Классификация, регрессия и другие алгоритмы Data Mining с использованием R
Понятие “вид элемента \(a_k\) ” легко может быть обобщено на ту или иную его категорию или вещественное значение, т.е. концепция ассоциативного анализа может быть применена для комбинаций любых переменных. Например, при прогнозировании погоды одно из ассоциативных правил может выглядеть так: ‘направление ветра’ = NNW -> ‘завтра будет дождь’ = TRUE
Выделяют три вида правил:
- полезные правила, содержащие действительную информацию, которая ранее была неизвестна, но имеет логическое объяснение;
- тривиальные правила, содержащие действительную и легко объяснимую информацию, отражающую известные законы в исследуемой области, и поэтому не приносящие какой-либо пользы;
- непонятные правила, содержащие информацию, которая не может быть объяснена (такие правила или получают на основе аномальных исходных данных, или они содержат глубоко скрытые закономерности, и поэтому для интерпретации непонятных правил нужен дополнительный анализ).
Поиск ассоциативных правил обычно выполняют в два этапа:
- в пуле имеющихся признаков \(\mathbf\) находят наиболее часто встречающиеся комбинации элементов \(\mathbf\) ;
- из этих найденных наиболее часто встречающихся наборов формируют ассоциативные правила.
Для оценки полезности и продуктивности перебираемых правил используются различные частотные критерии, анализирующие встречаемость кандидата в массиве экспериментальных данных. Важнейшими из них являются поддержка (support) и достоверность (confidence). Правило \(\mathcal \rightarrow \mathcal\) имеет поддержку \(s\) , если оно справедливо для \(s\%\) взятых в анализ случаев:
Достоверность правила показывает, какова вероятность того, что из наличия в рассматриваемом случае условной части правила следует наличие заключительной его части (т.е. из \(\mathcal\) следует \(\mathcal\) ):
Алгоритмы поиска ассоциативных правил отбирают тех кандидатов, у которых поддержка и достоверность выше некоторых наперед заданных порогов: minsupport и minconfidence . Если поддержка имеет большое значение, то алгоритмы будут находить правила, хорошо известные аналитику или настолько очевидные, что нет никакого смысла проводить такой анализ. Большинство интересных правил находят именно при низком значении порога поддержки. С другой стороны, низкое значение minsupport ведет к генерации огромного количества вариантов, что требует существенных вычислительных ресурсов или ведет к генерации статистически необоснованных правил.
В пакете arules для R используются и другие показатели — подъемная сила, или лифт (lift), которая показывает, насколько повышается вероятность нахождения \(\mathcal\) в анализируемом случае, если в нем уже имеется \(\mathcal\) :
и усиление (leverage), которое отражает, насколько интересной может быть более высокая частота \(\mathcal\) и \(\mathcal\) в сочетании с более низким подъемом:
Первый алгоритм поиска ассоциативных правил был разработан в 1993 г. сотрудниками исследовательского центра IBM, что сразу возбудило интерес к этому направлению. Каждый год появлялось несколько новых алгоритмов (DHP, Partition, DIC и др.), из которых наиболее известным остался алгоритм “Apriori” (Agrawal, Srikant, 1994).
Пакет arules позволяет находить часто встречающиеся сочетания элементов в данных (frequent itemsets) и отбирать ассоциативные правила, обеспечивая интерфейс к модулям на языке C, которые реализуют алгоритмы “Apriori” и “Eclat”. Так как обычно обрабатываются большие множества наборов и правил, то для уменьшения объёмов требуемой памяти пакет содержит развитый инструментарий преобразования разреженных входных матриц в компактные наборы транзакций (Hahsler et al., 2016; Огнева, 2012).
Для реализации работы с алгоритмами выделения ассоциаций в arules реализованы специальные типы данных, относящиеся к объектам трех классов: входной массив транзакций (transactions) и на выходе — часто встречающиеся фрагменты данных (itemsets) и правила (rules).
Объекты класса transactions представляют собой специально организованные бинарные матрицы со строками-наборами и столбцами-признаками, содержащие значения элемента 1, если соответствующий признак есть в транзакции, и 0, если он отсутствует. В зависимости от типа данных и способа их загрузки, эти объекты могут иметь разные способы организации и состав дополнительных слотов. В частности, подкласс itemMatrix является одновременно средством представления разреженных матриц с использованием функционала пакета Matrix . Другим способом формирования экземпляров класса transactions является загрузка данных из файла функцией read.transactions() .
Для выделения ассоциативных правил вновь обратимся к нашему примеру по классификации лиц избирателей (см. рис. 5.1). Метод «basket» функции read.transactions() предполагает, что каждая строка в файле представляет собой одну транзакцию, в которой признаки (т.е. их метки) разделены символами sep (по умолчанию — запятая). Переформируем исходную таблицу данных в файл необходимого формата:
DFace read.delim(file = "data/Faces.txt", header = TRUE, row.names = 1) Class DFace$Class DFaceN DFace[, -17] colnames(DFaceN) c("голова_круглая", "уши_оттопырен", "нос_круглый", "глаза_круглые", "лоб_морщины", "носогубн_складка", "губы_толстые", "волосы", "усы", "борода", "очки", "родинка_щеке", "бабочка", "брови_подняты", "серьга", "курит_трубка") Class[Class == 1] "Патриот" Class[Class == 2] "Демократ" items_list sapply(1:nrow(DFaceN), function(i) paste(c(Class[i], colnames(DFaceN[i, DFaceN[i, ] == 1])), collapse = ",", sep = "\n")) head(items_list)## [1] "Патриот,уши_оттопырен,лоб_морщины,носогубн_складка,усы,борода,очки,бабочка,брови_подняты,курит_трубка" ## [2] "Патриот,голова_круглая,нос_круглый,глаза_круглые,губы_толстые,волосы,борода,очки,родинка_щеке,серьга" ## [3] "Патриот,глаза_круглые,лоб_морщины,носогубн_складка,волосы,усы,очки,родинка_щеке,бабочка,курит_трубка" ## [4] "Патриот,уши_оттопырен,нос_круглый,носогубн_складка,губы_толстые,борода,очки,брови_подняты,серьга,курит_трубка" ## [5] "Патриот,голова_круглая,уши_оттопырен,глаза_круглые,носогубн_складка,волосы,борода,родинка_щеке,брови_подняты,серьга" ## [6] "Патриот,нос_круглый,лоб_морщины,носогубн_складка,губы_толстые,усы,очки,бабочка,серьга,курит_трубка"write(items_list, file = "data/face_basket.txt")Загрузим данные из файла и создадим объект itemMatrix . Информацию о сформированном массиве транзакций можно получить, выполнив команды inspect() и summary() .
library(arules) trans read.transactions("data/face_basket.txt", format = "basket", sep = ",")inspect(trans) # Выводимые данные не показаныsummary(trans)## transactions as itemMatrix in sparse format with ## 16 rows (elements/itemsets/transactions) and ## 18 columns (items) and a density of 0.5555556 ## ## most frequent items: ## бабочка брови_подняты глаза_круглые борода губы_толстые ## 10 10 10 10 10 ## (Other) ## 110 ## ## element (itemset/transaction) length distribution: ## sizes ## 10 ## 16 ## ## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 10 10 10 10 10 10 ## ## includes extended item information - examples: ## labels ## 1 бабочка ## 2 Демократ ## 3 брови_поднятыДля объектов класса itemMatrix можно осуществить быструю визуализацию данных или построить график распределения частот встречаемости признаков (рис. 5.4).
image(trans)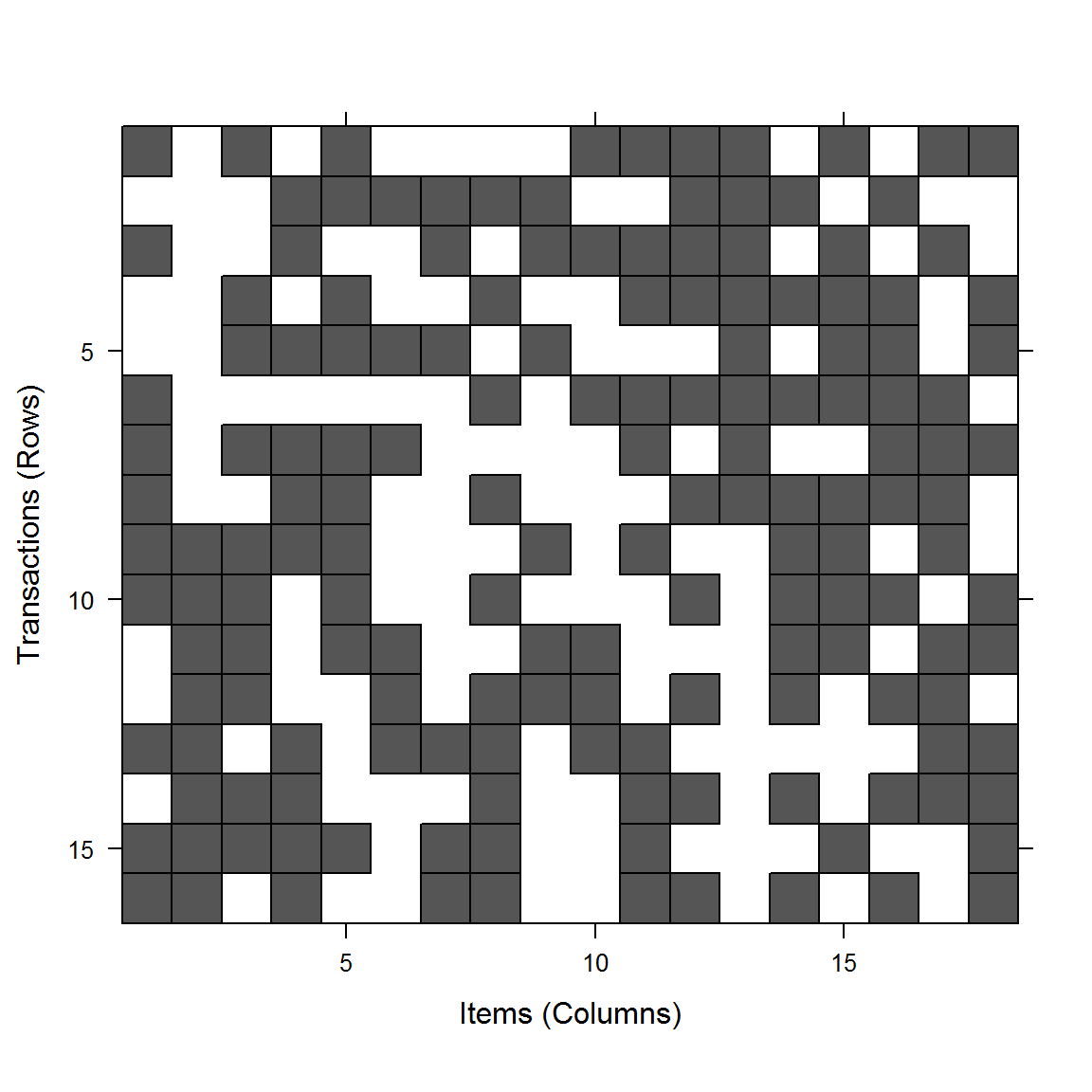
itemFrequencyPlot(trans, support = 0.1, cex.names = 0.8)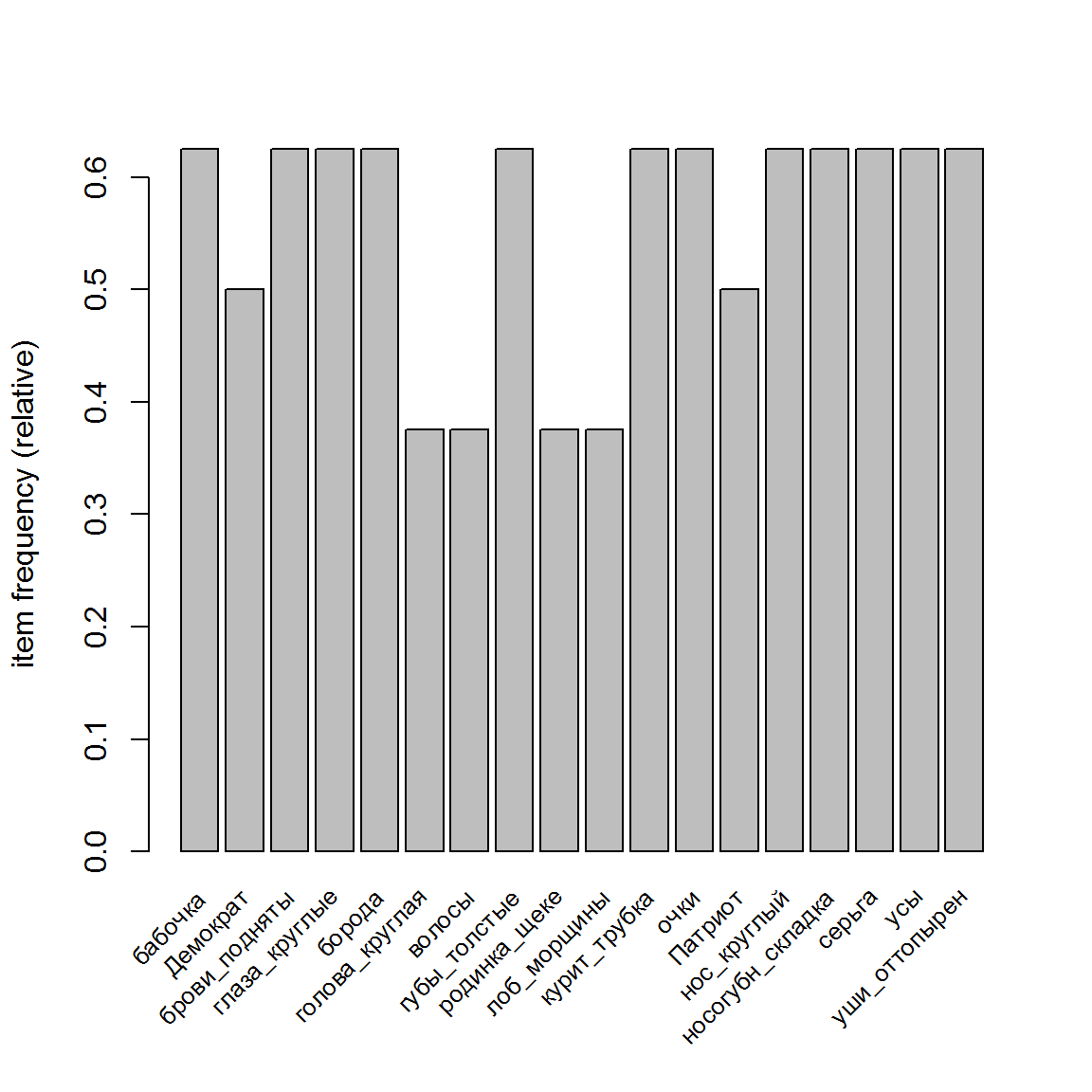
Рисунок 5.4: Матрица признаки/транзакции и частотное распределение встречаемости признаков в транзакциях
На первом шаге первой итерации алгоритма подсчитываются одноэлементные часто встречающиеся наборы. Для этого необходимо пройтись по всему массиву данных и подсчитать для них поддержку, т.е. сколько раз набор встречается в имеющемся наборе данных. При последующем поиске \(k\) -элементных наборов генерация претендентов состоит из двух фаз — формирование кандидатов нового уровня на основе \((k — 1)\) -элементных наборов, которые были определены на предыдущей итерации алгоритма, и удаление избыточных кандидатов. После того как найдены все часто встречающиеся наборы элементов, выполняют процедуру непосредственного извлечения правил из построенного хеш-дерева (Зайцев, 2009).
Результатом анализа транзакций с помощью пакета arules являются объекты класса associations, включающие описания множества отношений между признаками (в виде часто встречающихся фрагментов, или правил), которые отбираются в соответствии с различными перечисленными выше мерами качества. Подкласс rules состоит из двух объектов itemMatrix , представляющих левую lhs (left-hand-side) и правую rhs (right-hand-side) сторону правила \(\mathcal \rightarrow \mathcal\) , т.е. \(\mathcal\) — lhs , \(\mathcal\) — rhs .
Формирование правил осуществляется функцией apriori() с указанием пороговых значений поддержки и достоверности. Функция summary() обеспечивает частотный анализ правил по их длине и достигнутым мерам качества:
rules apriori(trans, parameter = list(support = 0.01, confidence = 0.6))## Apriori ## ## Parameter specification: ## confidence minval smax arem aval originalSupport maxtime support minlen ## 0.6 0.1 1 none FALSE TRUE 5 0.01 1 ## maxlen target ext ## 10 rules FALSE ## ## Algorithmic control: ## filter tree heap memopt load sort verbose ## 0.1 TRUE TRUE FALSE TRUE 2 TRUE ## ## Absolute minimum support count: 0 ## ## set item appearances . [0 item(s)] done [0.00s]. ## set transactions . [18 item(s), 16 transaction(s)] done [0.00s]. ## sorting and recoding items . [18 item(s)] done [0.00s]. ## creating transaction tree . done [0.00s]. ## checking subsets of size 1 2 3 4 5 6 7 8 9 10 done [0.00s]. ## writing . [48306 rule(s)] done [0.01s]. ## creating S4 object . done [0.02s].summary(rules) # Результаты показаны частично## set of 48306 rules ## ## rule length distribution (lhs + rhs):sizes ## 1 2 3 4 5 6 7 8 9 10 ## 12 138 916 3892 9860 14560 11814 5526 1428 160 ## ## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 1.00 5.00 6.00 6.14 7.00 10.00 ## ## summary of quality measures: ## support confidence lift ## Min. :0.06250 Min. :0.6000 Min. :0.960 ## 1st Qu.:0.06250 1st Qu.:1.0000 1st Qu.:1.600 ## Median :0.06250 Median :1.0000 Median :1.600 ## Mean :0.07788 Mean :0.9781 Mean :1.750 ## 3rd Qu.:0.06250 3rd Qu.:1.0000 3rd Qu.:1.600 ## Max. :0.62500 Max. :1.0000 Max. :2.667 ## ## mining info: ## data ntransactions support confidence ## trans 16 0.01 0.6Всего было отобрано 48306 правил, длина которых большей частью составляла от 5 до 7 элементов. Функция plot() из пакета arulesViz позволяет получать различные формы визуализации синтезированных правил, в том числе, анализ изменчивости их мер качества (рис. 5.5):
library(arulesViz) plot(rules, measure = c("support", "lift"), shading = "confidence")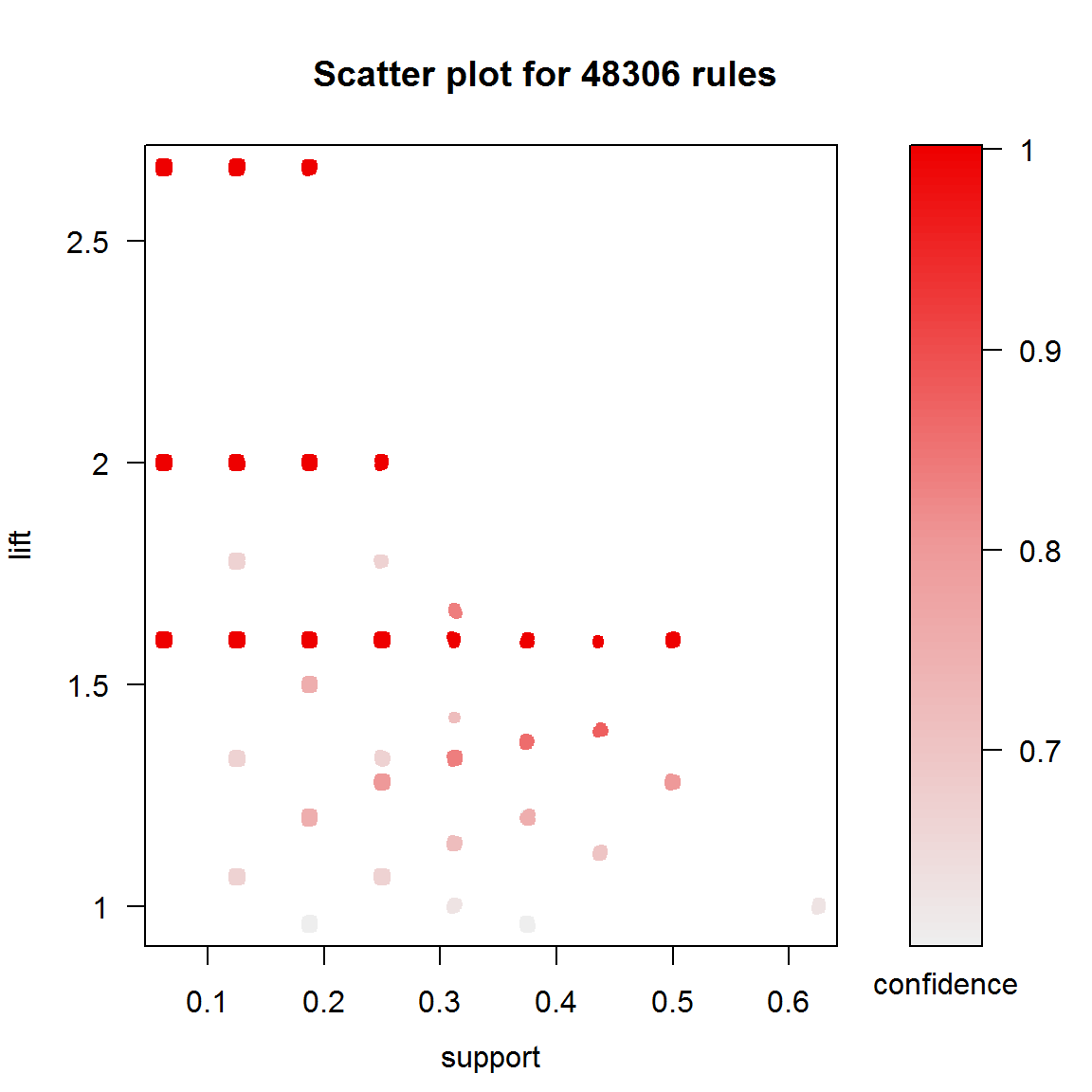
Рисунок 5.5: Поддержка, лифт и достоверность сгенерированных правил
Для решения задачи выявления характерных особенностей групп электората нас интересуют, в первую очередь, высококачественные правила, имеющие соответствующий признак группы в правой части. Тогда патриотов можно будет легко узнать по их облику (рис. 5.6):
rulesPat subset(rules, subset = rhs %in% "Патриот" & lift > 1.8) inspect(head(rulesPat, n = 10, by = "support"))## lhs rhs support confidence lift ## [1] => 0.2500 1 2 ## [2] => 0.2500 1 2 ## [3] => 0.2500 1 2 ## [4] => 0.2500 1 2 ## [5] => 0.2500 1 2 ## [6] => 0.1875 1 2 ## [7] => 0.1875 1 2 ## [8] => 0.1875 1 2 ## [9] => 0.1875 1 2 ## [10] => 0.1875 1 2plot(head(sort(rulesPat, by = "support"), 10), method = "paracoord")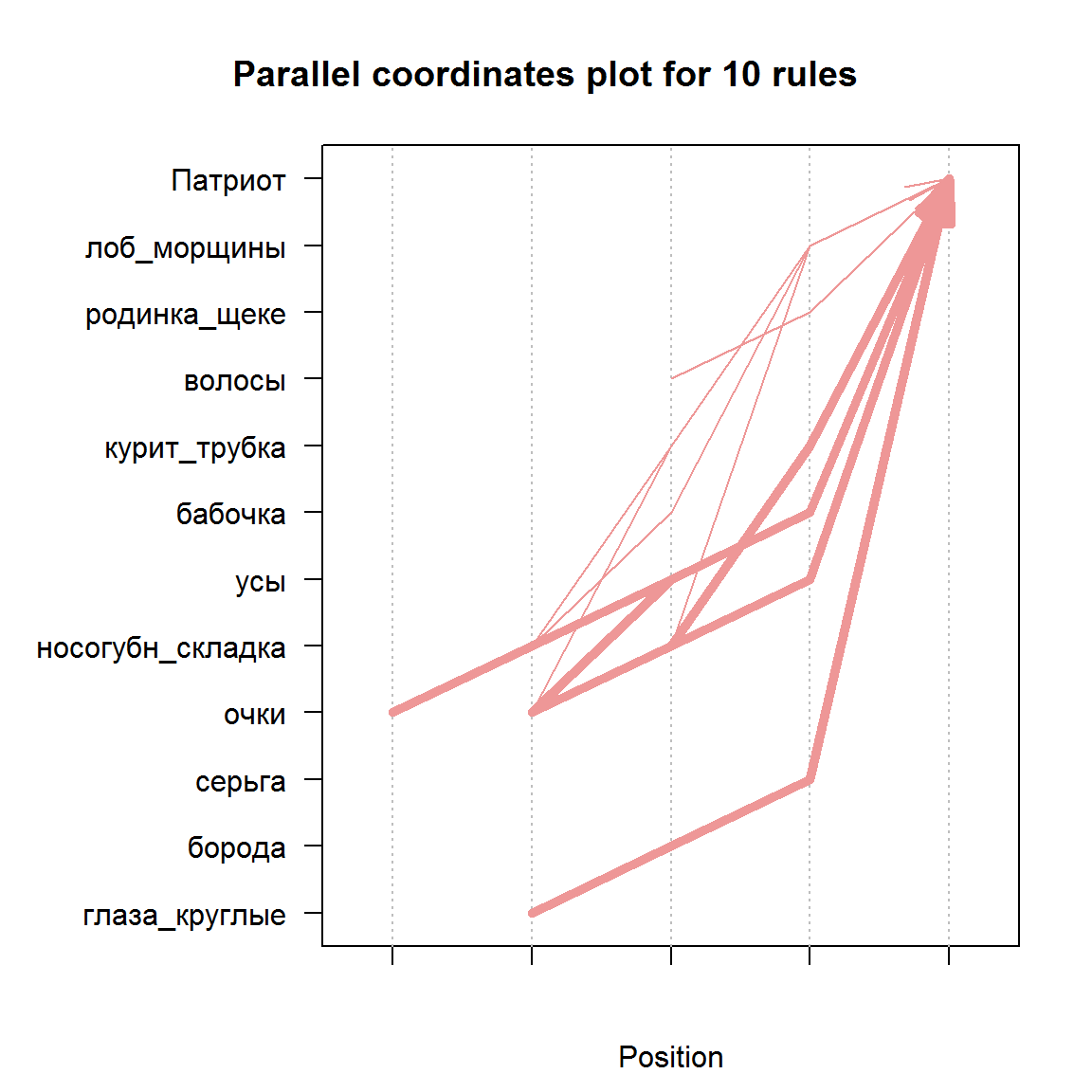
Рисунок 5.6: График 10 лучших правил для патриотов в параллельных координатах
График в параллельных координатах ( method=»paracoord» ) на рис. 5.6 показывает, как формируются комбинации признаков правой части при увеличении ее размера, а толщина линий соответствует уровню поддержки.
Аналогичные правила могут быть отобраны для группы демократично настроенных избирателей (рис. 5.7):
rulesDem subset(rules, subset = rhs %in% "Демократ" & lift > 1.8) inspect(head(rulesDem, n = 10, by = "support"))## lhs rhs support confidence lift ## [1] => 0.2500 1 2 ## [2] => 0.2500 1 2 ## [3] => 0.2500 1 2 ## [4] => 0.2500 1 2 ## [5] => 0.2500 1 2 ## [6] => 0.1875 1 2 ## [7] => 0.1875 1 2 ## [8] => 0.1875 1 2 ## [9] => 0.1875 1 2 ## [10] => 0.1875 1 2plot(head(sort(rulesDem, by = "support"), 10), method = "graph", control = list(nodeCol = grey.colors(10), edgeCol = grey(.7), alpha = 1))
Рисунок 5.7: Визуализация в форме графа 10 лучших правил для демократов
Метод «graph» функции plot() показывает правила и составляющие их признаки в виде графа, размер узлов которого пропорционален уровню поддержки каждого представленного правила (рис. 5.7).
6.2. Представление результатов
Решение задачи поиска ассоциативных правил, как и любой задачи, сводится к обработке исходных данных и получению результатов. Обработка над исходными данными выполняется по некоторому алгоритму Data Mining.
| Поиск ассоциативных правил | 149 |
Результаты, получаемые при решении этой задачи, принято представлять в виде ассоциативных правил. В связи с этим при их поиске выделяют два основных этапа: нахождение всех частых наборов объектов; генерация ассоциативных правил из найденных частых наборов объектов. Ассоциативные правила имеют следующий вид: если (условие) то (результат) где условие — обычно не логическое выражение (как в классификационных правилах), а набор объектов из множества I , с которыми связаны (ассоциированы) объекты, включенные в результат данного правила. Например, ассоциативное правило: если (кокосы, вода) то (орехи) означает, что если потребитель покупает кокосы и воду, то он покупает и орехи. Как уже отмечалось, в ассоциативных правилах условие и результат являются объектами множества I : если X то Y где X I,Y I, X Y = φ . Ассоциативное правило можно представить как импликацию над множеством X Y , где X I,Y I, X Y = φ . Основным достоинством ассоциативных правил является их легкое восприятие человеком и простая интерпретация языками программирования. Однако они не всегда полезны. Выделяют три вида правил: полезные правила — содержат действительную информацию, которая ранее была неизвестна, но имеет логичное объяснение. Такие правила могут быть использованы для принятия решений, приносящих выгоду; тривиальные правила — содержат действительную и легко объяснимую информацию, которая уже известна. Такие правила, хотя и объяснимы, но не могут принести какой-либо пользы, т. к. отражают или известные законы в исследуемой области, или результаты прошлой деятельности. Иногда такие правила могут использоваться для проверки выполнения решений, принятых на основании предыдущего анализа; непонятные правила — содержат информацию, которая не может быть объяснена. Такие правила могут быть получены или на основе аномальных значений, или глубоко скрытых знаний. Напрямую такие правила нельзя использовать для принятия решений, т. к. их необъяснимость может привести к непредсказуемым результатам. Для лучшего понимания требуется дополнительный анализ.
| 150 | Глава 6 |
Ассоциативные правила строятся на основе частых наборов. Так, правила, построенные на основании набора F (т. е. X Y = F ), являются всеми возможными комбинациями объектов, входящих в него. Например, для набора < кокосы , вода , орехи >могут быть построены следующие правила:
если (кокосы) то (вода); если (кокосы) то (орехи); если (кокосы) то (вода, орехи); если (вода, орехи) то (кокосы); если (вода) то (кокосы); если (вода) то (орехи);
если (вода) то (кокосы, орехи); если (кокосы, орехи) то (вода); если (орехи) то (вода); если (орехи) то (кокосы); если (орехи) то (вода, кокосы); если (вода, кокосы) то (орехи).
Таким образом, количество ассоциативных правил может быть очень большим и трудновоспринимаемым для человека. К тому же, не все из построенных правил несут в себе полезную информацию. Для оценки их полезности вводятся следующие величины. Поддержка (support) — показывает, какой процент транзакций поддерживает данное правило. Так как правило строится на основании набора, то, значит, правило X Y имеет поддержку, равную поддержке набора F , который составляют X и Y : Supp X Y = Supp F = | D F =X Y | . | D | Очевидно, что правила, построенные на основании одного и того же набора, имеют одинаковую поддержку, например, поддержка Supp если (вода, кокосы) то (орехи) = Supp <вода, кокосы, орехи>= 2/4. Достоверность (confidence) — показывает вероятность того, что из наличия в транзакции набора X следует наличие в ней набора Y . Достоверностью правила X Y является отношение числа транзакций, содержащих наборы X и Y , к числу транзакций, содержащих набор X :
| Conf X Y | = | | D F =X | Y | | = | Supp X Y | . |
| | D X | | | Supp X | ||||
Очевидно, что чем больше достоверность, тем правило лучше, причем у правил, построенных на основании одного и того же набора, достоверность будет разная, например: Conf если (вода) то (орехи) = 2/3; Conf если (орехи) то (вода) = 2/3;
| Поиск ассоциативных правил | 151 |
Conf если (вода, кокосы) то (орехи) = 1; Conf если (вода) то (орехи, кокосы) = 2/3. К сожалению, достоверность не позволяет оценить полезность правила. Если процент наличия в транзакциях набора Y при условии наличия в них набора X меньше, чем процент безусловного наличия набора Y , т. е.: Conf X Y = Supp X Y < Supp Y , Supp X это значит, что вероятность случайно угадать наличие в транзакции набора Y больше, чем предсказать это с помощью правила X Y . Для исправления такой ситуации вводится мера — улучшение. Улучшение (improvement) — показывает, полезнее ли правило случайного угадывания. Улучшение правила является отношением числа транзакций, содержащих наборы X и Y , к произведению количества транзакций, содержащих набор X , и количества транзакций, содержащих набор Y :
| impr X Y | = | | D F | =X Y | | | = | Supp X Y | . |
| | D X | || D Y | | | Supp X ·Supp Y | ||||
Например, impr если (вода, кокосы) то (орехи) = 0,5/(0,5·0,5) = 2. Если улучшение больше единицы, то это значит, что с помощью правила предсказать наличие набора Y вероятнее, чем случайное угадывание, если меньше единицы, то наоборот. В последнем случае можно использовать отрицающее правило, т. е. правило, которое предсказывает отсутствие набора Y : X не Y. У такого правила улучшение будет больше единицы, т. к. Supp не Y =1−Supp Y . Таким образом, можно получить правило, которое предсказывает результат лучше, чем случайным образом. Правда, на практике такие правила мало применимы. Например, правило: если (вода, орехи) то не пиво мало полезно, т. к. слабо выражает поведение покупателя. Данные оценки используются при генерации правил. Аналитик при поиске ассоциативных правил задает минимальные значения перечисленных величин. В результате те правила, которые не удовлетворяют этим условиям, отбрасываются и не включаются в решение задачи. С этой точки зрения нельзя
6 Поиск ассоциативных правил — Rules Mining
Привет, сегодня поговорим про поиск ассоциативных правил, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое поиск ассоциативных правил, rules mining , настоятельно рекомендую прочитать все из категории Интеллектуальный анализ данных. Выполнена постановка задачи. Рассмотренные формы представления результатов (правила классификации, дерева классификации, математические функции), методом ди построения правил классификации (алгоритм построения правил, метод Naive Bayes), а также методы построения деревьев классификации (методика
«разделяй и властвуй», алгоритм покрытия), методы построения математических функций (общий вид, линейные методы, метод наименьших квадратов, нелинейные методы, Support Vector Machines (SVM), регуляризацийни сети (Regularization Networks), дискретизации и редкие сетки). рассмотрена постановлением
новка задачи поиска ассоциативных правил (формальная постановка задачи, секвенциального анализ, разновидности задач поиска ассоциативных правил),
алгоритмы (алгоритм Apriori, разновидность алгоритма Apriori). ПЛАН 1 Постановка задачи.
2 Представление результатов (правила классификации, дерева классификации, математические функции).
3 Методы построения правил классификации (алгоритм построения пра вил, метод Naive Bayes).
4 Методы построения деревьев классификации (методика «разделяй и влавствуй «, алгоритм покрытия).
5 Методы построения математических функций (общий вид, линейные методы, метод наименьших квадратов, нелинейные методы, Support Vector
Machines (SVM), регуляризацийни сети (Regularization Networks), дискриминации кретизации и редкие сетки).
6 Постановка задачи поиска ассоциативных правил (формальная постановка задачи, секвенциального анализ, разновидности задачи поиска асоцианых правил).
7 Представление результатов.
8 Алгоритмы (алгоритм Apriori, разновидности алгоритма Apriori).
1 Постановка задачи.
Формальная постановка задачи
Одной из наиболее распространенных задач анализа данных является определение часто встречающихся наборов объектов в большом множестве наборов. Опишем эту задачу в обобщенном виде. Для этого обозначим объекты, составляющие исследуемые наборы (itemsets), следующим множеством: I = 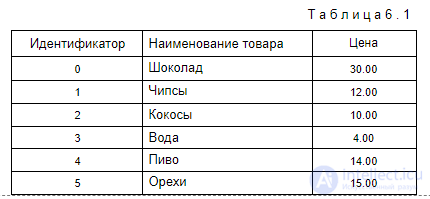 Они соответствуют следующему множеству объектов: I = . Наборы объектов из множества I, хранящиеся в БД и подвергаемые анализу, называются транзакциями. Опишем транзакцию как подмножество множества I: T =. Такие транзакции в магазине соответствуют наборам товаров, покупаемых потребителем и сохраняемых в БД в виде товарного чека или накладной. В них перечисляются приобретаемые покупателем товары, их цена, количество и др. Например, следующие транзакции соответствуют покупкам, совершаемым потребителями в супермаркете: T1 = ; T2 = . Набор транзакций, информация о которых доступна для анализа, обозначим следующим множеством: D = , где m — количество доступных для анализа транзакций. Например, в магазине таким множеством будет: D = <, , , >. Для использования методов Data Mining множество D может быть представлено в виде табл. 6.2. Т а б л и ц а 6 . 2
Они соответствуют следующему множеству объектов: I = . Наборы объектов из множества I, хранящиеся в БД и подвергаемые анализу, называются транзакциями. Опишем транзакцию как подмножество множества I: T =. Такие транзакции в магазине соответствуют наборам товаров, покупаемых потребителем и сохраняемых в БД в виде товарного чека или накладной. В них перечисляются приобретаемые покупателем товары, их цена, количество и др. Например, следующие транзакции соответствуют покупкам, совершаемым потребителями в супермаркете: T1 = ; T2 = . Набор транзакций, информация о которых доступна для анализа, обозначим следующим множеством: D = , где m — количество доступных для анализа транзакций. Например, в магазине таким множеством будет: D = <, , , >. Для использования методов Data Mining множество D может быть представлено в виде табл. 6.2. Т а б л и ц а 6 . 2 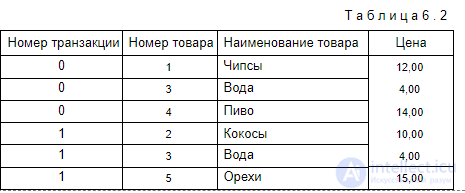
 Множество транзакций, в которые входит объект i j , обозначим следующим образом: Dij = D. В данном примере множеством транзакций, содержащих объект вода, является следующее множество: Dвода = <, , >. Некоторый произвольный набор объектов (itemset) обозначим следующим образом: F = . Например, F = . Набор, состоящий из k объектов, называется k-элементным набором (в данном примере это 2-элементный набор). Множество транзакций, в которые входит набор F , обозначим следующим образом: DF = D. В данном примере: D = <, >.
Множество транзакций, в которые входит объект i j , обозначим следующим образом: Dij = D. В данном примере множеством транзакций, содержащих объект вода, является следующее множество: Dвода = <, , >. Некоторый произвольный набор объектов (itemset) обозначим следующим образом: F = . Например, F = . Набор, состоящий из k объектов, называется k-элементным набором (в данном примере это 2-элементный набор). Множество транзакций, в которые входит набор F , обозначим следующим образом: DF = D. В данном примере: D = <, >.  Отношение количества транзакций, в которое входит набор F , к общему количеству транзакций называется поддержкой (support) набора F и обозначается Supp(F) : Supp(F) = | DF | . | D | Для набора поддержка будет равна 0,5, т. к. данный набор входит в две транзакции (с номерами 1 и 2), а всего транзакций 4. При поиске аналитик может указать минимальное значение поддержки интересующих его наборов Suppmin . Набор называется частым (large itemset), если значение его поддержки больше минимального значения поддержки, заданного пользователем: Supp(F) > Suppmin . Таким образом, при поиске ассоциативных правил требуется найти множество всех частых наборов: L= < F |Supp(F) >Suppmin> . Вданном примере частыми наборами при Suppmin = 0,5 являются следующие: Suppmin = 0,5; Suppmin = 0,5; Suppmin = 0,75; Suppmin = 0,5; Suppmin = 0,5; Suppmin = 0,75; Suppmin = 0,75; Suppmin = 0,5; Suppmin = 0,75.
Отношение количества транзакций, в которое входит набор F , к общему количеству транзакций называется поддержкой (support) набора F и обозначается Supp(F) : Supp(F) = | DF | . | D | Для набора поддержка будет равна 0,5, т. к. данный набор входит в две транзакции (с номерами 1 и 2), а всего транзакций 4. При поиске аналитик может указать минимальное значение поддержки интересующих его наборов Suppmin . Набор называется частым (large itemset), если значение его поддержки больше минимального значения поддержки, заданного пользователем: Supp(F) > Suppmin . Таким образом, при поиске ассоциативных правил требуется найти множество всех частых наборов: L= < F |Supp(F) >Suppmin> . Вданном примере частыми наборами при Suppmin = 0,5 являются следующие: Suppmin = 0,5; Suppmin = 0,5; Suppmin = 0,75; Suppmin = 0,5; Suppmin = 0,5; Suppmin = 0,75; Suppmin = 0,75; Suppmin = 0,5; Suppmin = 0,75.
Секвенциальный анализ
При анализе часто вызывает интерес последовательность происходящих событий. При обнаружении закономерностей в таких последовательностях можно с некоторой долей вероятности предсказывать появление событий в будущем, что позволяет принимать более правильные решения. Последовательностью называется упорядоченное множество объектов. Для этого на множестве должно быть задано отношение порядка. Тогда последовательность объектов можно описать в следующем виде: S = <. ip , . iq>, где p < q . Например, в случае с покупками в магазинах таким отношением порядка может выступать время покупок. Тогда последовательность S = <(вода, 02.03.2003), (чипсы, 05.03.2003), (пиво, 10.03.2003)>можно интерпретировать как покупки, совершаемые одним человеком в разное время (вначале была куплена вода, затем чипсы, а потом пиво). Различают два вида последовательностей: с циклами и без циклов. В первом случае допускается вхождение в последовательность одного и того же объекта на разных позициях: S = <. ip , . iq , . >, где p < q, iq = ip. Говорят, что транзакция T содержит последовательность S , если S T и объекты, входящие в S, входят и в множество Т с сохранением отношения порядка. При этом допускается, что в множестве Т между объектами из последовательности S могут находиться другие объекты. Поддержкой последовательности S называется отношение количества транзакций, в которое входит последовательность S, к общему количеству транзакций. Последовательность является частой, если ее поддержка превышает минимальную поддержку, заданную пользователем: Supp(S) >Suppmin . Задачей секвенциального анализа является поиск всех частых последовательностей: L = Suppmin> . Основным отличием задачи секвенциального анализа от поиска ассоциативных правил является установление отношения порядка между объектами множества I. Данное отношение может быть определено разными способами. При анализе последовательности событий, происходящих во времени, объектами множества I являются события, а отношение порядка соответствует хронологии их появления. Например, при анализе последовательности покупок в супермаркете наборами являются покупки, совершаемые в разное время одними и теми же покупателями, а отношением порядка в них является хронология покупок: D = , <(кокосы, вода), (пиво), (вода, шоколад, кокосы)>, <(пиво, чипсы, вода), (пиво)>>. Естественно, что в этом случае возникает проблема идентификации покупателей. На практике она решается введением дисконтных карт, имеющих уникальный идентификатор. Данное множество можно представить в виде табл. 6.3.  Интерпретировать такую последовательность можно следующим образом: покупатель с идентификатором 1 вначале купил кокосы и воду, затем купил пиво, в последний раз он купил воду, шоколад и кокосы. Поддержка, например, последовательности составит 2/3, т. к. она встречается у покупателей с идентификаторами 0 и 1. У последнего покупателя также встречается набор , но не сохраняется последовательность (он купил вначале воду, а затем пиво). Cеквенциальный анализ актуален и для телекоммуникационных компаний. Основная проблема, для решения которой он используется, — это анализ данных об авариях на различных узлах телекоммуникационной сети. Информация о последовательности совершения аварий может помочь в обнаружении неполадок и предупреждении новых аварий. Данные для такого анализа могут быть представлены, например, в виде табл. 6.4.
Интерпретировать такую последовательность можно следующим образом: покупатель с идентификатором 1 вначале купил кокосы и воду, затем купил пиво, в последний раз он купил воду, шоколад и кокосы. Поддержка, например, последовательности составит 2/3, т. к. она встречается у покупателей с идентификаторами 0 и 1. У последнего покупателя также встречается набор , но не сохраняется последовательность (он купил вначале воду, а затем пиво). Cеквенциальный анализ актуален и для телекоммуникационных компаний. Основная проблема, для решения которой он используется, — это анализ данных об авариях на различных узлах телекоммуникационной сети. Информация о последовательности совершения аварий может помочь в обнаружении неполадок и предупреждении новых аварий. Данные для такого анализа могут быть представлены, например, в виде табл. 6.4. 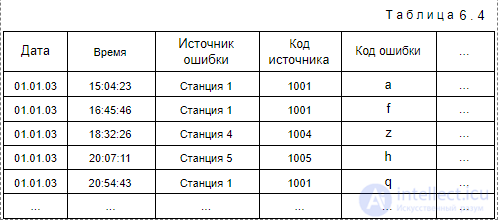 В данной задаче объектами множества I являются коды ошибок, возникающих в процессе работы телекоммуникационной сети. Последовательность Ssid содержит сбои, происходящие на станции с идентификатором sid. Их можно представить в виде пар (eid , t) , где eid — код ошибки, а t — время, когда она произошла. Таким образом, последовательность сбоев на станции с идентификатором sid будет иметь следующий вид: Ssid = <(eid1, t1), (eid2 , t2 ), . (eidn , tn )>. Для данных, приведенных в табл. 6.4, транзакции будут следующие: T1001 = <(a, 15:04:23 01.01.03), (f, 16:45:46 01.01.03), (q, 20:54:43 01.01.03), . >; T1004 = <(z, 18:32:26 01.01.03), . >; T1005 = <(h, 20:07:11 01.01.03), . >. Отношение порядка в данном случае задается относительно времени появления ошибки (значения t ).
В данной задаче объектами множества I являются коды ошибок, возникающих в процессе работы телекоммуникационной сети. Последовательность Ssid содержит сбои, происходящие на станции с идентификатором sid. Их можно представить в виде пар (eid , t) , где eid — код ошибки, а t — время, когда она произошла. Таким образом, последовательность сбоев на станции с идентификатором sid будет иметь следующий вид: Ssid = <(eid1, t1), (eid2 , t2 ), . (eidn , tn )>. Для данных, приведенных в табл. 6.4, транзакции будут следующие: T1001 = <(a, 15:04:23 01.01.03), (f, 16:45:46 01.01.03), (q, 20:54:43 01.01.03), . >; T1004 = <(z, 18:32:26 01.01.03), . >; T1005 = <(h, 20:07:11 01.01.03), . >. Отношение порядка в данном случае задается относительно времени появления ошибки (значения t ).
| (A, 0:12) | (C, 0:25) (A, 0:38) | (D, 0:53) | (A, 1:25) | (C, 1:42) | (C, 1:51) | |||||||||||
| 0:00 | 0:15 | 0:30 | 0:45 | 1:00 | 1:15 | 1:30 | 1:45 | 2:00 | ||||||||
Рис. 6.1. Последовательность сбоев на телекоммуникационной станции При анализе такой последовательности важным является определение интервала времени между сбоями. Оно позволяет предсказать момент и характер новых сбоев, а следовательно, предпринять профилактические меры. По этой причине при анализе данных интерес вызывает не просто последовательность событий, а сбои, которые происходят друг за другом. Например, на рис. 6.1 изображена временная шкала последовательности сбоев, происходящих на одной станции. При определении поддержки, например, для последовательности учитываются только следующие наборы: <(A, 0:12), (C, 0:25)>, <(A, 0:38), (C, 1:42)>, <(A, 1:25), (C, 1:42)>. При этом не учитываются следующие последовательности: <(A, 0:12), (C, 1:42)>, <(A, 0:12), (C, 1:51)>, <(A, 0:38), (C, 1:51)>и <(A, 1:25), (C, 1:51)>, т. к. они не следуют непосредственно друг за другом.
6.1.3. Разновидности задачи поиска ассоциативных правил
Во многих прикладных областях объекты множества I естественным образом объединяются в группы, которые в свою очередь также могут объединяться в более общие группы, и т. д. Таким образом, получается иерархическая структура объектов, представленная на рис. 6.2. 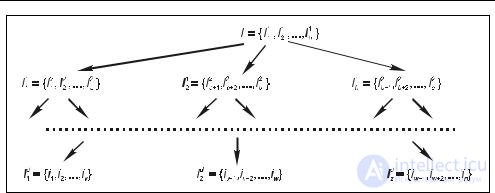
| Рис. 6.2. Иерархическое представление объектов множества I |
Для примера, приведенного в табл. 6.1, такой иерархии может быть следующая категоризация товаров:
| напитки; | еда; | |||
| • | алкогольные; | • | шоколад; | |
| пиво; | • | чипсы; | ||
| • | безалкогольные; | • | кокосы; | |
| вода; | • | орехи. | ||
Наличие иерархии изменяет представление о том, когда объект i присутствует в транзакции T . Об этом говорит сайт https://intellect.icu . Очевидно, что поддержка не отдельного объекта, а группы, в которую он входит, больше: Supp(Iqg ) ≥ Supp(i j ), где i j Iqg . Это связано с тем, что при анализе групп подсчитываются не только транзакции, в которые входит отдельный объект, но и транзакции, содержащие все объекты анализируемой группы. Например, если поддержка Supp = 2/4, то поддержка Supp = 2/4, т. к. объекты групп еда и напитки входят в транзакции с идентификаторами 0, 1 и 2. Использование иерархии позволяет определить связи, входящие в более высокие уровни иерархии, поскольку поддержка набора может увеличиваться, если подсчитывается вхождение группы, а не ее объекта. Кроме поиска наборов, часто встречающихся в транзакциях, состоящих из объектов F = или групп одного уровня иерархии F = , можно рассматривать
| также смешанные наборы объектов и групп | F = . Это по- |
зволяет расширить анализ и получить дополнительные знания. При иерархическом построении объектов можно варьировать характер поиска изменяя анализируемый уровень. Очевидно, что чем больше объектов во множестве I, тем больше объектов в транзакциях Т и частых наборах. Это в свою очередь увеличивает время поиска и усложняет анализ результатов. Уменьшить или увеличить количество данных можно с помощью иерархического представления анализируемых объектов. Перемещаясь вверх по иерархии, обобщаем данные и уменьшаем их количество, и наоборот. Недостатком обобщения объектов является меньшая полезность полученных знаний, т. к. в этом случае они относятся к группам товаров, что не всегда приемлемо. Для достижения компромисса между анализом групп и анализом отдельных объектов часто поступают следующим образом: сначала анализируют группы, а затем, в зависимости от полученных результатов, исследуют объекты заинтересовавших аналитика групп. В любом случае можно утверждать, что наличие иерархии в объектах и ее использование в задаче поиска ассоциативных правил позволяет выполнять более гибкий анализ и получать дополнительные знания. В рассмотренной задаче поиска ассоциативных правил наличие объекта в транзакции определялось только его присутствием в ней (ij T ) или отсут- ствием (ij T ) . Часто объекты имеют дополнительные атрибуты, как прави- ло, численные. Например, товары в транзакции имеют атрибуты: цена и количество. При этом наличие объекта в наборе может определяться не просто фактом его присутствия, а выполнением условия по отношению к определенному атрибуту. Например, при анализе транзакций, совершаемых покупателем, может интересовать не просто наличие покупаемого товара, а товара, покупаемого по некоторой цене. Для расширения возможностей анализа с помощью поиска ассоциативных правил в исследуемые наборы можно добавлять дополнительные объекты. В общем случае они могут иметь природу, отличную от основных объектов. Например, для определения товаров, имеющих больший спрос в зависимости от месторасположения магазина, в транзакции можно добавить объект, характеризующий район.
2. Представление результатов
Решение задачи поиска ассоциативных правил, как и любой задачи, сводится к обработке исходных данных и получению результатов. Обработка над исходными данными выполняется по некоторому алгоритму Data Mining. Результаты, получаемые при решении этой задачи, принято представлять в виде ассоциативных правил. В связи с этим при их поиске выделяют два основных этапа: нахождение всех частых наборов объектов; генерация ассоциативных правил из найденных частых наборов объектов. Ассоциативные правила имеют следующий вид: если (условие) то (результат) где условие — обычно не логическое выражение (как в классификационных правилах), а набор объектов из множества I , с которыми связаны (ассоциированы) объекты, включенные в результат данного правила. Например, ассоциативное правило: если (кокосы, вода) то (орехи) означает, что если потребитель покупает кокосы и воду, то он покупает и орехи. Как уже отмечалось, в ассоциативных правилах условие и результат являются объектами множества I : если X то Y где X I,Y I, X Y = φ . Ассоциативное правило можно представить как импликацию над множеством X Y , где X I,Y I, X Y = φ . Основным достоинством ассоциативных правил является их легкое восприятие человеком и простая интерпретация языками программирования. Однако они не всегда полезны. Выделяют три вида правил: полезные правила — содержат действительную информацию, которая ранее была неизвестна, но имеет логичное объяснение. Такие правила могут быть использованы для принятия решений, приносящих выгоду; тривиальные правила — содержат действительную и легко объяснимую информацию, которая уже известна. Такие правила, хотя и объяснимы, но не могут принести какой-либо пользы, т. к. отражают или известные законы в исследуемой области, или результаты прошлой деятельности. Иногда такие правила могут использоваться для проверки выполнения решений, принятых на основании предыдущего анализа; непонятные правила — содержат информацию, которая не может быть объяснена. Такие правила могут быть получены или на основе аномальных значений, или глубоко скрытых знаний. Напрямую такие правила нельзя использовать для принятия решений, т. к. их необъяснимость может привести к непредсказуемым результатам. Для лучшего понимания требуется дополнительный анализ.  Ассоциативные правила строятся на основе частых наборов. Так, правила, построенные на основании набора F (т. е. X Y = F ), являются всеми возможными комбинациями объектов, входящих в него. Например, для набора могут быть построены следующие правила: если (кокосы) то (вода); если (кокосы) то (орехи); если (кокосы) то (вода, орехи); если (вода, орехи) то (кокосы); если (вода) то (кокосы); если (вода) то (орехи); если (вода) то (кокосы, орехи); если (кокосы, орехи) то (вода); если (орехи) то (вода); если (орехи) то (кокосы); если (орехи) то (вода, кокосы); если (вода, кокосы) то (орехи). Таким образом, количество ассоциативных правил может быть очень большим и трудновоспринимаемым для человека. К тому же, не все из построенных правил несут в себе полезную информацию. Для оценки их полезности вводятся следующие величины. Поддержка (support) — показывает, какой процент транзакций поддерживает данное правило. Так как правило строится на основании набора, то, значит, правило X Y имеет поддержку, равную поддержке набора F , который составляют X и Y : SuppX Y = SuppF = | DF =X Y | . | D | Очевидно, что правила, построенные на основании одного и того же набора, имеют одинаковую поддержку, например, поддержка Supp если (вода, кокосы) то (орехи) = Supp = 2/4. Достоверность (confidence) — показывает вероятность того, что из наличия в транзакции набора X следует наличие в ней набора Y . Достоверностью правила X Y является отношение числа транзакций, содержащих наборы X и Y , к числу транзакций, содержащих набор X :
Ассоциативные правила строятся на основе частых наборов. Так, правила, построенные на основании набора F (т. е. X Y = F ), являются всеми возможными комбинациями объектов, входящих в него. Например, для набора могут быть построены следующие правила: если (кокосы) то (вода); если (кокосы) то (орехи); если (кокосы) то (вода, орехи); если (вода, орехи) то (кокосы); если (вода) то (кокосы); если (вода) то (орехи); если (вода) то (кокосы, орехи); если (кокосы, орехи) то (вода); если (орехи) то (вода); если (орехи) то (кокосы); если (орехи) то (вода, кокосы); если (вода, кокосы) то (орехи). Таким образом, количество ассоциативных правил может быть очень большим и трудновоспринимаемым для человека. К тому же, не все из построенных правил несут в себе полезную информацию. Для оценки их полезности вводятся следующие величины. Поддержка (support) — показывает, какой процент транзакций поддерживает данное правило. Так как правило строится на основании набора, то, значит, правило X Y имеет поддержку, равную поддержке набора F , который составляют X и Y : SuppX Y = SuppF = | DF =X Y | . | D | Очевидно, что правила, построенные на основании одного и того же набора, имеют одинаковую поддержку, например, поддержка Supp если (вода, кокосы) то (орехи) = Supp = 2/4. Достоверность (confidence) — показывает вероятность того, что из наличия в транзакции набора X следует наличие в ней набора Y . Достоверностью правила X Y является отношение числа транзакций, содержащих наборы X и Y , к числу транзакций, содержащих набор X :
| ConfX Y | = | | DF =X | Y | | = | SuppX Y | . |
| | DX | | | SuppX | ||||
Очевидно, что чем больше достоверность, тем правило лучше, причем у правил, построенных на основании одного и того же набора, достоверность будет разная, например: Conf если (вода) то (орехи) = 2/3; Conf если (орехи) то (вода) = 2/3;  Conf если (вода, кокосы) то (орехи) = 1; Conf если (вода) то (орехи, кокосы) = 2/3. К сожалению, достоверность не позволяет оценить полезность правила. Если процент наличия в транзакциях набора Y при условии наличия в них набора X меньше, чем процент безусловного наличия набора Y , т. е.: ConfX Y = SuppX Y < SuppY , SuppX это значит, что вероятность случайно угадать наличие в транзакции набора Y больше, чем предсказать это с помощью правила X Y . Для исправления такой ситуации вводится мера — улучшение. Улучшение (improvement) — показывает, полезнее ли правило случайного угадывания. Улучшение правила является отношением числа транзакций, содержащих наборы X и Y , к произведению количества транзакций, содержащих набор X , и количества транзакций, содержащих набор Y :
Conf если (вода, кокосы) то (орехи) = 1; Conf если (вода) то (орехи, кокосы) = 2/3. К сожалению, достоверность не позволяет оценить полезность правила. Если процент наличия в транзакциях набора Y при условии наличия в них набора X меньше, чем процент безусловного наличия набора Y , т. е.: ConfX Y = SuppX Y < SuppY , SuppX это значит, что вероятность случайно угадать наличие в транзакции набора Y больше, чем предсказать это с помощью правила X Y . Для исправления такой ситуации вводится мера — улучшение. Улучшение (improvement) — показывает, полезнее ли правило случайного угадывания. Улучшение правила является отношением числа транзакций, содержащих наборы X и Y , к произведению количества транзакций, содержащих набор X , и количества транзакций, содержащих набор Y :
| imprX Y | = | | DF | =X Y | | | = | SuppX Y | . |
| | DX | || DY | | | SuppX ·SuppY | ||||
Например, imprесли (вода, кокосы) то (орехи) = 0,5/(0,5·0,5) = 2. Если улучшение больше единицы, то это значит, что с помощью правила предсказать наличие набора Y вероятнее, чем случайное угадывание, если меньше единицы, то наоборот. В последнем случае можно использовать отрицающее правило, т. е. правило, которое предсказывает отсутствие набора Y : Xне Y. Утакого правила улучшение будет больше единицы, т. к. Suppне Y =1−SuppY . Таким образом, можно получить правило, которое предсказывает результат лучше, чем случайным образом. Правда, на практике такие правила мало применимы. Например, правило: если (вода, орехи) то не пиво мало полезно, т. к. слабо выражает поведение покупателя. Данные оценки используются при генерации правил. Аналитик при поиске ассоциативных правил задает минимальные значения перечисленных величин. В результате те правила, которые не удовлетворяют этим условиям, отбрасываются и не включаются в решение задачи. С этой точки зрения нельзя объединять разные правила, хотя и имеющие общую смысловую нагрузку. Например, следующие правила: X = Y = , X = Y = нельзя объединить в одно: X= Y = , т.к. достоверности их будут разные, следовательно, некоторые из них могут быть исключены, а некоторые — нет. Если объекты имеют дополнительные атрибуты, которые влияют на состав объектов в транзакциях, а следовательно, и в наборах, то они должны учитываться в генерируемых правилах. В этом случае условная часть правил будет содержать не только проверку наличия объекта в транзакции, но и более сложные операции сравнения: больше, меньше, включает и др. Результирующая часть правил также может содержать утверждения относительно значений атрибутов. Например, если у товаров рассматривается цена, то правила могут иметь следующий вид: если пиво.цена < 10 то чипсы.цена < 7. Данное правило говорит о том, что если покупается пиво по цене меньше 10 р., то, вероятно, будут куплены чипсы по цене меньше 7 р.
3. Алгоритмы
Алгоритм Apriori
Выявление частых наборов объектов — операция, требующая большого количества вычислений, а следовательно, и времени. Алгоритм Apriori описан в 1994 г. Срикантом Рамакришнан (Ramakrishnan Srikant) и Ракешом Агравалом (Rakesh Agrawal). Он использует одно из свойств поддержки, гласящее: поддержка любого набора объектов не может превышать минимальной поддержки любого из его подмножеств: SuppF ≤ SuppE при E F. Например, поддержка 3-объектного набора <пиво, вода, чипсы>будет всегда меньше или равна поддержке 2-объектных наборов <пиво, вода>, , <пиво, чипсы>. Это объясняется тем, что любая транзакция, содержащая <пиво, вода, чипсы>, содержит также и наборы <пиво, вода>, , <пиво, чипсы>, причем обратное неверно. Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов. На i -м этапе определяются все часто встречающиеся i -элементные наборы. Каждый этап состоит из двух шагов: формирования кандидатов (candidate generation) и подсчета поддержки кандидатов (candidate counting). Рассмотрим i -й этап. На шаге формирования кандидатов алгоритм создает множество кандидатов из i -элементных наборов, чья поддержка пока не вычисляется. На шаге подсчета кандидатов алгоритм сканирует множество транзакций, вычисляя поддержку наборов-кандидатов. После сканирования отбрасываются кандидаты, поддержка которых меньше определенного пользователем минимума, и сохраняются только часто встречающиеся i -элемент- ные наборы. Во время 1-го этапа выбранное множество наборов-кандидатов содержит все 1-элементные частые наборы. Алгоритм вычисляет их поддержку во время шага подсчета кандидатов. Описанный алгоритм можно записать в виде следующего псевдокода: L1 = для (k=2; Lk-1 <> φ; k++) Ck = Apriorigen(Fk-1) // генерация кандидатов для всех транзакций t D выполнить Ct = subset(Ck, t) // удаление избыточных правил для всех кандидатов c Ct выполнить c.count ++ конец для всех конец для всех Lk = < c Ck | c.count >= Suppmin> // отбор кандидатов конец для Результат = Lk k Опишем обозначения, используемые в алгоритме: Lk — множество k-элементных частых наборов, чья поддержка не меньше заданной пользователем. Каждый член множества имеет набор упорядоченных ( i j < ip , если j < p ) элементов F и значение поддержки набора SuppF >Suppmin : Lk = , где Fj = ; Ck — множество кандидатов k -элементных наборов потенциально частых. Каждый член множества имеет набор упорядоченных ( i j < ip , если j < p ) элементов F и значение поддержки набора Supp .
| Опишем данный алгоритм по шагам. | |
| Øàã 1. Присвоить k = 1 и выполнить | отбор всех 1-элементных наборов, |
у которых поддержка больше минимально заданной пользователем Suppmin . Øàã 2. k = k +1. Øàã 3. Если не удается создавать k-элементные наборы, то завершить алгоритм, иначе выполнить следующий шаг. Øàã 4. Создать множество k-элементных наборов кандидатов в частые наборы. Для этого необходимо объединить в k-элементные кандидаты (k – 1)- элементные частые наборы. Каждый кандидат c Ck будет формироваться путем добавления к (k – 1)-элементному частому набору — p элемента из другого (k – 1)-элементного частого набора — q. Причем добавляется последний элемент набора q, который по порядку выше, чем последний элемент набора p (p.itemk–1 < q.itemk–1). При этом первые все (k – 2) элемента обоих наборов одинаковы (p.item1 = q.item1, p.item2 = q.item2, . p.itemk–2 = q.itemk–2). Это может быть записано в виде следующего SQL-подобного запроса. insert into Ck select p.item1, p.item2, . p.itemk-1, q.itemk-1 from Lk-1 p, Lk-1 q where p.item1 = q.item1, p.item2 = q.item2, . p.itemk-2 = q.itemk-2, p.itemk-1 < q.itemk-1 Øàã 5. Для каждой транзакции Т из множества D выбрать кандидатов Ct из множества Ck , присутствующих в транзакции Т. Для каждого набора из построенного множества Ck удалить набор, если хотя бы одно из его (k – 1) подмножеств не является часто встречающимся, т. е. отсутствует во множе- стве Lk 1 . Это можно записать в виде следующего псевдокода: − для всех наборов c Ck выполнить для всех (k-1) – поднаборов s из c выполнить если (s Lk-1) то удалить c из Ck Øàã 6. Для каждого кандидата из множества Ck увеличить значение поддержки на единицу. Øàã 7. Выбрать только кандидатов Lk из множества Ck , у которых значение поддержки больше заданной пользователем Suppmin . Вернуться к шагу 2. Результатом работы алгоритма является объединение всех множеств Lk для всех k. Рассмотрим работу алгоритма на примере, приведенном в табл. 6.1, при Suppmin = 0,5 . На первом шаге имеем следующее множество кандидатов C1 (указываются идентификаторы товаров) (табл. 6.5).
| Т а б л и ц а 6 . 5 | ||
| № | Набор | Supp |
| 1 | 0 | |
| 2 | 0,5 | |
| 3 | 0,75 | |
| 4 | 0,25 | |
| 5 | 0,75 | |
| 6 | 0,75 |
Заданной минимальной поддержке удовлетворяют только кандидаты 2, 3, 5 и 6, следовательно: L1 = , , , >. На втором шаге увеличиваем значение k до двух. Так как можно построить 2-элементные наборы, то получаем множество C2 (табл. 6.6).
| Т а б л и ц а 6 . 6 | ||
| № | Набор | Supp |
| 1 | 0,25 | |
| 2 | 0,5 | |
| 3 | 0,25 | |
| 4 | 0,5 | |
| 5 | 0,75 | |
| 6 | 0,5 |
Из построенных кандидатов заданной минимальной поддержке удовлетворяют только кандидаты 2, 4, 5 и 6, следовательно: L2 = , , , >. На третьем шаге перейдем к созданию 3-элементных кандидатов и подсчету их поддержки. В результате получим следующее множество C3 (табл. 6.7).
| 156 | Глава 6 | |
| Т а б л и ц а 6 . 7 | ||
| № | Набор | Supp |
| 1 | 0,5 | |
Данный набор удовлетворяет минимальной поддержке, следовательно: L3 = >. Так как 4-элементные наборы создать не удастся, то результатом работы алгоритма является множество: L = L1 L2 L3 = , , , , , , , , >. Для подсчета поддержки кандидатов нужно сравнить каждую транзакцию с каждым кандидатом. Очевидно, что количество кандидатов может быть очень большим и нужен эффективный способ подсчета. Гораздо быстрее и эффективнее использовать подход, основанный на хранении кандидатов в хэш-дереве. Внутренние узлы дерева содержат хэш-таблицы с указателями на потомков, а листья — на кандидатов. Это дерево используется при быстром подсчете поддержки для кандидатов. Хэш-дерево строится каждый раз, когда формируются кандидаты. Первоначально дерево состоит только из корня, который является листом, и не содержит никаких кандидатов-наборов. Каждый раз, когда формируется новый кандидат, он заносится в корень дерева, и так до тех пор, пока количество кандидатов в корне-листе не превысит некоего порога. Как только это происходит, корень преобразуется в хэш-таблицу, т. е. становится внутренним узлом, и для него создаются потомки-листья. Все кандидаты распределяются по узлам-потомкам согласно хэш-значениям элементов, входящих в набор. Каждый новый кандидат хэшируется на внутренних узлах, пока не достигнет первого узла-листа, где он и будет храниться, пока количество наборов опять же не превысит порога. После того как хэш-дерево с кандидатами-наборами построено, легко подсчитать поддержку для каждого кандидата. Для этого нужно «пропустить» каждую транзакцию через дерево и увеличить счетчики для тех кандидатов, чьи элементы также содержатся и в транзакции, Ck ∩Ti = Ck . На корневом уровне хэш-функция применяется к каждому объекту из транзакции. Далее, на втором уровне, хэш-функция применяется ко вторым объектам и т. д. На k-м уровне хэшируется k -элемент, и так до тех пор, пока не достигнем листа. Если кандидат, хранящийся в листе, является подмножеством рассматриваемой транзакции, увеличиваем счетчик поддержки этого кандидата на единицу. После того как каждая транзакция из исходного набора данных «пропущена» через дерево, можно проверить, удовлетворяют ли значения поддержки кандидатов минимальному порогу. Кандидаты, для которых это условие выполняется, переносятся в разряд часто встречающихся. Кроме того, следует запомнить и поддержку набора, которая пригодится при извлечении правил. Эти же действия применяются для нахождения (k + 1)-элементных наборов и т. д.
. Разновидности алгоритма Apriori
Алгоритм AprioriTid является разновидностью алгоритма Apriori. Отличительной чертой данного алгоритма является подсчет значения поддержки кандидатов не при сканировании множества D , а с помощью множества Ck , являющегося множеством кандидатов (k-элементных наборов) потенциально частых, в соответствие которым ставится идентификатор TID транзакций, в которых они содержатся. Каждый член множества Ck является парой вида < TID, Fk >, где каждый Fk является потенциально частым k -элементным набором, представленным в транзакции с идентификатором TID. Множество C1 = D соответствует множеству транзакций, хотя каждый объект в транзакции соответствует одно- объектному набору в множестве C1 , содержащем этот объект. Для k >1 множество Ck генерируется в соответствии с алгоритмом, описанным ниже. Член множества Ck , соответствующий транзакции Т, является парой следующего вида: < T.TID,
Выводы
Из материала, изложенного в данной главе, можно сделать следующие выводы. Задачей поиска ассоциативных правил является определение часто встречающихся наборов объектов в большом множестве наборов. Секвенциальный анализ заключается в поиске частых последовательностей. Основным отличием задачи секвенциального анализа от поиска ассоциативных правил является установление отношения порядка между объектами. Наличие иерархии в объектах и ее использование в задаче поиска ассоциативных правил позволяет выполнять более гибкий анализ и получать дополнительные знания. Результаты решения задачи представляются в виде ассоциативных правил, условная и заключительная часть которых содержит наборы объектов. Основными характеристиками ассоциативных правил являются поддержка, достоверность и улучшение. Поддержка (support) показывает, какой процент транзакций поддерживает данное правило. Достоверность (confidence) показывает, какова вероятность того, что из наличия в транзакции набора условной части правила следует наличие в ней набора заключительной части. Улучшение (improvement) показывает, полезнее ли правило случайного угадывания. Задача поиска ассоциативных правил решается в два этапа. На первом выполняется поиск всех частых наборов объектов. На втором из найденных частых наборов объектов генерируются ассоциативные правила. Алгоритм Apriori использует одно из свойств поддержки, гласящее: поддержка любого набора объектов не может превышать минимальной поддержки любого из его подмножеств. К сожалению, в одной статье не просто дать все знания про поиск ассоциативных правил. Но я — старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое поиск ассоциативных правил, rules mining и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных
Выявление обобщенных ассоциативных правил

Методы поиска обобщенных правил при вычислении используют информацию о группировке элементов (таксономию), что позволяет значительно расширить круг задач, решаемых алгоритмами поиска ассоциативных правил. Примером обобщенного ассоциативного правила может служить высказывание: «Если человек купил Ряженку, то он, скорее всего, купит товар из группы Хлебобулочные изделия». В статье приведены два метода вычисления обобщенных ассоциативных правил: базовый и улучшенный алгоритмы.
Введение
В данной статье будет обсуждаться проблема выявления обобщенных ассоциативных правил. Здесь мы будем использовать некоторые определения и термины, которые были описаны в статье «Введение в анализ ассоциативных правил». Наряду с уже известными параметрами правила такими как поддержка и достоверность опишем такой параметр, как уровень интереса. Также будут приведены два алгоритма вычисления обобщенных ассоциативных правил: базовый алгоритм и улучшенный алгоритм.
Основным отличием обобщенных ассоциативных правил от ассоциативных правил является то, что получаемые правила включают элементы, являющиеся предками элементов, входящих во множество транзакций.
Определение 1. Иерархией (таксономией) элементов называется лес направленных ациклических деревьев, листьями которых являются элементы транзакций, а внутренними узлами — группы элементов.
Пример иерархии товаров и товарных групп приведен на рис. 1. Имея такую иерархию, можно получить, например, такие правила: «Если покупатель купил Сок, то он, скорее всего, захочет купить Кефир»; «Если покупатель купил Молочные продукты, то он, скорее всего, захочет купить Минеральную воду». То есть, в получаемых правилах, как в условии, так и в следствии могут присутствовать элементы, находящиеся на разных уровнях таксономии.
Введение информации о принадлежности элементов транзакций к той или иной группе может дать следующие преимущества:
- Будут выявлены ассоциативные правила не только между отдельными элементами, но и между различными уровнями иерархии.
- В некоторых случаях отдельные элементы могут иметь очень маленькую поддержку, однако, значение поддержки всей группы, в которую входит этот элемент, может быть больше порога минимальной поддержки. Это приводит к тому, что ранее не выявленное потенциально интересное правило, построенное на элементах нижнего уровня иерархии, может быть получено, но его элементами будут либо элементы транзакции, либо предки этих элементов.
- Введение информации о группировке элементов может использоваться для отсечения «неинтересных» правил.
Пусть I= — это множество элементов. Пусть I — это лес направленных деревьев. Дуги в I — это зависимости между элементами. Пусть элементы, принадлежащие I , расположены в некой иерархии. Если есть дуга от a к b , то говорят, что a — предок b , и b — потомок a ( a — это обобщение b ).
Пусть имеется множество транзакций D , где каждая транзакция T — это множество элементов (событий), произошедших одновременно. Имеет место следующее утверждение: T⊆I .
Определение 2. Расширенной транзакцией называется транзакция, расширенная предками всех элементов, входящих в эту транзакцию.
Определение 3. Обобщенным ассоциативным правилом называется импликация X \Rightarrow Y , где X⊂I , Y⊂I и X∩Y=\varnothing , и где ни один из элементов, входящих в набор Y , не является предком ни одного элемента, входящего в X . Правило X⇒Y имеет поддержку s (support), если s расширенных транзакций, содержат X∪Y , supp(X∪Y)=supp(X⇒Y) . Достоверность правила показывает, какова вероятность того, что из X следует Y . Правило X⇒Y справедливо с достоверностью c (confidence), если c расширенных транзакций, содержащих X , также содержат Y , conf(X⇒Y)=supp(X∪Y)/supp(X) .
Мы называем правило X⇒Y обобщенным, потому что элементы, входящие в него, могут находиться на любом уровне таксономии. Также будем называть \underline — предком x и x — потомком \underline .
Пусть D — это множество транзакций, а I — множество элементов, находящихся в иерархической зависимости. Необходимо найти закономерности, которые являются обобщенными ассоциативными правилами вида X⇒Y , причем supp(X⇒Y)>=minsupp и conf(X⇒Y)>=minconf .
Это определение задачи имеет одну проблему. Дело в том, что при таком определении задачи, будут найдены «излишние» обобщенные ассоциативные правила. Для решения этой проблемы рассмотрим такой параметр правила, как уровень интереса.
Пусть Pr(X) — это вероятность того, что все элементы из X содержаться в одной расширенной транзакции. Тогда supp(X∪Y)=Pr(X∪Y) и conf(X⇒Y)=Pr(Y|X) . Если поддержка [x,y] больше значения минимальной поддержки, то и поддержка [\underline,y] , и поддержка [,\underline] , и поддержка [\underline,\underline] будет больше порога минимальной поддержки. Однако, если достоверность правила X⇒Y больше минимальной достоверности, только правило X \Rightarrow \underline гарантированно будет иметь достоверность больше, чем минимальная. Поддержка элемента, взятого из внутреннего уровня иерархии не равна сумме поддержек элементов, являющихся непосредственными потомками этого элемента.
Определение «интересных» правил
Многие обобщенные ассоциативные правила, которые могут быть найдены, являются потенциально неинтересными (примерно 20% — 70%). Для определения того, какие правила являются «интересными», а какие нет, определим такой параметр, как уровень интереса.
Пусть \underline — это предок Z , где Z и \underline — множества элементов, входящих в иерархию (Z,Z⊆I) . \underline является предком Z , только в том случае, если \underline можно получить из Z путем подмены одного или нескольких элементов их предками. Если рассматривать иерархию на рис. 1, то примером могут быть эти два множества: Z =< Сок, Кефир, Бумага >, \underline =< Напитки, Молочные продукты, Бумага >. Будем называть правила \underline \Rightarrow Y , X \Rightarrow \underline , X \Rightarrow Y предками правила X⇒Y .
Определение 4. Правило \underline \Rightarrow \underline является ближайшим предком правила X⇒Y , если не существует такого правила X’⇒Y’ , что X’⇒Y’ — это предок X \Rightarrow и \underline \Rightarrow \underline — это предок X’⇒Y’ .
Подобные определения можно дать и для правил: \underline \Rightarrow Y , X \Rightarrow \underline .
Рассмотрим правило X⇒Y . Пусть Z=X∪Y . Заметим, что supp(X⇒Y)=supp(Z) . Назовем E_<\underline Z>\,\bigl[Pr\,(Z)\bigr] ожидаемым значением Pr(Z) относительно \underline . Пусть Z=[z_1. z_n] , Z=[z_1. z_j,z_. z_n] , 1 < = j < = n . Тогда можно определить:
Аналогично E_<\underline X \Rightarrow \underline Y>\,\Bigl[Pr\,(Y\,|\,X)\Bigr] определим как ожидаемое значение достоверности правила X⇒Y относительно \underline \Rightarrow \underline . Пусть Y=[y_1, . y_n] , \underline=[\underline_1, . \underline_j, y_j+1. y_n] , 1 < = j < = n . Тогда можно определить
Определение 5. Правило X⇒Y называется R -интересным относительно правила-предка, если поддержка правила X⇒Y в R раз больше ожидаемой поддержки правила X⇒Y относительно правила-предка или если достоверность правила X⇒Y в R раз больше ожидаемой достоверности правила X⇒Y относительно правила-предка.
Определение 6. Правило называется интересным, если у него нет предков или оно является R интересным относительно всех своих ближайших предков.
Определение 7. Правило называется частично интересным, если у него нет предков или оно является R -интересным относительно любого своего ближайшего предка.
Пусть в результате работы алгоритма мы получили следующие правила (таблица 1). Поддержка элементов входящих в них приведена в таблице 2. Иерархия элементов дана рис. 1. Уровень интереса R=1,3 .
| N правила | Текст правила | Поддержка, % |
|---|---|---|
| 1 | Сок ⇒ Молочные продукты | 10 |
| 2 | Безалкогольные напитки ⇒ Кефир | 15 |
| 3 | Сок ⇒ Кефир | 9 |
Таблица 1. Обобщенные ассоциативные правила
| Элемент | Поддержка, % |
|---|---|
| Напитки | 7 |
| Безалкогольные напитки | 5 |
| Сок | 3 |
| Молочные продукты | 6 |
| Кефир | 3 |
Таблица 2. Поддержка элементов
Рассмотрим правило номер 3. Определим, является ли это правило интересным, частично интересным или нет. Другими словами, нам необходимо проверить неравенство:
Pr[ \text \Rightarrow \text]>E_<\underline \text\Rightarrow \underline \text > [Pr( \text \Rightarrow \text)]* R
Правило 2 является ближним предком правила 3, посчитаем ожидаемую поддержку.
не выполняется, следовательно, правило 3 не является интересным.
Pr(\text \Rightarrow \text)> E_< \text\Rightarrow \text > (\text \Rightarrow \text)* R
не выполняется, следовательно, правило 3 не является интересным.
Правило 1 тоже является ближним предком правила 3, посчитаем ожидаемую поддержку.
Пусть D — это множество транзакций, а I — множество элементов, находящихся в иерархической зависимости. Необходимо найти закономерности, которые являются обобщенными ассоциативными правилами вида X⇒Y , причем поддержка правила X⇒Y больше или равна некоему наперед заданному значению минимальной поддержки и достоверность больше или равна значению минимальной достоверности и правила X⇒Y является интересными или частично интересными.
Алгоритм вычисления обобщенных ассоциативных правил
Как может показаться с первого взгляда, для вычисления обобщенных ассоциативных правил можно использовать любой алгоритм выявления ассоциативных правил, дополнив каждую транзакцию предками каждого элемента, входящего в транзакцию. Однако, такой метод «в лоб» очень неэффективен и использование его влечет за собой следующие проблемы:
- Размер каждой транзакции увеличивается в зависимости от глубины дерева от нескольких десятков процентов до нескольких раз. Как следствие, время вычисления и количество правил увеличиваются.
- Появление избыточных правил, в которых в условии и в следствии находятся элемент и его предок. Примером такого правила может быть «Если покупатель купил Кефир, то он, скорее всего, захочет купить Молочные продукты». Совершенно ясно, что практическая ценность этого правила равна нулю при достоверности равной 100%.
Для решения этой проблемы необходимо использование специального алгоритма, учитывающего всю специфику обобщенных ассоциативных правил.
Процесс вычисления обобщенных ассоциативных правил можно разбить на несколько этапов:
- Поиск часто встречающихся множеств элементов, поддержка которых больше, чем заданный порог поддержки (минимальная поддержка).
- Вычисления правил на основе найденных на предыдущем этапе часто встречающихся множеств элементов. Основная идея вычисления правил на основе часто встречающихся множеств заключается в следующем: если ABCD — это часто встречающееся множество элементов, то на основе этого множества можно построить правила X⇒Y (например, AB⇒CD ), причем X∪Y=ABCD . Поддержка правила равна поддержке часто встречающегося множества. Достоверность правила вычисляется по формуле conf(X⇒Y)=supp(X⇒Y)/supp(X) . Правило добавляется к результирующему списку правил, если достоверность этого правила больше порога minconf .
- Из результирующего списка правил удаляются все «неинтересные» правила.
Базовый алгоритм поиска часто встречающихся множеств
На первом шаге алгоритма подсчитываются 1-элементные часто встречающиеся наборы. При этом элементы могут находиться на любом уровне таксономии. Для этого необходимо «пройтись» по всему набору данных и подсчитать для них поддержку, т.е. сколько раз встречается в базе.
Следующие шаги будут состоять из двух частей: генерации потенциально часто встречающихся наборов элементов (их называют кандидатами) и подсчета поддержки для кандидатов.
Описанный выше алгоритм можно записать в виде следующего псевдокода:
- L_1 = \< Часто встречающиеся множества элементов и групп элементов \>;
- \text < для>(k=2, L_ \verb!<>! \varnothing, k\verb!++! )
- \
- C_k = \ < Генерация кандидатов мощностью \ k на основе \ L_\>
- для всех транзакций t∈D
- \
- Расширить транзакцию t предками всех элементов,
- входящих в транзакцию
- Удалить дубликаты из транзакции t
- для всех кандидатов c \in C_k
- \text c \subseteq t \text
- c.count\verb!++!
- \>
- L_k = [c \in C_k | c.count > = minsupp ] // Отбор кандидатов
- \>
- Результат = U_kL_k
Опишем функцию генерации кандидатов. Для того чтобы получить k -элементные наборы, воспользуемся (k-1) -элементными наборами, которые были определены на предыдущем шаге и являются часто встречающимися.
Алгоритм генерации кандидатов будет состоять из двух шагов:
Объединение. Каждый кандидат C_k будет формироваться путем расширения часто встречающегося набора (k-1) добавлением элемента из другого (k-1) -элементного набора. Приведем алгоритм этой функции в виде небольшого SQL-подобного запроса:
a.item_1, a.item_2, . a.item_, b.item_
Удаление избыточных правил. На основании свойства анти-монотонности, следует удалить все наборы c C_k , если хотя бы одно из его (k-1) подмножеств не является часто встречающимся.
Для эффективного подсчета поддержки кандидатов можно использовать хэш-дерево [5]. Хеш-дерево строится каждый раз, когда формируются кандидаты. Первоначально дерево состоит только из корня, который является листом, и не содержит никаких кандидатов-наборов.
Каждый раз, когда формируется новый кандидат, он заносится в корень дерева, и так до тех пор, пока количество кандидатов в корне-листе не превысит некоего порога.
Как только количество кандидатов становится больше порога, корень преобразуется в хеш-таблицу, т.е. становится внутренним узлом, и для него создаются потомки-листья. И все примеры распределяются по узлам-потомкам согласно хеш-значениям элементов, входящим в набор, и т.д. Каждый новый кандидат хешируется на внутренних узлах, пока он не достигнет первого узла-листа, где он и будет храниться, пока количество наборов опять же не превысит порога.
Улучшенный алгоритм поиска часто встречающихся множеств
К базовому алгоритму можно добавить несколько оптимизаций, которые увеличат скорость работы базового алгоритма:
- Целесообразно единожды вычислить множества предков для каждого элемента иерархии: как для элемента нижнего уровня таксономии (лист дерева), так и для элемента внутреннего уровня.
- Необходимо удалять кандидаты, содержащие элемент и его предок. Для реализации этой оптимизации рассмотрим следующие две леммы:
- Лемма 1. Поддержка множества X , содержащего и элемент x и его предок \underline вычисляется по формуле supp(X)=supp(X-\underline) . Принимая во внимание эту лемму, мы будем удалять кандидаты, содержащие и элемент и его предок из списка кандидатов до начала процесса подсчета поддержки. Лемма 2. Если L_k — это список часто встречающихся множеств, не содержащий множеств, включающих и элемент и его предок в одном множестве, то C_ (список кандидатов, получаемых из L_k ) также не будет содержать множеств, включающих и элемент и его предок. Учитывая утверждение, данное в этой лемме, мы будем удалять кандидатов, включающих и элемент и его предок, из списка кандидатов только на первой итерации внешнего цикла.
- Нет необходимости в добавлении всех предков всех элементов, входящих в транзакцию. Если какой-то элемент, у которого есть предок, не находится в списке кандидатов, то в списке элементов с предками он помечается как удаленный. Следовательно, из транзакции удаляются элементы, помеченные как удаленные, или производится замена этих элементов на их предков. К транзакции добавляются только не удаленные предки.
- Не «пропускать» транзакцию через хэш-дерево, если ее мощность меньше чем мощность элементов, расположенных в хэш-дереве.
- Целесообразно помечать транзакции как удаленные и не использовать их при подсчете поддержки на следующих итерациях, если на текущей итерации в эту транзакцию не вошел ни один кандидат.
Учитывая написанное выше, получаем следующий алгоритм:
- // Оптимизация 1
- Вычислить I* множества предков элементов для каждого элемента
- L_1 = \< Часто встречающиеся множества элементов и групп элементов \>;
- \text < для>(k=2, L_ \verb!<>! \varnothing, k\verb!++! )
- \
- C_k = \ < Генерация кандидатов мощностью \ k на основе \ L_\>
- // Оптимизация 2
- если k=2 то
- удалить те кандидаты из C_k , которые содержат элемент и его предок
- // Оптимизация 3
- Пометить как удаленные множества предков элемента, которые не содержатся в списке кандидатов
- для всех транзакций t \in D
- \
- // Оптимизация 3
- для каждого элемента x \in t
- добавить всех предков x из I* к t
- Удалить дубликаты из транзакции t
- // Оптимизация 4,5
- если ( t не помечена как удаленная) и ( |t|>=k ) то
- \
- для всех кандидатов c \in C_k
- если c \subseteq t то
- c.count\verb!++! ;
- // Оптимизация 5
- если в транзакцию t не вошел ни один кандидат то
- отметить эту транзакцию как удаленную;
- \>
- \>
- // Отбор кандидатов
- L_k = [c\in C_k | c.count = minsupp]
- \>
- Результат = U_k
Заключение
В данной статье был рассмотрен вопрос выявления обобщенных ассоциативных правил. Введение информации о группировке элементов транзакций позволило получать правила, в которых элементами являются как сами элементы транзакций, так и группы, в которые входят эти элементы. Также с вводом информации о группировке, появилась возможность отсечения «излишних» правил, для чего был введен такой параметр, как минимальный уровень интереса.
Появление такого инструмента, как алгоритм поиска обобщенных ассоциативных правил, значительно расширило круг задач, решаемых при помощи методов выявления стандартных шаблонов событий [3]. Примером может служить задача нахождения зависимостей между товарами, продаваемыми некой фирмой и ее покупателями. Цель такой задачи — это найти тех покупателей на конкретные товары (например, товары, которые «завалялись» на складе), которые их никогда не покупали, но покупали схожие.
- Акобир Шахиди, Введение в анализ ассоциативных правил, 2002.
- Акобир Шахиди, Apriori – масштабируемый алгоритм поиска ассоциативных правил, 2002.
- R. Srikant, R. Agrawal, Mining Generalized Association Rules, In Proc. of the 21st International Conference on VLDB, Zurich, Switzerland, 1995.
- J.S. Park, M.-S. Chen, and S.Y. Philip, An Effective HashBased Algorithm for Mining Association Rules, In Proc. ACM SIGMOD Int’l Conf. Management of Data, ACM Press, New York, 1995.
- R. Agrawal, R. Srikant, Fast algorithms for mining association rules, In Proc. of the VLDB Conference, Santiago, Chile, September 1994
Другие материалы по теме: