Hash processor
здрасьте здрасьте люди добрые. тут очнь крутые спецы в этом деле, поэтому хочу попросить вас помочь мне разобраться как работает Hash processor. он установлен у меня на MK. что он делает? если я дам ему навход, к примеру, «cde» то он навыходе выдаст просто 32bit слово и 8bit слово? в чем суть этого процессора?

Assembler ☆
15.07.22 23:55:57 MSK
- Ответить на это сообщение
- Ссылка
мне просто надо с чего-то начать но понимание совершенно отсутсвтует в этом деле. пожалуйста растолкуйне напальцах хотя бы
Assembler ☆
( 15.07.22 23:57:28 MSK ) автор топика
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от Assembler 15.07.22 23:57:28 MSK

Удали всё в шапке и напиши нормально. тык
Хеширует данные, а ты уже хеш используешь как тебе надо.
LINUX-ORG-RU ★★★★★
( 15.07.22 23:59:21 MSK )
Последнее исправление: LINUX-ORG-RU 16.07.22 00:02:06 MSK (всего исправлений: 3)
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от LINUX-ORG-RU 15.07.22 23:59:21 MSK
то есть после обработки данных этим процессором я на выходе получу уникальную строку?
Assembler ☆
( 16.07.22 00:05:57 MSK ) автор топика
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от Assembler 16.07.22 00:05:57 MSK
Ну типа, я вообще не в курсе что у тебя там за МК и что за Hash processor там в нём. Скачай даташит на свой МК и глянь там, всё должно быть написано.
LINUX-ORG-RU ★★★★★
( 16.07.22 01:00:05 MSK )
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от LINUX-ORG-RU 16.07.22 01:00:05 MSK
ну а вобще суть таких процессоров в этом? дать навыходе уникальную строку или как?
Assembler ☆
( 16.07.22 01:08:22 MSK ) автор топика
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от Assembler 16.07.22 01:08:22 MSK
ну а вобще суть таких процессоров в этом?
Cуть таких сопроцессоров аппаратно ускорять подобные тяжеловесные действия. Можешь программно хеш высчитывать, но тогда сам понимаешь что будет.
Ты википедию прочёл? Зачем нужны хеши? Пароли хранить в неявном виде, хеш суммы данных проверять на повреждение. Хеш таблицу сделать для быстрого поиска данных. Да, хеш подразумевает то что данным произвольной длинны и содержания будет соответствовать уникальная строка фиксированного размера.
Тебе нужна уникальная строка фиксированного размера для твоих данных? Если да то используй, если нет то забей. Применений может быть множество.
dron@gnu:~$ echo "Жопа" | shasum 0f3837689fd93285cdf9324c680c5eceb4534e78 - dron@gnu:~$ echo "Жопа!" | shasum 18ca01482121c27578d511d04edbac99d507b990 - dron@gnu:~$ echo "Жопа! Попа! Попка!" | shasum fb1277b3e73c3278a813b33213f3c73c0ebed2d2 - dron@gnu:~$ echo "Срака" | shasum b85d3224c71d086e6147dde05034e0fad9aadbbc - dron@gnu:~$ dron@gnu:~$ cat /boot/initrd.img-5.18.0-2-amd64 | shasum caaa4798f7d3b435a65111eb4ffbada44cb02010 - dron@gnu:~$ Ну и да уникальность тут в скобочках ибо существуют коллизии когда разные данных как по размеру так и по содержанию имеют одинаковую хеш сумму.
LINUX-ORG-RU ★★★★★
( 16.07.22 01:50:38 MSK )
Последнее исправление: LINUX-ORG-RU 16.07.22 01:52:32 MSK (всего исправлений: 1)
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от LINUX-ORG-RU 16.07.22 01:50:38 MSK
Cуть таких сопроцессоров аппаратно ускорять подобные тяжеловесные действия.
это я и хотел услышать. спасибо
Assembler ☆
( 16.07.22 01:52:58 MSK ) автор топика
- Ответить на это сообщение
- Ссылка
Intel Secure Hash Algorithm
(SHA)

Intel SHA (Secure Hash Algorithm extensions) — набор инструкций процессора, разработанных компанией Intel для ускорения работы приложений, используемых алгоритмы шифрования SHA. Включает 7 инструкций, 4 из которых ускоряют работу SHA-1, остальные 3 — SHA-256. Ускорение может составлять 150-200 % и более (в зависимости конкретного приложения).
SHA-1 — алгоритм криптографического хеширования, генерирующий 160-битное хеш-значение, называемое также дайджестом сообщения. Используется во многих криптографических приложениях и протоколах. Рекомендован в качестве основного для государственных учреждений в США. SHA-256, в отличие от SHA-1, генерирует 256-битный дайджест сообщения.
Эти алгоритмы используются в системах контроля версий и электронных подписей, а также для построения кодов аутентификации. SHA-1 является более распространённым и применяется в самых разнообразных криптографических программах.
В то же время, надежность SHA-1 поставлена под сомнение. Не так давно Google выразила своё недоверие SHA-1. В 2014 году группа разработчиков Google Chrome объявила о постепенном отказе от использования SHA-1. А с 2016 года Яндекс.Почта перестала поддерживать старые почтовые программы, использующие SHA-1.
ПОДЕЛИТЬСЯ:

НАПИСАТЬ АВТОРУ
Похожие материалы

Технологии и инструкции, используемые в процессорах
Люди обычно оценивают процессор по количеству ядер, тактовой частоте, объему кэша и других показателях, редко обращая внимание на поддерживаемые им технологии.
Отдельные из этих технологий нужны только для решения специфических заданий и в «домашнем» компьютере вряд ли когда-нибудь понадобятся. Наличие же других является непременным условием работы программ, необходимых для повседневного использования.
Так, полюбившийся многим браузер Google Chrome не работает без поддержки процессором SSE2. Инструкции AVX могут в разы ускорить обработку фото- и видеоконтента. А недавно один мой знакомый на достаточно быстром Phenom II (6 ядер) не смог запустить игру Mafia 3, поскольку его процессор не поддерживает инструкции SSE4.2.
Если аббревиатуры SSE, MMX, AVX, SIMD вам ни о чем не говорят и вы хотели бы разобраться в этом вопросе, изложенная здесь информация станет неплохим подспорьем.

Таблица совместимости процессоров и материнских плат AMD
Одной из особенностей компьютеров на базе процессоров AMD, которой они выгодно отличаются от платформ Intel, является высокий уровень совместимости процессоров и материнских плат. У владельцев относительно не старых настольных систем на базе AMD есть высокие шансы безболезненно «прокачать» компьютер путем простой замены процессора на «камень» из более новой линейки или же флагман из предыдущей.
Если вы принадлежите к их числу и задались вопросом «апгрейда», эта небольшая табличка вам в помощь.

Сравнение процессоров
В таблицу можно одновременно добавить до 6 процессоров, выбрав их из списка (кнопка «Добавить процессор»). Всего доступно больше 2,5 тыс. процессоров Intel и AMD.
Пользователю предоставляется возможность в удобной форме сравнивать производительность процессоров в синтетических тестах, количество ядер, частоту, структуру и объем кэша, поддерживаемые типы оперативной памяти, скорость шины, а также другие их характеристики.
Дополнительные рекомендации по использованию таблицы можно найти внизу страницы.

Спецификации процессоров
В этой базе собраны подробные характеристики процессоров Intel и AMD. Она содержит спецификации около 2,7 тысяч десктопных, мобильных и серверных процессоров, начиная с первых Пентиумов и Атлонов и заканчивая последними моделями.
Информация систематизирована в алфавитном порядке и будет полезна всем, кто интересуется компьютерной техникой.

Таблица процессоров
Таблица содержит информацию о почти 2 тыс. процессоров и будет весьма полезной людям, интересующимся компьютерным «железом». Положение каждого процессора в таблице определяется уровнем его быстродействия в синтетических тестах (расположены по убыванию).
Есть фильтр, отбирающий процессоры по производителю, модели, сокету, количеству ядер, наличию встроенного видеоядра и другим параметрам.
Для получения подробной информации о любом процессоре достаточно нажать на его название.

Как проверить стабильность процессора
Проверка стабильности работы центрального процессора требуется не часто. Как правило, такая необходимость возникает при приобретении компьютера, разгоне процессора (оверлокинге), при возникновении сбоев в работе компьютера, а также в некоторых других случаях.
В статье описан порядок проверки процессора при помощи программы Prime95, которая, по мнению многих экспертов и оверлокеров, является лучшим средством для этих целей.

ПОКАЗАТЬ ЕЩЕ
Хеш+кэш: оптимизация «потоковой» обработки
Что делать, если в базу хочется записать массу «фактов» много большего объема, чем она способна выдержать? Сначала, конечно, приводим данные к более экономичной нормальной форме и получаем «словари», в которые будем писать однократно. Но как это делать наиболее эффективно?
Именно с таким вопросом мы столкнулись при разработке мониторинга и анализа логов серверов PostgreSQL, когда остальные способы оптимизации записи в БД оказались исчерпаны.
Сразу оговоримся, что наши коллекторы работают под управлением Node.js, поэтому с процессорными регистрами и кэшами мы никак не взаимодействуем. А вариант использования «стораджей» или внешних кэширующих сервисов/БД дает слишком большие задержки при входящих потоках в несколько сотен Mbps.
Поэтому мы стараемся кэшировать все в RAM, конкретно — в памяти JavaScript-процесса. Про то, как эффективнее это организовать, и пойдет речь дальше.
Кэширование наличия
Наша основная задача — сделать так, чтобы в БД попал по возможности единственный экземпляр какого-либо объекта. Такими у нас выступают многократно повторяющиеся оригинальные тексты SQL-запросов, шаблоны планов их выполнения, узлов этих планов — короче, какие-то текстовые блоки.
Исторически так сложилось, что в качестве идентификатора мы использовали UUID -значение, которое получали в результате прямого вычисления MD5-хеша от текста объекта. После этого проверяем наличие такого хеша в локальном «словаре» в памяти процесса, и вот если его там нет — только тогда пишем в БД в «словарную» таблицу.
То есть само оригинальное текстовое значение нам хранить не требуется (а иногда оно занимает десятки килобайт) — достаточно всего лишь самого факта наличия соответствующего хеша в словаре.
Словарь ключей
Такой словарь можно вести в Array , и использовать Array.includes() для проверки наличия, но это достаточно избыточно — поиск деградирует (по крайней мере, в предыдущих версиях V8) линейно от размера массива, O(N). Да и в современных реализациях, несмотря на все оптимизации, проигрывает по скорости 2-3%.
Поэтому в эпоху до ES6 традиционным решением было хранение Object , ключами которого выступали хранимые значения. А вот значениями ключей каждый назначал что хотел — например, Boolean :
var dict = <>; function has(key) < return dict[key] !== undefined; >function add(key)
Но вполне очевидно, что мы тут явно храним лишнее — то самое значение ключа, которое никому не нужно. А что если его — вообще не хранить? Так и появился объект Set.
Тесты показывают, что поиск с помощью Set.has() быстрее примерно на 20-25%, чем проверка ключа в Object . Но это не единственное его преимущество. Раз мы храним меньше, то и памяти нам должно требоваться меньше — а это впрямую сказывается на производительности, когда речь идет о сотнях тысяч таких ключей.
Итак, Object , в котором находится 100 UUID-ключей в текстовом представлении, занимает в памяти 6216 байт:

Set с тем же содержимым — 2632 байта:
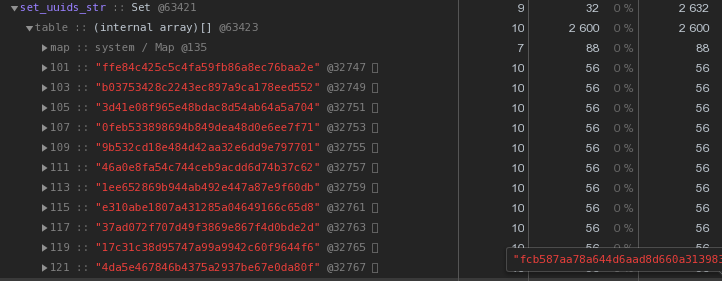
То есть Set работает быстрее и при этом занимает в 2.5 раза меньше памяти — победитель очевиден.
Оптимизируем хранение UUID-ключей
Вообще, в природе распределенных систем UUID-ключи достаточно распространены — у нас в СБИСе они, как минимум, применяются для идентификации документов и регламентов в электронном документообороте, персон в обмене сообщениями,…
Давайте теперь еще раз внимательно посмотрим на картинку выше — каждый UUID-ключ, хранимый в hex-представлении, «стоит» нам 56 байт памяти. Но у нас их — сотни тысяч, поэтому резонно спросить: «А меньше — можно?»
Для начала вспомним, что UUID — это 16-байтовый идентификатор. По сути, кусок бинарных данных. А для передачи по email, например, двоичные данные кодируются в base64 — попробуем его применить:
let str = Buffer.from(uuidstr, 'hex').toString('base64');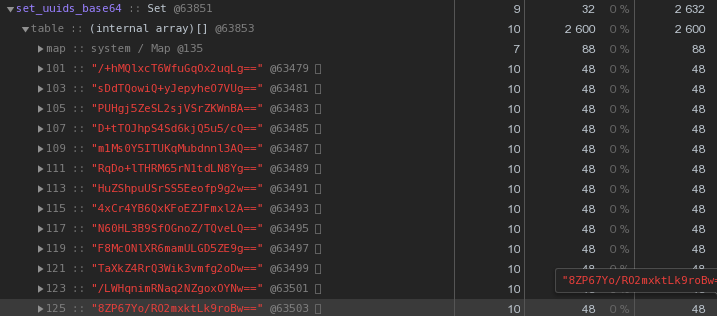
Уже по 48 байт — лучше, но неидеально. Давайте попробуем перевести шестнадцатиричное представление прямо в строку:
let str = Buffer.from(uuidstr, 'hex').toString('binary');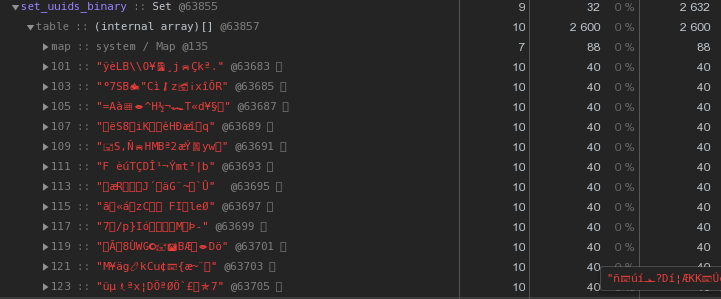
Вместо 56 байт на каждый ключ — 40 байт, экономия почти 30%!
Master, worker — где хранить словари?
Учитывая, что словарные данные от воркеров достаточно сильно пересекаются, мы сделали хранение словарей и запись их в БД в мастер-процессе, а передачу данных от воркеров через механизм IPC-сообщений.
Однако существенная доля времени мастера тратилась на channel.onread — то есть на обработку получения пакетов со «словарной» информацией от дочерних процессов:
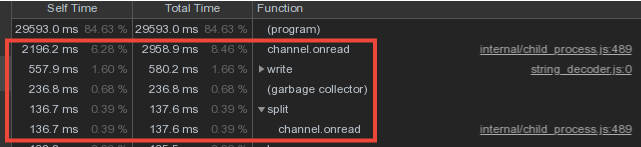
Двойной Set-барьер от записи
Теперь на секунду задумаемся — воркеры шлют и шлют мастеру одни и те же словарные данные (в основном — это шаблоны планов и повторяющиеся тела запросов), он их в поте лица парсит и… ничего не делает, потому что они в БД уже были отправлены раньше!
Так если мы Set -словариком «защитили» базу от повторной записи из мастера, почему бы не применить тот же подход для «защиты» мастера от передачи из воркера.
Собственно, что и было сделано, и сократило втрое прямые издержки на обслуживание канала обмена:

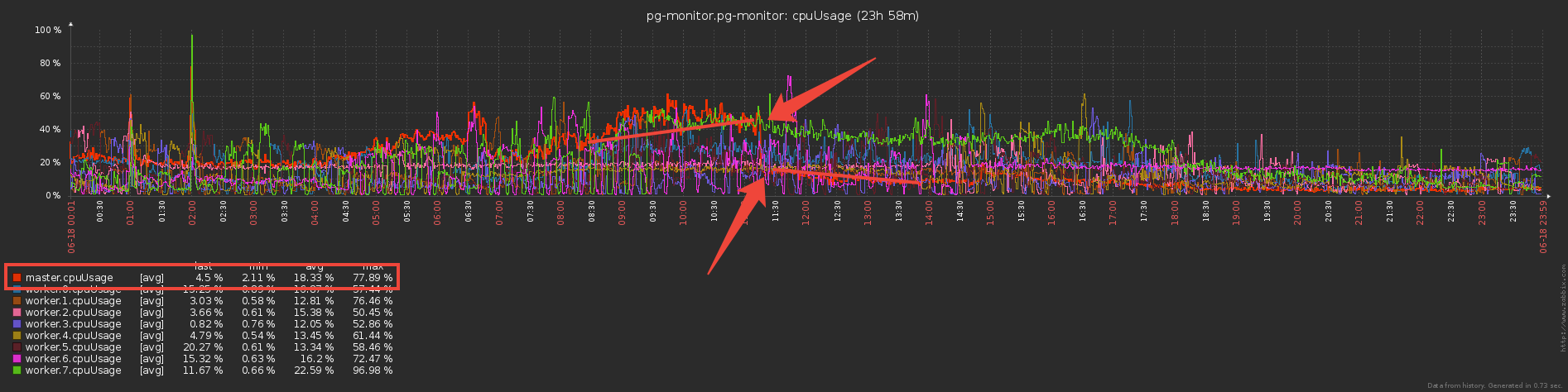
Но ведь теперь воркеры делают вроде как больше работы — хранят словари и фильтруют по ним? Или нет. На самом деле, работать они стали существенно меньше, поскольку сама передача больших объемов (даже по IPC!) — это не дешево.
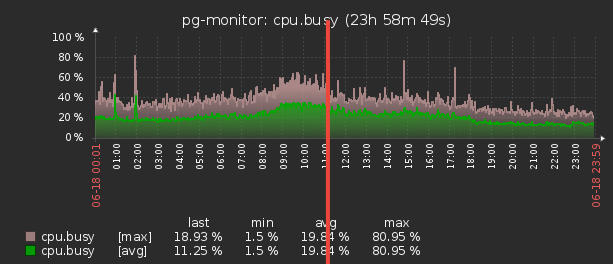
Приятный бонус
Поскольку мастер теперь стал принимать гораздо меньший объем информации, то и памяти под эти контейнеры стал выделять гораздо меньше — а, значит, затраты времени на работу Garbage Collector’а сильно снизились, что положительно повлияло на latency системы в целом.
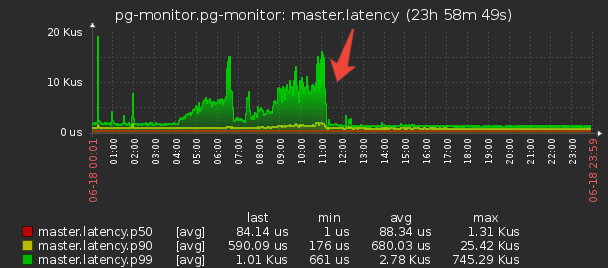
Такая схема обеспечивает защиту от повторных записей на уровне коллектора, но что делать, если у нас несколько коллекторов? Тут поможет только триггер с INSERT . ON CONFLICT DO NOTHING .
Ускоряем вычисление хешей
В нашей архитектуре весь поток логов с одного сервера PostgreSQL обрабатывает один воркер.
То есть один сервер — это одна задача на воркере. При этом загрузка воркеров балансируется назначением задач-серверов так чтобы потребление CPU воркерами всех коллекторов было примерно одинаковым. Этим занимается отдельный сервис диспетчера.
«В среднем» каждый воркер обрабатывает несколько десятков задач, которые дают примерно одинаковую суммарную нагрузку. Однако, есть сервера, которые по количеству записей в логе значительно превосходят остальные. И даже в том случае, если диспетчер оставляет эту задачу единственной на воркере, его загрузка сильно выше остальных:

Сняли CPU-профайл этого воркера:

На верхних строках — вычисление MD5-хешей. А их действительно вычисляется огромное количество — для всего потока входящих объектов.
xxHash
Как оптимизировать эту часть, если не считать эти хеши мы не можем?
Решили попробовать другую хеш-функцию — xxHash, реализующую Extremely fast non-cryptographic hash algorithm. И модуль для Node.js — xxhash-addon, который использует свежую версию библиотеки xxHash 0.7.3 с новым алгоритмом XXH3.
Проверим, прогнав каждый вариант на наборе строк разной длины:
const crypto = require('crypto'); const < XXHash3, XXHash64 >= require('xxhash-addon'); const hasher3 = new XXHash3(0xDEADBEAF); const hasher64 = new XXHash64(0xDEADBEAF); const buf = Buffer.allocUnsafe(16); const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary'); const funcs = < xxhash64 : (str) =>hasher64.hash(Buffer.from(str)).toString('binary') , xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary') , md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex')) >; const check = (hash) => < let log = []; let cnt = 10000; while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex')); console.time(hash); log.forEach(funcs[hash]); console.timeEnd(hash); >; Object.keys(funcs).forEach(check); Результаты:
xxhash64 : 148.268ms xxhash3 : 108.337ms md5 : 317.584ms Как и ожидалось, xxhash3 оказался намного быстрее MD5!
Осталось проверить на стойкость к коллизиям. Секции таблиц словарей у нас создаются новые на каждый день, поэтому за рамками суток мы спокойно можем допустить пересечение хешей.
Но на всякий случай проверили с запасом на интервале в три дня — ни одной коллизии, что нас более чем устраивает.
Подмена хешей

Но просто взять и поменять в таблицах-словарях старые UUID-поля на новый хеш мы не можем — ведь и база, и существующий frontend ждут, что объекты продолжат идентифицироваться по UUID.
Поэтому добавим в коллекторе еще один кэш — для уже посчитанных MD5. Теперь это будет Map, в котором ключи — xxhash3, значения — MD5. Для одинаковых строк мы не пересчитываем заново «дорогой» MD5, а берем его из кэша:
const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex'); const dictmd5 = new Map(); const getmd5 = (data) => < const hash = xxhash(data); let md5hash = dictmd5.get(hash); if (!md5hash) < md5hash = md5(data); dictmd5.set(hash, getBinFromHash(md5hash)); return md5hash; >return getHashFromBin(md5hash); >; Снимаем профайл — доля времени вычисления хешей заметно снизилась, ура!

Так что теперь мы считаем xxhash3, затем проверяем кэш MD5 и получаем искомый MD5, а затем проверяем кэш словаря — если там этого md5 нет, то отправляем на запись в БД.
Что-то слишком много проверок… Зачем проверять кэш словаря, если уже проверили кэш MD5? Выходит, все кэши словарей теперь не нужны и достаточно иметь всего один кэш — для MD5, с которым и будут производиться все основные операции:

В итоге, мы заменили проверку в нескольких кэшах «объектных» словарей одним кэшем MD5, а ресурсоемкую операцию расчета MD5-хеша выполняем только для новых записей, используя для входящего потока гораздо более эффективный xxhash.
Спасибо Kilor за помощь в подготовке статьи.
- Блог компании Тензор
- Высокая производительность
- JavaScript
- Серверная оптимизация
- Node.JS
Cpu hash что это
Тема для обсуждения платформ.
А процессоры будем выбирать здесь : Выбор процессора. Часть III
Начало темы здесь — INTEL или AMD: Выбор Платформы. (начало)
Последний раз редактировалось Keper; 02.03.2011 в 23:01 . Причина: для объявления
| Меню пользователя Щукинсын |
| Посмотреть профиль |
| Найти ещё сообщения от Щукинсын |
Абсолютный
Регистрация: 08.04.2009
Сейчас с BIOS немного поигрался, обнаружил интересный момент в тесте CPU Hash
__________________
Под косматой елью, в темном подземелье,
Где рождается родник, — меж корней живет старик.
| Меню пользователя BSE |
| Посмотреть профиль |
| Найти ещё сообщения от BSE |
Экс-модератор
Регистрация: 08.07.2004
Адрес: Москва
обнаружил интересный момент в тесте CPU Hash
давай в CPU Queen такой же интересный момент обнаружь
Так то тест очень сильно зависит от частоты-таймингов. У тебя почти 1000 при 5-6-6, а у 990-го 1333 9-9-9 — а это очень уныло однако. Посмотри кто выше тебя по результату — i5400, а это (если мне не изменяет гугл) socket 771.
| Меню пользователя vow |
| Посмотреть профиль |
| Посетить домашнюю страницу vow |
| Найти ещё сообщения от vow |
Абсолютный
Регистрация: 08.04.2009
vow, если обратить внимание, то результаты ~ 1Мб на 1МГц что у моего, что у эталонного 1055T (а у него те же 9-9-9-24).
Добавлено через 12 минут
Увеличил сейчас частоту до 3500МГц, а результат стал 3493Мб/с.
Добавлено через 14 минут
Причём по работе с памятью более чем в два раза медленнее 2600-ого и 990-ого.
Добавлено через 20 минут
Сейчас прогнал тест, снизив частоту памяти до 667МГц, при этом получил такой же результат: 3493Мб/с.
__________________
Под косматой елью, в темном подземелье,
Где рождается родник, — меж корней живет старик.
| Меню пользователя BSE |
| Посмотреть профиль |
| Найти ещё сообщения от BSE |
Абсолютный
Регистрация: 08.04.2009
И опять же насчёт «влияния» памяти: на частоте 2800МГц мой процессор (5-6-6-18 CR2 800) выдал 2795Мб/с против 2809Мб/с (9-9-9-24 CR1 1333) у эталонного. Если какое влияние и есть, то отрицательное (у меня подсистема памяти не очень быстрая).
Добавлено через 2 минуты
Посмотри кто выше тебя по результату — i5400, а это (если мне не изменяет гугл) socket 771.
Здесь больше влияние 8-ми ядер, не?
__________________
Под косматой елью, в темном подземелье,
Где рождается родник, — меж корней живет старик.
| Меню пользователя BSE |
| Посмотреть профиль |
| Найти ещё сообщения от BSE |