven Organization: O’Reilly Media.
7. Brown S. (2020) How to build a data driven company? Sloan School of Management, Sept. 24, 2020. https:// mitsloan.mit.edu/ideas-made-to-matter/how-to-build-a-data-driven-company.
8. Omale G. Top 5 Trends Drive Gartner Hype Cycle for Digital Marketing, 2020, September 1, 2020. https:// www.gartner.com/en/marketing/insights/articles/top-5-trends-drive-gartner-hype-cycle-digital-marketing-2020 (15.12.2021).
Data Driven Marketing: Concept Development Yuldasheva Oksana Urnyakovna,
Doctor of Economics, Professor, Head of the Department of Marketing, St. Petersburg State University of Economics, member of the European Academy of Marketing (EMAC), Sadovaya street 21, St. Petersburg, Russia, 119571 (uldasheva2006@yandex.ru)
Pirogov Dmitry Evgenievich,
post-graduate student of the Department of Marketing, St. Petersburg State University of Economics, Sadovaya street 21, St. Petersburg, Russia, 119571 (pirogovdm@gmail.com)
The article deals with the problems of the formation of Data Driven organizations and Data Driven marketing in the digital economy. The authors show that a Data Driven organization builds its decision-making processes not on intuition, but on regular and systematic data collection and analysis, as well as on their advanced analytics, which should be predictive in nature. Creating a Data Driven organization requires the preliminary formation of a Data Driven culture that comes from top managers and extends to all employees. Data driven marketing is often the first step towards creating a data driven organization and is also built on the introduction of specialized technologies for the automatic collection and processing of customer data. The article shows the stages of creating a Data driven organization, the model and structure of the elements of Data Driven marketing and measures for its formation in the company.
Keywords: Data Driven Organization; Data Driven Marketing; Data Driven Culture; Digital Revolution; Predictive Analytics.