Просмотр подов и узлов
Узнайте, как диагностировать проблемы с Kubernetes-приложениями с помощью kubectl get, kubectl describe, kubectl logs и kubectl exec.
Цели
- Узнать про поды Kubernetes
- Узнать про узлы Kubernetes
- Научиться диагностировать развёрнутые приложения
Поды Kubernetes
После того, как вы создали Deployment в модуле 2, Kubernetes создал под (Pod), в котором был размещён экземпляр вашего приложения. Под — это абстрактный объект Kubernetes, представляющий собой группу из одного или нескольких контейнеров приложения (например, Docker) и совместно используемых ресурсов для этих контейнеров. Ресурсами могут быть:
- общее хранилище (тома);
- сеть (уникальный IP-адрес кластера);
- информация о том, как запускать каждый контейнер, например, версия образа контейнера или используемые номера портов.
Под представляет специфичный для приложения «логический хост» и может содержать разные контейнеры приложений, которые в общем и целом тесно связаны. Например, в поде может размещаться как контейнер с приложением на Node.js, так и другой контейнер, который получает некоторые данные для их дальнейшей публикации на веб-сервере Node.js. Все контейнеры в поде имеют одни и те же IP-адрес и пространство портов, всегда размещаются и планируются для выполнения на одном и том же узле.
Поды — неделимая единица в платформе Kubernetes. При создании деплоймента в Kubernetes создаются поды с контейнерами внутри (вместо того, чтобы непосредственно создавать контейнеры). Каждый объект Pod связан с узлом (Node), на котором он размещён, и остаётся там до окончания работы (согласно стратегии перезапуска) либо удаления. В случае неисправности узла такой же под будет запланирован для запуска на других доступных узлах кластера.
Краткое содержание:
- Поды
- Узлы
- Основные команды kubectl
Под (Pod) — группа из одного или нескольких контейнеров приложений (например, Docker) и их общих хранилищ (томов), IP-адреса и информации о том, как их запускать.
Kubernetes 101: Поды, Ноды, Контейнеры, и Кластеры.
Kubernetes быстро становится новым стандартом для развертывания и управления программным обеспечением в облаке. Однако со всей мощью, которую предоставляет Kubernetes, придется пройти крутую кривую обучения. Новичку попытка разобрать официальную документацию может быть непосильной. Система состоит из множества разных частей, и бывает сложно определить, какие из этих частей подходят для вашего варианта использования. В этом сообщении в блоге будет представлен упрощенный взгляд на Kubernetes, но в нем будет предпринята попытка дать общий обзор наиболее важных компонентов, и того, как они взаимодействуют друг с другом.
Во-первых, давайте посмотрим, как представлено оборудование
Аппаратное обеспечение
Узлы (Ноды)
Узел — это наименьшая единица вычислительного оборудования в Kubernetes. Это представление одной машины в вашем кластере. В большинстве производственных систем узел, скорее всего, будет либо физической машиной в центре обработки данных, либо виртуальной машиной, размещенной у облачного провайдера, такого как Google Cloud Platform . Однако не позволяйте условностям ограничивать вас; теоретически можно сделать узел практически из чего угодно .
Представление о машине как об «узле» позволяет нам добавить слой абстракции. Теперь вместо того, чтобы беспокоиться об уникальных характеристиках каждой отдельной машины, мы можем просто рассматривать каждую машину как набор ресурсов ЦП и ОЗУ, которые можно использовать. Таким образом, любая машина может заменить любую другую машину в кластере Kubernetes.
Кластер
Хотя работа с отдельными узлами может быть полезна, это не путь Kubernetes. В общем, вы должны думать о кластере в целом, а не беспокоиться о состоянии отдельных узлов.
В Kubernetes узлы объединяют свои ресурсы, чтобы сформировать более мощную машину. Когда вы развертываете программы в кластере, он интеллектуально распределяет работу по отдельным узлам за вас. Если какие-либо узлы будут добавлены или удалены, кластер будет переключаться между работой по мере необходимости. Для программы или программиста не должно иметь значения, на каких машинах фактически выполняется код.
Если такая система, похожая на коллективный разум, напоминает вам Борга из «Звездного пути» , вы не одиноки; «Борг» — это название внутреннего проекта Google , на котором был основан Kubernetes.
Постоянные тома
Поскольку программы, работающие в вашем кластере, не гарантируют работу на определенном узле, данные не могут быть сохранены в любом произвольном месте в файловой системе. Если программа попытается сохранить данные в файл на потом, но затем будет перемещена на новый узел, файл больше не будет находиться там, где программа ожидает его видеть. По этой причине традиционное локальное хранилище, связанное с каждым узлом, рассматривается как временный кэш для хранения программ, но нельзя ожидать, что любые данные, сохраненные локально, сохранятся.
Для постоянного хранения данных Kubernetes использует постоянные тома . В то время как ресурсы ЦП и ОЗУ всех узлов эффективно объединены и управляются кластером, постоянное хранилище файлов — нет. Вместо этого локальные или облачные диски могут быть подключены к кластеру как постоянный том. Это можно рассматривать как подключение внешнего жесткого диска к кластеру. Постоянные тома предоставляют файловую систему, которую можно подключить к кластеру без привязки к какому-либо конкретному узлу.
Программное обеспечение
Контейнеры
Программы, работающие в Kubernetes, упакованы в контейнеры Linux . Контейнеры являются общепринятым стандартом, поэтому уже существует множество готовых образов , которые можно развернуть в Kubernetes.
Контейнеризация позволяет создавать автономные среды выполнения Linux. Любая программа и все ее зависимости могут быть объединены в один файл, а затем опубликованы в Интернете. Любой может скачать контейнер и развернуть его в своей инфраструктуре с минимальной настройкой. Создание контейнера может быть выполнено программно, что позволяет формировать мощные конвейеры CI и CD .
В один контейнер можно добавить несколько программ, но по возможности следует ограничиться одним процессом на контейнер. Лучше иметь много маленьких контейнеров, чем один большой. Если каждый контейнер имеет четкую направленность, обновления легче развертывать, а проблемы легче диагностировать.
Поды
В отличие от других систем, которые вы могли использовать в прошлом, Kubernetes не запускает контейнеры напрямую; вместо этого он оборачивает один или несколько контейнеров в структуру более высокого уровня, называемую подом . Все контейнеры в одном поде будут использовать одни и те же ресурсы и локальную сеть. Контейнеры могут легко взаимодействовать с другими контейнерами в одном модуле, как если бы они находились на одном компьютере, сохраняя при этом определенную степень изоляции от других.
Поды используются в качестве единицы репликации в Kubernetes. Если ваше приложение становится слишком популярным и один экземпляр модуля не может нести нагрузку, Kubernetes можно настроить для развертывания новых реплик вашего модуля в кластере по мере необходимости. Даже когда нагрузка невелика, стандартно иметь несколько копий модуля, работающих в любое время в производственной системе, чтобы обеспечить балансировку нагрузки и устойчивость к сбоям.
Поды могут содержать несколько контейнеров, но вы должны ограничивать себя, когда это возможно. Поскольку модули масштабируются вверх и вниз как единое целое, все контейнеры в поде должны масштабироваться вместе, независимо от их индивидуальных потребностей. Это приводит к напрасной трате ресурсов и дорогому счету. Чтобы решить эту проблему, поды должны оставаться как можно меньше, как правило, содержащие только основной процесс и его тесно связанные вспомогательные контейнеры (эти вспомогательные контейнеры обычно называются «сайд-карами»).
Деплойменты
Хотя поды являются базовой единицей вычислений в Kubernetes, они обычно не запускаются напрямую в кластере. Вместо этого модули обычно управляются еще одним уровнем абстракции: развертыванием .
Основная цель развертывания — объявить, сколько реплик пода должно работать одновременно. Когда развертывание добавляется в кластер, оно автоматически запускает запрошенное количество модулей, а затем отслеживает их. Если под умирает, развертывание автоматически воссоздает его.
Используя развертывание, вам не нужно иметь дело с подами вручную. Вы можете просто объявить желаемое состояние системы, и оно будет управляться автоматически.
Ingress (Точка входа)
Используя концепции, описанные выше, вы можете создать кластер узлов и запустить развертывание подов в кластере. Однако осталось решить еще одну проблему: разрешить внешний трафик для вашего приложения.
По умолчанию Kubernetes обеспечивает изоляцию между подами и внешним миром. Если вы хотите общаться со службой, работающей в поде, вам нужно открыть канал для связи. Это называется ingress (точка входа).
Есть несколько способов добавить точку входа в ваш кластер. Наиболее распространенными способами являются добавление контроллера Ingress или LoadBalancer . Точные компромиссы между этими двумя вариантами выходят за рамки этой статьи, но вы должны знать, что точка входа — это то, что вам нужно обработать, прежде чем вы сможете экспериментировать с Kubernetes.
Что дальше
То, что описано выше, — это упрощенная версия Kubernetes, но она должна дать вам основы, необходимые для начала экспериментов. Теперь, когда вы понимаете, из чего состоит система, пришло время использовать их для развертывания реального приложения. Ознакомьтесь с Kubernetes 110: Your First Deployment , чтобы начать.
Чтобы поэкспериментировать с Kubernetes локально, Minikube создаст виртуальный кластер на вашем персональном оборудовании. Если вы готовы опробовать облачный сервис, в Google Kubernetes Engine есть коллекция руководств , которые помогут вам начать работу.
Если вы новичок в мире контейнеров и веб-инфраструктуры, я предлагаю ознакомиться с методологией 12 Factor App . Здесь описываются некоторые из лучших практик, которые следует учитывать при разработке программного обеспечения для работы в такой среде, как Kubernetes.
Перевод оригинальной статьи Kubernetes 101: Pods, Nodes, Containers, and Clusters Контент оригинальной статьи принадлежит автору .
Узлы
Kubernetes запускает ваши приложения, помещая контейнеры в Поды для запуска на Узлах (Nodes). В зависимости от кластера, узел может быть виртуальной или физической машиной. Каждый узел содержит сервисы, необходимые для запуска Подов, управляемых плоскостью управления.
Обычно у вас есть несколько узлов в кластере; однако в среде обучения или среде с ограниченными ресурсами у вас может быть только один.
Управление
Существует два основных способа добавления Узлов в API сервер:
- Kubelet на узле саморегистрируется в плоскости управления
- Вы или другой пользователь вручную добавляете объект Узла
После того как вы создадите объект Узла или kubelet на узле самозарегистируется, плоскость управления проверяет, является ли новый объект Узла валидным (правильным). Например, если вы попробуете создать Узел при помощи следующего JSON манифеста:
"kind": "Node", "apiVersion": "v1", "metadata": "name": "10.240.79.157", "labels": "name": "my-first-k8s-node" > > > Kubernetes создает внутри себя объект Узла (представление). Kubernetes проверяет, что kubelet зарегистрировался на API сервере, который совпадает со значением поля metadata.name Узла. Если узел здоров (если все необходимые сервисы запущены), он имеет право на запуск Пода. В противном случае этот узел игнорируется для любой активности кластера до тех пор, пока он не станет здоровым.
Примечание:
Kubernetes сохраняет объект для невалидного Узла и продолжает проверять, становится ли он здоровым.
Вы или контроллер должны явно удалить объект Узла, чтобы остановить проверку доступности узла.
Имя объекта Узла должно быть валидным именем поддомена DNS.
Саморегистрация Узлов
Когда kubelet флаг —register-node имеет значение true (по умолчанию), то kubelet будет пытаться зарегистрировать себя на API сервере. Это наиболее предпочтительная модель, используемая большинством дистрибутивов.
Для саморегистрации kubelet запускается со следующими опциями:
- —kubeconfig — Путь к учетным данным для аутентификации на API сервере.
- —cloud-provider — Как общаться с облачным провайдером, чтобы прочитать метаданные о себе.
- —register-node — Автоматически зарегистрироваться на API сервере.
- —register-with-taints — Зарегистрировать узел с приведенным списком ограничений (taints) (разделенных запятыми =: ). Ничего не делает, если register-node — false.
- —node-ip — IP-адрес узла.
- —node-labels — Метки для добавления при регистрации узла в кластере (смотрите ограничения для меток, установленные плагином согласования (admission plugin) NodeRestriction).
- —node-status-update-frequency — Указывает, как часто kubelet отправляет статус узла мастеру.
Когда режим авторизации Узла и плагин согласования NodeRestriction включены, kubelet’ы имеют право только создавать/изменять свой собственный ресурс Узла.
Ручное администрирование узла
Вы можете создавать и изменять объекты узла используя kubectl.
Когда вы хотите создать объекты Узла вручную, установите kubelet флаг —register-node=false .
Вы можете изменять объекты Узла независимо от настройки —register-node . Например, вы можете установить метки на существующем Узле или пометить его не назначаемым.
Вы можете использовать метки на Узлах в сочетании с селекторами узла на Подах для управления планированием. Например, вы можете ограничить Под, иметь право на запуск только на группе доступных узлов.
Маркировка узла как не назначаемого предотвращает размещение планировщиком новых подов на этом Узле, но не влияет на существующие Поды на Узле. Это полезно в качестве подготовительного шага перед перезагрузкой узла или другим обслуживанием.
Чтобы отметить Узел не назначаемым, выполните:
kubectl cordon $NODENAME Примечание: Поды, являющиеся частью DaemonSet допускают запуск на не назначаемом Узле. DaemonSets обычно обеспечивает локальные сервисы узла, которые должны запускаться на Узле, даже если узел вытесняется для запуска приложений.
Статус Узла
Статус узла содержит следующие данные:
- Адреса (Addresses)
- Условия (Conditions)
- Емкость и Выделяемые ресурсы (Capacity and Allocatable)
- Информация (Info)
Вы можете использовать kubectl для просмотра статуса Узла и других деталей:
kubectl describe node Каждая секция из вывода команды описана ниже.
Адреса (Addresses)
Использование этих полей варьируется в зависимости от вашего облачного провайдера или конфигурации физических серверов (bare metal).
- HostName: Имя хоста, сообщаемое ядром узла. Может быть переопределено через kubelet —hostname-override параметр.
- ExternalIP: Обычно, IP адрес узла, который является внешне маршрутизируемым (доступен за пределами кластера).
- InternalIP: Обычно, IP адрес узла, который маршрутизируется только внутри кластера.
Условия (Conditions)
Поле conditions описывает статус всех Running узлов. Примеры условий включают в себя:
| Условие Узла | Описание |
|---|---|
| Ready | True если узел здоров и готов принять поды, False если узел нездоров и не принимает поды, и Unknown если контроллер узла не получал информацию от узла в течение последнего периода node-monitor-grace-period (по умолчанию 40 секунд) |
| DiskPressure | True если присутствует давление на размер диска — то есть, если емкость диска мала; иначе False |
| MemoryPressure | True если существует давление на память узла — то есть, если памяти на узле мало; иначе False |
| PIDPressure | True если существует давление на процессы — то есть, если на узле слишком много процессов; иначе False |
| NetworkUnavailable | True если сеть для узла настроена некорректно, иначе False |
Примечание: Если вы используете инструменты командной строки для вывода сведений об блокированном узле, то Условие включает SchedulingDisabled . SchedulingDisabled не является Условием в Kubernetes API; вместо этого блокированные узлы помечены как Не назначаемые в их спецификации.
Состояние узла представлено в виде JSON объекта. Например, следующая структура описывает здоровый узел:
"conditions": [ "type": "Ready", "status": "True", "reason": "KubeletReady", "message": "kubelet is posting ready status", "lastHeartbeatTime": "2019-06-05T18:38:35Z", "lastTransitionTime": "2019-06-05T11:41:27Z" > ] Если значение параметра Status для условия Ready остается Unknown или False дольше чем период pod-eviction-timeout (аргумент, переданный в kube-controller-manager), то все Поды на узле планируются к удалению контроллером узла. По умолчанию таймаут выселения пять минут. В некоторых случаях, когда узел недоступен, API сервер не может связаться с kubelet на узле. Решение об удалении подов не может быть передано в kubelet до тех пор, пока связь с API сервером не будет восстановлена. В то же время поды, которые запланированы к удалению, могут продолжать работать на отделенном узле.
Контроллер узла не будет принудительно удалять поды до тех пор, пока не будет подтверждено, что они перестали работать в кластере. Вы можете видеть, что поды, которые могут работать на недоступном узле, находятся в состоянии Terminating или Unknown . В тех случаях, когда Kubernetes не может сделать вывод из основной инфраструктуры о том, что узел окончательно покинул кластер, администратору кластера может потребоваться удалить объект узла вручную. Удаление объекта узла из Kubernetes приводит к удалению всех объектов Подов, запущенных на узле, с API сервера и освобождает их имена.
Контроллер жизненного цикла узла автоматически создает ограничения (taints), которые представляют собой условия. Планировщик учитывает ограничения Узла при назначении Пода на Узел. Поды так же могут иметь допуски (tolerations), что позволяет им сопротивляться ограничениям Узла.
Смотрите раздел Ограничить Узлы по Условию для дополнительной информации.
Емкость и Выделяемые ресурсы (Capacity and Allocatable)
Описывает ресурсы, доступные на узле: CPU, память и максимальное количество подов, которые могут быть запланированы на узле.
Поля в блоке capacity указывают общее количество ресурсов, которые есть на Узле. Блок allocatable указывает количество ресурсов на Узле, которые доступны для использования обычными Подами.
Вы можете прочитать больше о емкости и выделяемых ресурсах, изучая, как зарезервировать вычислительные ресурсы на Узле.
Информация (Info)
Описывает общую информацию об узле, такую как версия ядра, версия Kubernetes (версии kubelet и kube-proxy), версия Docker (если используется) и название ОС. Эта информация собирается Kubelet’ом на узле.
Контроллер узла
Контроллер узла является компонентом плоскости управления Kubernetes, который управляет различными аспектами узлов.
Контроллер узла играет различные роли в жизни узла. Первая — назначение CIDR-блока узлу при его регистрации (если включено назначение CIDR).
Вторая — поддержание в актуальном состоянии внутреннего списка узлов контроллера узла согласно списку доступных машин облачного провайдера. При работе в облачной среде всякий раз, когда узел неисправен, контроллер узла запрашивает облачного провайдера, доступна ли виртуальная машина для этого узла. Если нет, то контроллер узла удаляет узел из своего списка узлов.
Третья — это мониторинг работоспособности узлов. Контроллер узла отвечает за обновление условия NodeReady для NodeStatus на ConditionUnknown, когда узел становится недоступным (т.е. контроллер узла по какой-то причине перестает получать сердцебиения (heartbeats) от узла, например, из-за того, что узел упал), и затем позже выселяет все поды с узла (используя мягкое (graceful) завершение) если узел продолжает быть недоступным. (По умолчанию таймауты составляют 40 секунд, чтобы начать сообщать ConditionUnknown , и 5 минут после, чтобы начать выселять поды.)
Контроллер узла проверяет состояние каждого узла каждые —node-monitor-period секунд.
Сердцебиения
Сердцебиения, посылаемые узлами Kubernetes, помогают определить доступность узла.
Существует две формы сердцебиений: обновление NodeStatus и Lease объект. Каждый узел имеет связанный с ним Lease объект в kube-node-lease namespace. Lease — это легковесный ресурс, который улучшает производительность сердцебиений узла при масштабировании кластера.
Kubelet отвечает за создание и обновление NodeStatus и Lease объекта.
- Kubelet обновляет NodeStatus либо когда происходит изменение статуса, либо если в течение настроенного интервала обновления не было. По умолчанию интервал для обновлений NodeStatus составляет 5 минут (намного больше, чем 40-секундный стандартный таймаут для недоступных узлов).
- Kubelet создает и затем обновляет свой Lease объект каждый 10 секунд (интервал обновления по умолчанию). Lease обновления происходят независимо от NodeStatus обновлений. Если обновление Lease завершается неудачно, kubelet повторяет попытку с экспоненциальным откатом, начинающимся с 200 миллисекунд и ограниченным 7 секундами.
Надежность
В большинстве случаев контроллер узла ограничивает скорость выселения до —node-eviction-rate (по умолчанию 0,1) в секунду, что означает, что он не выселяет поды с узлов быстрее чем с одного узла в 10 секунд.
Поведение выселения узла изменяется, когда узел в текущей зоне доступности становится нездоровым. Контроллер узла проверяет, какой процент узлов в зоне нездоров (NodeReady условие в значении ConditionUnknown или ConditiononFalse) в одно и то же время. Если доля нездоровых узлов не меньше —unhealthy-zone-threshold (по умолчанию 0.55), то скорость выселения уменьшается: если кластер небольшой (т.е. количество узлов меньше или равно —large-cluster-size-threshold — по умолчанию, 50), то выселения прекращаются, в противном случае скорость выселения снижается до —secondary-node-eviction-rate (по умолчанию, 0.01) в секунду.
Причина, по которой эти политики реализуются для каждой зоны доступности, заключается в том, что одна зона доступности может стать отделенной от мастера, в то время как другие остаются подключенными. Если ваш кластер не охватывает несколько зон доступности облачного провайдера, то существует только одна зона доступности (весь кластер).
Основная причина разнесения ваших узлов по зонам доступности заключается в том, что приложения могут быть перенесены в здоровые зоны, когда одна из зон полностью становится недоступной. Поэтому, если все узлы в зоне нездоровы, то контроллер узла выселяет поды с нормальной скоростью —node-eviction-rate . Крайний случай — когда все зоны полностью нездоровы (т.е. в кластере нет здоровых узлов). В таком случае контроллер узла предполагает, что существует некоторая проблема с подключением к мастеру, и останавливает все выселения, пока какое-нибудь подключение не будет восстановлено.
Контроллер узла также отвечает за выселение подов, запущенных на узлах с NoExecute ограничениями, за исключением тех подов, которые сопротивляются этим ограничениям. Контроллер узла так же добавляет ограничения соответствующие проблемам узла, таким как узел недоступен или не готов. Это означает, что планировщик не будет размещать поды на нездоровых узлах.
Внимание: kubectl cordon помечает узел как ‘не назначаемый’, что имеет побочный эффект от контроллера сервисов, удаляющего узел из любых списков целей LoadBalancer узла, на которые он ранее имел право, эффективно убирая входящий трафик балансировщика нагрузки с блокированного узла(ов).
Емкость узла
Объекты узла отслеживают информацию о емкости ресурсов узла (например, объем доступной памяти и количество CPU). Узлы, которые самостоятельно зарегистрировались, сообщают о своей емкости во время регистрации. Если вы вручную добавляете узел, то вам нужно задать информацию о емкости узла при его добавлении.
Планировщик Kubernetes гарантирует, что для всех Подов на Узле достаточно ресурсов. Планировщик проверяет, что сумма requests от контейнеров на узле не превышает емкость узла. Эта сумма requests включает все контейнеры, управляемые kubelet, но исключает любые контейнеры, запущенные непосредственно средой выполнения контейнера, а также исключает любые процессы, запущенные вне контроля kubelet.
Примечание: Если вы явно хотите зарезервировать ресурсы для процессов, не связанных с Подами, смотрите раздел зарезервировать ресурсы для системных демонов.
Топология узла
СТАТУС ФИЧИ: Kubernetes v1.16 [alpha]
Если вы включили TopologyManager feature gate, то kubelet может использовать подсказки топологии при принятии решений о выделении ресурсов. Смотрите Контроль Политик Управления Топологией на Узле для дополнительной информации.
Что дальше
- Подробнее прокомпоненты из которых состоит узел.
- Подробнее про Определение API для Узла.
- Подробнее про Узлы of the architecture design document.
- Подробнее про ограничения и допуски.
- Подробнее про авто масштабирование кластера.
Обратная связь
Эта страница была полезна?
Спасибо за обратную связь! Если у вас есть конкретный вопрос об использовании Kubernetes, спросите на Stack Overflow. Создайте issue в репозитории GitHub, если вы хотите сообщить о проблеме или предложить улучшение.
Основы Kubernetes
В этой публикации я хотел рассказать об интересной, но незаслуженно мало описанной на Хабре, системе управления контейнерами Kubernetes.

Что такое Kubernetes?
Kubernetes является проектом с открытым исходным кодом, предназначенным для управления кластером контейнеров Linux как единой системой. Kubernetes управляет и запускает контейнеры Docker на большом количестве хостов, а так же обеспечивает совместное размещение и репликацию большого количества контейнеров. Проект был начат Google и теперь поддерживается многими компаниями, среди которых Microsoft, RedHat, IBM и Docker.
Компания Google пользуется контейнерной технологией уже более десяти лет. Она начинала с запуска более 2 млрд контейнеров в течение одной недели. С помощью проекта Kubernetes компания делится своим опытом создания открытой платформы, предназначенной для масштабируемого запуска контейнеров.
Проект преследует две цели. Если вы пользуетесь контейнерами Docker, возникает следующий вопрос о том, как масштабировать и запускать контейнеры сразу на большом количестве хостов Docker, а также как выполнять их балансировку. В проекте предлагается высокоуровневый API, определяющее логическое группирование контейнеров, позволяющее определять пулы контейнеров, балансировать нагрузку, а также задавать их размещение.
Концепции Kubernetes
Nodes (node.md): Нода это машина в кластере Kubernetes.
Pods (pods.md): Pod это группа контейнеров с общими разделами, запускаемых как единое целое.
Replication Controllers (replication-controller.md): replication controller гарантирует, что определенное количество «реплик» pod’ы будут запущены в любой момент времени.
Services (services.md): Сервис в Kubernetes это абстракция которая определяет логический объединённый набор pod и политику доступа к ним.
Volumes (volumes.md): Volume(раздел) это директория, возможно, с данными в ней, которая доступна в контейнере.
Labels (labels.md): Label’ы это пары ключ/значение которые прикрепляются к объектам, например pod’ам. Label’ы могут быть использованы для создания и выбора наборов объектов.
Kubectl Command Line Interface (kubectl.md): kubectl интерфейс командной строки для управления Kubernetes.
Архитектура Kubernetes
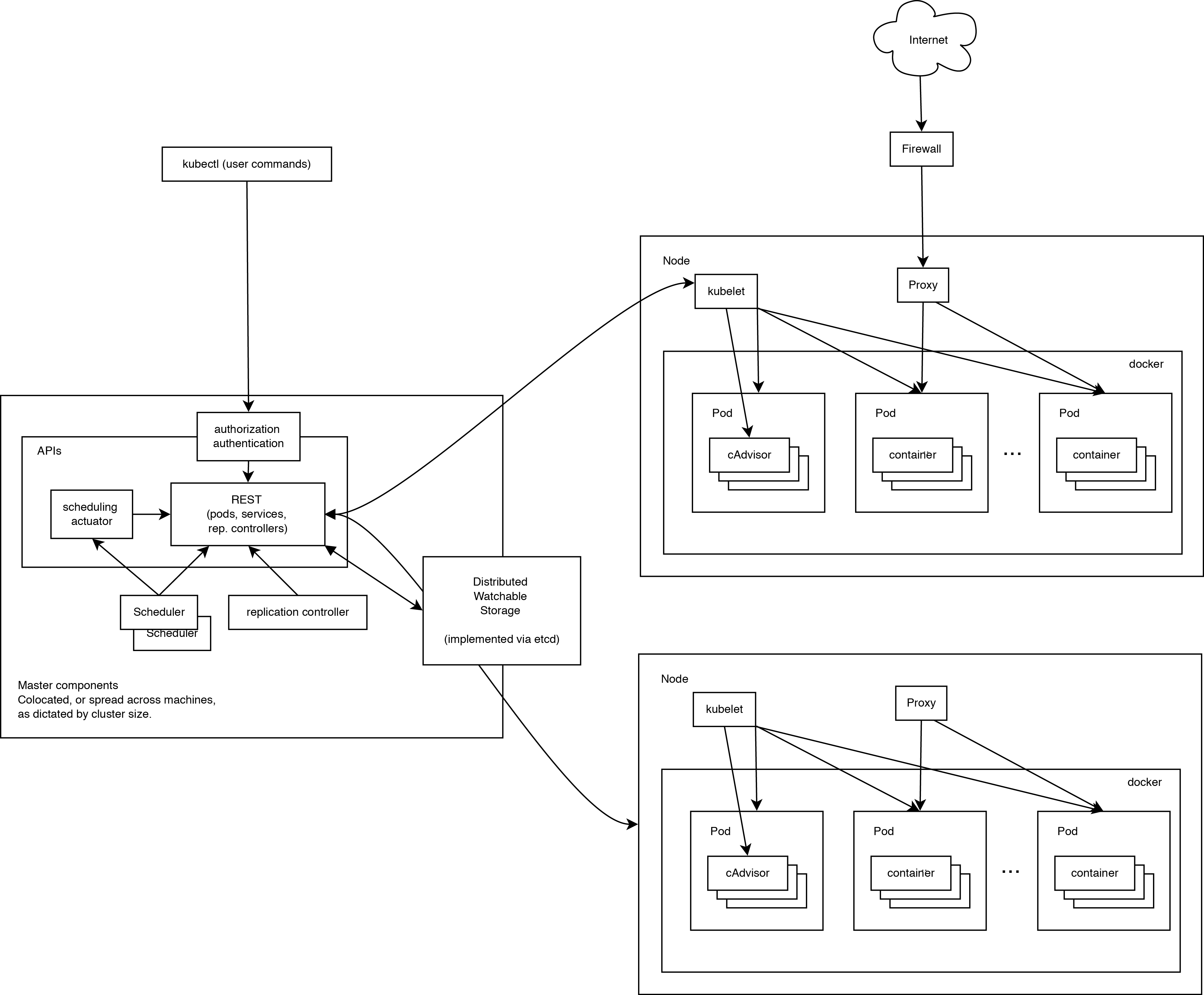
Работающий кластер Kubernetes включает в себя агента, запущенного на нодах (kubelet) и компоненты мастера (APIs, scheduler, etc), поверх решения с распределённым хранилищем. Приведённая схема показывает желаемое, в конечном итоге, состояние, хотя все ещё ведётся работа над некоторыми вещами, например: как сделать так, чтобы kubelet (все компоненты, на самом деле) самостоятельно запускался в контейнере, что сделает планировщик на 100% подключаемым.
Нода Kubernetes
При взгляде на архитектуру системы мы можем разбить его на сервисы, которые работают на каждой ноде и сервисы уровня управления кластера. На каждой ноде Kubernetes запускаются сервисы, необходимые для управления нодой со стороны мастера и для запуска приложений. Конечно, на каждой ноде запускается Docker. Docker обеспечивает загрузку образов и запуск контейнеров.
Kubelet
Kubelet управляет pod’ами их контейнерами, образами, разделами, etc.
Kube-Proxy
Также на каждой ноде запускается простой proxy-балансировщик. Этот сервис запускается на каждой ноде и настраивается в Kubernetes API. Kube-Proxy может выполнять простейшее перенаправление потоков TCP и UDP (round robin) между набором бэкендов.
Компоненты управления Kubernetes
Система управления Kubernetes разделена на несколько компонентов. В данный момент все они запускаются на мастер-ноде, но в скором времени это будет изменено для возможности создания отказоустойчивого кластера. Эти компоненты работают вместе, чтобы обеспечить единое представление кластера.
etcd
Состояние мастера хранится в экземпляре etcd. Это обеспечивает надёжное хранение конфигурационных данных и своевременное оповещение прочих компонентов об изменении состояния.
Kubernetes API Server
Kubernetes API обеспечивает работу api-сервера. Он предназначен для того, чтобы быть CRUD сервером со встроенной бизнес-логикой, реализованной в отдельных компонентах или в плагинах. Он, в основном, обрабатывает REST операции, проверяя их и обновляя соответствующие объекты в etcd (и событийно в других хранилищах).
Scheduler
Scheduler привязывает незапущенные pod’ы к нодам через вызов /binding API. Scheduler подключаем; планируется поддержка множественных scheduler’ов и пользовательских scheduler’ов.
Kubernetes Controller Manager Server
Все остальные функции уровня кластера представлены в Controller Manager. Например, ноды обнаруживаются, управляются и контролируются средствами node controller. Эта сущность в итоге может быть разделена на отдельные компоненты, чтобы сделать их независимо подключаемыми.
ReplicationController — это механизм, основывающийся на pod API. В конечном счете планируется перевести её на общий механизм plug-in, когда он будет реализован.
Пример настройки кластера
В качестве платформы для примера настройки была выбрана Ubuntu-server 14.10 как наиболее простая для примера и, в то же время, позволяющая продемонстрировать основные параметры настройки кластера.
Для создания тестового кластера будут использованы три машины для создания нод и отдельная машина для проведения удалённой установки. Можно не выделять отдельную машину и производить установку с одной из нод.
- Conf
- Node1: 192.168.0.10 — master, minion
- Node2: 192.168.0.11 — minion
- Node3: 192.168.0.12 — minion
Подготовка нод
Требования для запуска:
- На всех нодах установлен docker версии 1.2+ и bridge-utils
- Все машины связаны друг с другом, необходимости в доступе к интернету нет (в этом случае необходимо использовать локальный docker registry)
- На все ноды можно войти без ввода логина/пароля, с использованием ssh-ключей
Установка ПО на ноды
Установку Docker можно произвести по статье в официальных источниках:
node% sudo apt-get update $ sudo apt-get install wget node% wget -qO- https://get.docker.com/ | sh Дополнительная настройка Docker после установки не нужна, т.к. будет произведена скриптом установки Kubernetes.
Установка bridge-utils:
node% sudo apt-get install bridge-utils Добавление ssh-ключей
Выполняем на машине, с которой будет запущен скрипт установки.
Если ключи ещё не созданы, создаём их:
conf% ssh-keygen Копируем ключи на удалённые машины, предварительно убедившись в наличии на них необходимого пользователя, в нашем случае core.
conf% ssh-copy-id core@192.168.0.10 conf% ssh-copy-id core@192.168.0.11 conf% ssh-copy-id core@192.168.0.12 Установка Kubernetes
Далее мы займёмся установкой непосредственно Kubernetes. Для этого в первую очередь скачаем и распакуем последний доступный релиз с GitHub:
conf% wget https://github.com/GoogleCloudPlatform/kubernetes/releases/download/v0.17.0/kubernetes.tar.gz conf% tar xzf ./kubernetes.tar.gz conf% cd ./kubernetes Настройка
Настройка Kubernetes через стандартные скрипты примеров полностью производится перед установкой производится через конфигурационные файлы. При установке мы будем использовать скрипты папке ./cluster/ubuntu/.
В первую очередь изменим скрипт ./cluster/ubuntu/build.sh который скачивает и подготавливает необходимые для установки бинарники Kubernetes, etcd и flannel:
conf% vim ./cluster/ubuntu/build.sh Для того, чтобы использовать последний, на момент написания статьи, релиз 0.17.0 необходимо заменить:
# k8s echo "Download kubernetes release . " K8S_VERSION="v0.15.0" # k8s echo "Download kubernetes release . " K8S_VERSION="v0.17.0" conf% cd ./cluster/ubuntu/ conf% ./build.sh #Данный скрипт важно запускать именно из той папки, где он лежит. Далее указываем параметры будущего кластера, для чего редактируем файл ./config-default.sh:
## Contains configuration values for the Ubuntu cluster # В данном пункте необходимо указать все ноды будущего кластера, MASTER-нода указывается первой # Ноды указываются в формате разделитель - пробел # В качестве пользователя указывается тот пользователь для которого по нодам разложены ssh-ключи export nodes="core@192.168.0.10 core@192.168.0.10 core@192.168.0.10" # Определяем роли нод : a(master) или i(minion) или ai(master и minion), указывается в том же порядке, что и ноды в списке выше. export roles=("ai" "i" "i") # Определяем количество миньонов export NUM_MINIONS=$ # Определяем IP-подсеть из которой, в последствии будут выделяться адреса для сервисов. # Выделять необходимо серую подсеть, которая не будет пересекаться с имеющимися, т.к. эти адреса будут существовать только в пределах каждой ноды. #Перенаправление на IP-адреса сервисов производится локальным iptables каждой ноды. export PORTAL_NET=192.168.3.0/24 #Определяем подсеть из которой будут выделяться подсети для создания внутренней сети flannel. #flannel по умолчанию выделяет подсеть с маской 24 на каждую ноду, из этих подсетей будут выделяться адреса для Docker-контейнеров. #Подсеть не должна пересекаться с PORTAL_NET export FLANNEL_NET=172.16.0.0/16 # Admission Controllers определяет политику доступа к объектам кластера. ADMISSION_CONTROL=NamespaceLifecycle,NamespaceAutoProvision,LimitRanger,ResourceQuota # Дополнительные параметры запуска Docker. Могут быть полезны для дополнительных настроек # например установка --insecure-registry для локальных репозиториев. DOCKER_OPTS="" На этом настройка заканчивается и можно переходить к установке.
Установка
Первым делом необходимо сообщить системе про наш ssh-agent и используемый ssh-ключ для этого выполняем:
eval `ssh-agent -s` ssh-add /путь/до/ключа Далее переходим непосредственно к установке. Для этого используется скрипт ./kubernetes/cluster/kube-up.sh которому необходимо указать, что мы используем ubuntu.
conf% cd ../ conf% KUBERNETES_PROVIDER=ubuntu ./kube-up.sh В процессе установки скрипт потребует пароль sudo для каждой ноды. По окончанию установки проверит состояние кластера и выведет список нод и адреса Kubernetes api.
Пример вывода скрипта
Starting cluster using provider: ubuntu . calling verify-prereqs . calling kube-up Deploying master and minion on machine 192.168.0.10 [sudo] password to copy files and start node: etcd start/running, process 16384 Connection to 192.168.0.10 closed. Deploying minion on machine 192.168.0.11 [sudo] password to copy files and start minion: etcd start/running, process 12325 Connection to 192.168.0.11 closed. Deploying minion on machine 192.168.0.12 [sudo] password to copy files and start minion: etcd start/running, process 10217 Connection to 192.168.0.12 closed. Validating master Validating core@192.168.0.10 Validating core@192.168.0.11 Validating core@192.168.0.12 Kubernetes cluster is running. The master is running at: http://192.168.0.10 . calling validate-cluster Found 3 nodes. 1 NAME LABELS STATUS 2 192.168.0.10 Ready 3 192.168.0.11 Ready 4 192.168.0.12 Ready Validate output: NAME STATUS MESSAGE ERROR etcd-0 Healthy <"action":"get","node":<"dir":true,"nodes":[<"key":"/coreos.com","dir":true,"modifiedIndex":11,"createdIndex":11>,],"modifiedIndex":5,"createdIndex":5>> nil controller-manager Healthy ok nil scheduler Healthy ok nil Cluster validation succeeded Done, listing cluster services: Kubernetes master is running at http://192.168.0.10:8080 Посмотрим, какие ноды и сервисы присутствуют в новом кластере:
conf% cp ../kubernetes/platforms/linux/amd64/kubectl /opt/bin/ conf% /opt/bin/kubectl get services,minions -s "http://192.168.0.10:8080" NAME LABELS SELECTOR IP PORT(S) kubernetes component=apiserver,provider=kubernetes 192.168.3.2 443/TCP kubernetes-ro component=apiserver,provider=kubernetes 192.168.3.1 80/TCP NAME LABELS STATUS 192.168.0.10 Ready 192.168.0.11 Ready 192.168.0.12 Ready Видим список из установленных нод в состоянии Ready и два предустановленных сервиса kubernetes и kubernetes-ro — это прокси для непосредственного доступа к Kubernetes API. Как и к любому сервису Kubernetes к kubernetes и kubernetes-ro можно обратиться непосредственно по IP адресу с любой из нод.
Запуск тестового сервиса
Для запуска сервиса необходимо подготовить docker контейнер, на основе которого будет создан сервис. Дабы не усложнять, в примере будет использован общедоступный контейнер nginx. Обязательными составляющими сервиса являются Replication Controller, обеспечивающий запущенность необходимого набора контейнеров (точнее pod) и service, который определяет, на каких IP адресе и портах будет слушать сервис и правила распределения запросов между pod’ами.
Любой сервис можно запустить 2-я способами: вручную и с помощью конфиг-файла. Рассмотрим оба.
Запуск сервиса вручную
Начнём с создания Replication Controller’а:
conf% /opt/bin/kubectl run-container nginx --port=80 --port=443 --image=nginx --replicas=6 -s "http://192.168.0.10:8080" - nginx — имя будущего rc
- —port — порты на которых будут слушать контейнеры rc
- —image — образ из которого будут запущены контейнеры
- —replicas=6 — количество реплик
/opt/bin/kubectl get pods,rc -s "http://192.168.0.10:8080" POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE nginx-3gii4 172.16.58.4 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds nginx nginx Running 9 seconds nginx-3xudc 172.16.62.6 192.168.0.10/192.168.0.10 run-container=nginx Running 9 seconds nginx nginx Running 8 seconds nginx-igpon 172.16.58.6 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds nginx nginx Running 8 seconds nginx-km78j 172.16.58.5 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds nginx nginx Running 8 seconds nginx-sjb39 172.16.83.4 192.168.0.12/192.168.0.12 run-container=nginx Running 9 seconds nginx nginx Running 8 seconds nginx-zk1wv 172.16.62.7 192.168.0.10/192.168.0.10 run-container=nginx Running 9 seconds nginx nginx Running 8 seconds CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS nginx nginx nginx run-container=nginx 6 - Часть pod находится в состоянии pending: это значит, что они ещё не запустились, необходимо немного подождать
- У pod не определён HOST: это значит, что scheduler ещё не назначил ноду на которой будет запущен pod
Далее создаём service который будет использовать наш Replication Controller как бекенд.
Для http:
conf% /opt/bin/kubectl expose rc nginx --port=80 --target-port=80 --service-name=nginx-http -s "http://192.168.0.10:8080" conf% /opt/bin/kubectl expose rc nginx --port=443 --target-port=443 --service-name=nginx-https -s "http://192.168.0.10:8080" - rc nginx — тип и имя используемого ресурса (rc = Replication Controller)
- —port — порт на котором будет «слушать» сервис
- —target-port — порт контейнера на который будет производиться трансляция запросов
- —service-name — будущее имя сервиса
/opt/bin/kubectl get rc,services -s "http://192.168.0.10:8080" CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS nginx nginx nginx run-container=nginx 6 NAME LABELS SELECTOR IP PORT(S) kubernetes component=apiserver,provider=kubernetes 192.168.3.2 443/TCP kubernetes-ro component=apiserver,provider=kubernetes 192.168.3.1 80/TCP nginx-http run-container=nginx 192.168.3.66 80/TCP nginx-https run-container=nginx 192.168.3.172 443/TCP Для проверки запущенности можно зайти на любую из нод и выполнить в консоли:
node% curl http://192.168.3.66 В выводе curl увидим стандартную приветственную страницу nginx. Готово, сервис запущен и доступен.
Запуск сервиса с помощью конфигов
Для этого способа запуска необходимо создать конфиги для Replication Controller’а и service’а. Kubernetes принимает конфиги в форматах yaml и json. Мне ближе yaml поэтому будем использовать его.
Предварительно очистим наш кластер от предыдущего эксперимента:
conf% /opt/bin/kubectl delete services nginx-http nginx-https -s "http://192.168.0.10:8080" conf% /opt/bin/kubectl stop rc nginx -s "http://192.168.0.10:8080" Теперь приступим к написанию конфигов. nginx_rc.yaml
содержимое
apiVersion: v1beta3 kind: ReplicationController # Указываем имя ReplicationController metadata: name: nginx-controller spec: # Устанавливаем количество реплик replicas: 6 selector: name: nginx template: metadata: labels: name: nginx spec: containers: #Описываем контейнер - name: nginx image: nginx #Пробрасываем порты ports: - containerPort: 80 - containerPort: 443 livenessProbe: # включаем проверку работоспособности enabled: true type: http # Время ожидания после запуска pod'ы до момента начала проверок initialDelaySeconds: 30 TimeoutSeconds: 5 # http проверка httpGet: path: / port: 80 portals: - destination: nginx conf% /opt/bin/kubectl create -f ./nginx_rc.yaml -s "http://192.168.0.10:8080" conf% /opt/bin/kubectl get pods,rc -s "http://192.168.0.10:8080" POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE nginx-controller-0wklg 172.16.58.7 192.168.0.11/192.168.0.11 name=nginx Running About a minute nginx nginx Running About a minute nginx-controller-2jynt 172.16.58.8 192.168.0.11/192.168.0.11 name=nginx Running About a minute nginx nginx Running About a minute nginx-controller-8ra6j 172.16.62.8 192.168.0.10/192.168.0.10 name=nginx Running About a minute nginx nginx Running About a minute nginx-controller-avmu8 172.16.58.9 192.168.0.11/192.168.0.11 name=nginx Running About a minute nginx nginx Running About a minute nginx-controller-ddr4y 172.16.83.7 192.168.0.12/192.168.0.12 name=nginx Running About a minute nginx nginx Running About a minute nginx-controller-qb2wb 172.16.83.5 192.168.0.12/192.168.0.12 name=nginx Running About a minute nginx nginx Running About a minute CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS nginx-controller nginx nginx name=nginx 6 Был создан Replication Controller с именем nginx и количеством реплик равным 6. Реплики в произвольном порядке запущены на нодах, местоположения каждой pod’ы указано в столбце HOST.
nginx_service.yaml
Содержимое
apiVersion: v1beta3 kind: Service metadata: name: nginx spec: publicIPs: - 12.0.0.5 # IP который будет присвоен сервису помимо автоматически назначенного. ports: - name: http port: 80 #порт на котором будет слушать сервис targetPort: 80 порт контейнера на который будет производиться трансляция запросов protocol: TCP - name: https port: 443 targetPort: 443 protocol: TCP selector: name: nginx # поле должно совпадать с аналогичным в конфиге ReplicationController Можно заметить, что при использовании конфига за одним сервисом могут быть закреплены несколько портов.
Применяем конфиг:
conf% /opt/bin/kubectl create -f ./nginx_service.yaml -s "http://192.168.0.10:8080" /opt/bin/kubectl get rc,services -s "http://192.168.0.10:8080" CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS nginx-controller nginx nginx name=nginx 6 NAME LABELS SELECTOR IP PORT(S) kubernetes component=apiserver,provider=kubernetes 192.168.3.2 443/TCP kubernetes-ro component=apiserver,provider=kubernetes 192.168.3.1 80/TCP nginx name=nginx 192.168.3.214 80/TCP 12.0.0.5 443/TCP Для проверки запущенности можно зайти на любую из нод и выполнить в консоли:
node% curl http://192.168.3.214 node% curl http://12.0.0.5 В выводе curl увидим стандартную приветственную страницу nginx.
Заметки на полях
В качестве заключения хочу описать пару важных моментов, о которые уже пришлось запнуться при проектировании системы. Связаны они были с работой kube-proxy, того самого модуля, который позволяет превратить разрозненный набор элементов в сервис.
PORTAL_NET. Сущность сама по себе интересная, предлагаю ознакомиться с тем, как же это реализовано.
Недолгие раскопки привели меня к осознанию простой, но эффективной модели, заглянем в вывод iptables-save:
-A PREROUTING -j KUBE-PORTALS-CONTAINER -A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER -A OUTPUT -j KUBE-PORTALS-HOST -A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER -A POSTROUTING -s 10.0.42.0/24 ! -o docker0 -j MASQUERADE -A KUBE-PORTALS-CONTAINER -d 10.0.0.2/32 -p tcp -m comment --comment "default/kubernetes:" -m tcp --dport 443 -j REDIRECT --to-ports 46041 -A KUBE-PORTALS-CONTAINER -d 10.0.0.1/32 -p tcp -m comment --comment "default/kubernetes-ro:" -m tcp --dport 80 -j REDIRECT --to-ports 58340 -A KUBE-PORTALS-HOST -d 10.0.0.2/32 -p tcp -m comment --comment "default/kubernetes:" -m tcp --dport 443 -j DNAT --to-destination 172.16.67.69:46041 -A KUBE-PORTALS-HOST -d 10.0.0.1/32 -p tcp -m comment --comment "default/kubernetes-ro:" -m tcp --dport 80 -j DNAT --to-destination 172.16.67.69:58340 - gcloud — платная разработка от Google
- bgp — с помощью анонсирования подсетей
- IPVS
- и прочие варианты, которых множество
На этом всё, спасибо за внимание
К сожалению, всю информацию, которую хочется передать, не получается уместить в одну статью.
Использование материалы:
- Архитектура Kubernetes
- Kubernetes user guide
- Kubernetes ubuntu cluster
- Scaling Docker with Kubernetes
- Kubernetes services